- CPU与GPU
- 数据迁移至GPU
- 多GPU并行运算
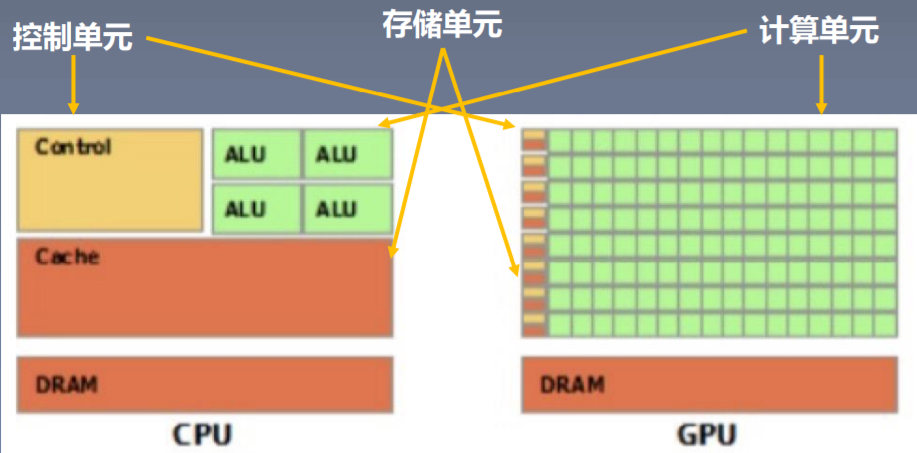
GPU 与CPU
- CPU(Central Processing Unit, 中央处理器):主要包括控制器和运算器
- GPU(Graphics Processing Unit, 图形处理器):处理统一的,无依赖的大规模数据运算
数据迁移
数据必须在同一处理器,才能被处理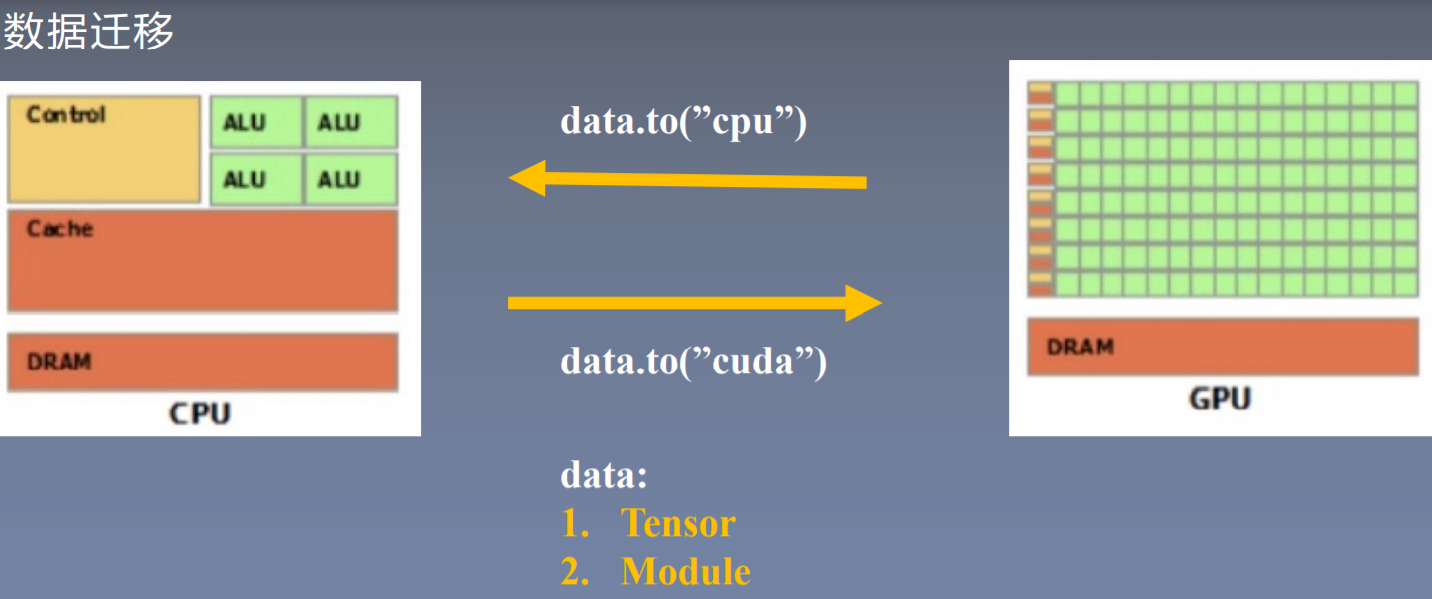
to函数
- 转换数据类型/设备
- tensor.to(args, *kwargs)
- module.to(args, *kwargs)
区别:张量不执行inplace,模型执行inplace
x = torch.ones((3, 3))x = x.to(torch.float64) # float32 -> float64x = torch.ones((3, 3))x = x.to("cuda") # 数据迁移cpu -> cudalinear = nn.Linear(2, 2)linear.to(torch.double)gpu1 = torch.device("cuda")linear.to(gpu1) # module cpu -> cuda
import torchimport torch.nn as nndevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# ========================== 02_tensor to cuda ========================== ## flag = 0flag = 1if flag:x_cpu = torch.ones((3, 3))print("x_cpu:\ndevice: {} is_cuda: {} id: {}".format(x_cpu.device, x_cpu.is_cuda, id(x_cpu)))x_gpu = x_cpu.to(device)print("x_gpu:\ndevice: {} is_cuda: {} id: {}".format(x_gpu.device, x_gpu.is_cuda, id(x_gpu)))# 弃用# x_gpu = x_cpu.cuda() # 0.4.0之前的方法# ========================== module to cuda ========================== ## flag = 0flag = 1if flag:net = nn.Sequential(nn.Linear(3, 3))print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))net.to(device)# 内存地址不变print("\nid:{} is_cuda: {}".format(id(net), next(net.parameters()).is_cuda))# ========================== forward in cuda ========================== ## flag = 0flag = 1if flag:output = net(x_gpu)print("output is_cuda: {}".format(output.is_cuda))# output = net(x_cpu) # 程序报错,数据在CPU上,模型在GPU上# ========================== 查看当前gpu 序号,尝试修改可见gpu,以及主gpu ========================== #flag = 0# flag = 1if flag:current_device = torch.cuda.current_device()print("current_device: ", current_device)torch.cuda.set_device(0)current_device = torch.cuda.current_device()print("current_device: ", current_device)#cap = torch.cuda.get_device_capability(device=None)print(cap)#name = torch.cuda.get_device_name()print(name)is_available = torch.cuda.is_available()print(is_available)# ===================== seed ========================== #seed = 2torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)current_seed = torch.cuda.initial_seed()print(current_seed)s = torch.cuda.seed()s_all = torch.cuda.seed_all()
torch.cuda常用方法
- torch.cuda.device_count():计算当前可见可用gpu数
- torch.cuda.get_device_name():获取gpu名称
- torch.cuda.manual_seed():为当前gpu设置随机种子
- torch.cuda.manual_seed_all():为所有可见可用gpu设置随机种子
- torch.cuda.set_device():设置主gpu为哪一个物理gpu(不推荐)
- 推荐: os.environ.setdefault(“CUDA_VISIBLE_DEVICES”, “2, 3”)
**
我们首先要理解什么叫物理GPU,什么叫逻辑GPU。
- 物理GPU:实实在在插在我们的主机上的显卡
- 逻辑GPU:是python脚本当中可见的那些gpu。逻辑GPU的数量一定是小于等于物理GPU的数量。
那么应该如何去理解黄色代码所设置的2号3号GPU呢?这里我们知道物理GPU是永远不会变的,逻辑GPU会变。这里我们设置2和3是可见的。因此我们的逻辑GPU中只有两个gpu,所以逻辑GPU中后面的GPU2 、GPU3两个gpu就不存在了。此时逻辑GPU只有GPU0和GPU1。逻辑GPU0对应物理GPU中的2号,逻辑GPU1对应物理GPU3。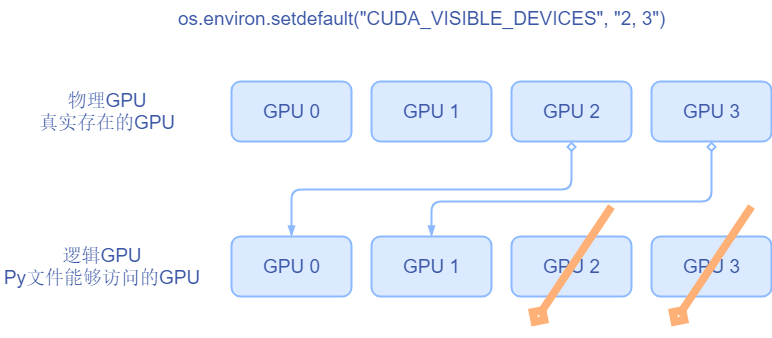
假如现在我们设置如下代码,我们来思考逻辑GPU又是怎么对应的。
os.environ.setdefault("CUDA_VISIBLE_DEVICES", "0, 3, 2")
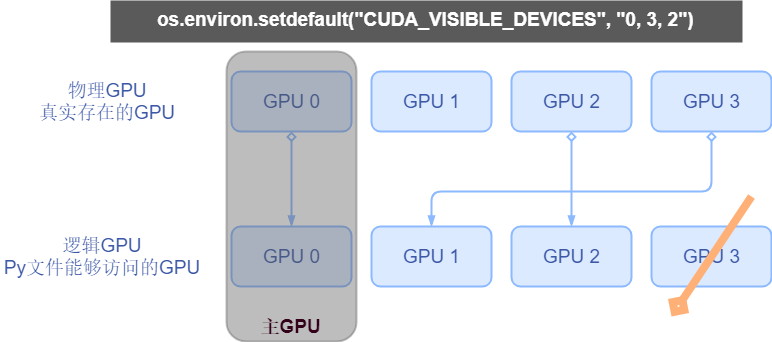
分配过程如图所示。我们为什么要这样煞费苦心的去设置这一个环境变量呢?可以灵活的分配GPU资源。在逻辑GPU当中我们通常有一个主gpu的概念,通常呢我们默认为第0个gpu他就是主gpu。
为什么要跟提总GPU这个概念呢?这与多GPU的运算的分发背景有关。下面我们就来学习拍拓展当中的。
多GPU并行运算
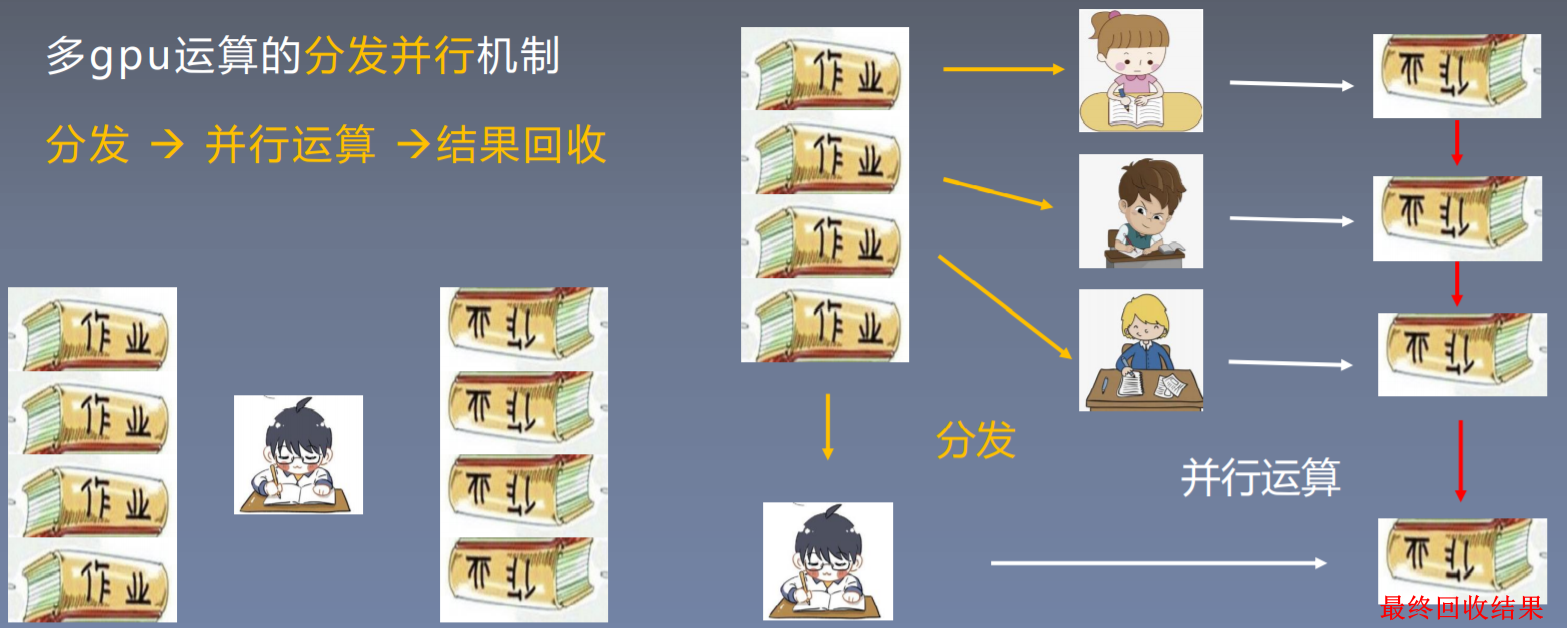
以小明做作业为例:
假设一个小朋友做一份作业需要60min,一共4分作业,总共需要240min才能完成。
如果他找其他三个小伙伴帮忙做作业,找到这些小伙伴需要3min,在平均分发给小伙伴做作业。当所有作业完成之后,小明需要对所有作业进行回收审核,回收审核需要话费3min时间。所以总共花费3 + 60 + 3 = 66min就可以完成全部作业。
torch.nn.DataParallel()
torch.nn.DataParallel(module,device_ids=None,output_device=None,dim=0)
- 功能:包装模型,实现分发并行机制
- 主要参数:
module: 需要包装分发的模型device_ids: 可分发的gpu,默认分发到所有可见可用gpuoutput_device: 结果输出设备

查询当前gpu内存剩余
def get_gpu_memory():import osos.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]os.system('rm tmp.txt')return memory_gpu
# example:gpu_memory = get_gpu_memory()gpu_list = np.argsort(gpu_memory)[::-1] # 排序gpu_list_str = ','.join(map(str, gpu_list))os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)print("\ngpu free memory: {}".format(gpu_memory))print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))## 输出# gpu free memory: [10362, 10058, 9990, 9990]# CUDA_VISIBLE_DEVICES: 0,1,3,2
# -*- coding: utf-8 -*-import osimport numpy as npimport torchimport torch.nn as nn# ============================ 手动选择gpu# flag = 0flag = 1if flag:gpu_list = [0]gpu_list = [0, 1, 2, 3]gpu_list_str = ','.join(map(str, gpu_list))os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# ============================ 依内存情况自动选择主gpu# flag = 0flag = 1if flag:def get_gpu_memory():import platformif 'Windows' != platform.system():import osos.system('nvidia-smi -q -d Memory | grep -A4 GPU | grep Free > tmp.txt')memory_gpu = [int(x.split()[2]) for x in open('tmp.txt', 'r').readlines()]os.system('rm tmp.txt')else:memory_gpu = Falseprint("显存计算功能暂不支持windows操作系统")return memory_gpugpu_memory = get_gpu_memory()if not gpu_memory:print("\n14_gpu_use free memory: {}".format(gpu_memory))gpu_list = np.argsort(gpu_memory)[::-1]gpu_list_str = ','.join(map(str, gpu_list))os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)device = torch.device("cuda" if torch.cuda.is_available() else "cpu")class FooNet(nn.Module):def __init__(self, neural_num, layers=3):super(FooNet, self).__init__()self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])def forward(self, x):print("\nbatch size in forward: {}".format(x.size()[0]))for (i, linear) in enumerate(self.linears):x = linear(x)x = torch.relu(x)return xif __name__ == "__main__":batch_size = 16# datainputs = torch.randn(batch_size, 3)labels = torch.randn(batch_size, 3)inputs, labels = inputs.to(device), labels.to(device)# modelnet = FooNet(neural_num=3, layers=3)net = nn.DataParallel(net) # 多GPU分发net.to(device)# trainingfor epoch in range(1):outputs = net(inputs)print("model outputs.size: {}".format(outputs.size()))print("CUDA_VISIBLE_DEVICES :{}".format(os.environ["CUDA_VISIBLE_DEVICES"]))print("device_count :{}".format(torch.cuda.device_count()))
gpu模型加载报错
报错一
RuntimeError: Attempting to deserialize object on a CUDA device but torch.cuda.is_available() is False. If you are running on a CPU -only machine, please use torch.load with map_location=torch.device('cpu') to map your storages to the CPU.
在GPU上训练并保存模型之后,然后将该模型放到CPU的机器上加载,会报错
解决:
torch.load(path_state_dict, map_location="cpu") # 将map_location 设置为CPU
报错二
RuntimeError: Error(s) in loading state_dict for FooNet: Missing key(s) in state_dict: "linears.0.weight", "linears.1.weight", "linears.2.weight". Unexpected key(s) in state_dict: "module.linears.0.weight", "module.linears.1.weight", "module.linears.2.weight".
多GPU并行运算训练之后,模型被 DataParallel 进行包装,使得模型的网络层命名会多一个 module 前缀。所以导致加载 state_dict 的时候,导致字典的 keys 不匹配,所以报错 Missing key(s)
解决:
from collections import OrderedDict
new_state_dict = OrderedDict() # 构建新的OrderDict
for k, v in state_dict_load.items():
namekey = k[7:] if k.startswith('module.') else k
new_state_dict[namekey] = v
import os
import numpy as np
import torch
import torch.nn as nn
class FooNet(nn.Module):
def __init__(self, neural_num, layers=3):
super(FooNet, self).__init__()
self.linears = nn.ModuleList([nn.Linear(neural_num, neural_num, bias=False) for i in range(layers)])
def forward(self, x):
print("\nbatch size in forward: {}".format(x.size()[0]))
for (i, linear) in enumerate(self.linears):
x = linear(x)
x = torch.relu(x)
return x
# =================================== 加载至cpu
flag = 0
# flag = 1
if flag:
gpu_list = [0]
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = FooNet(neural_num=3, layers=3)
net.to(device)
# save
net_state_dict = net.state_dict()
path_state_dict = "./model_in_gpu_0.pkl"
torch.save(net_state_dict, path_state_dict)
# load
# state_dict_load = torch.load(path_state_dict)
state_dict_load = torch.load(path_state_dict, map_location="cpu")
print("state_dict_load:\n{}".format(state_dict_load))
# =================================== 多gpu 保存
flag = 0
# flag = 1
if flag:
if torch.cuda.device_count() < 2:
print("gpu数量不足,请到多gpu环境下运行")
import sys
sys.exit(0)
gpu_list = [0, 1, 2, 3]
gpu_list_str = ','.join(map(str, gpu_list))
os.environ.setdefault("CUDA_VISIBLE_DEVICES", gpu_list_str)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
net = FooNet(neural_num=3, layers=3)
net = nn.DataParallel(net)
net.to(device)
# save
net_state_dict = net.state_dict()
path_state_dict = "./model_in_multi_gpu.pkl"
torch.save(net_state_dict, path_state_dict)
# =================================== 多gpu 加载
# flag = 0
flag = 1
if flag:
net = FooNet(neural_num=3, layers=3)
path_state_dict = "./model_in_multi_gpu.pkl"
state_dict_load = torch.load(path_state_dict, map_location="cpu")
print("state_dict_load:\n{}".format(state_dict_load))
# net.load_state_dict(state_dict_load)
# remove module.
from collections import OrderedDict
new_state_dict = OrderedDict()
for k, v in state_dict_load.items():
namekey = k[7:] if k.startswith('module.') else k
new_state_dict[namekey] = v
print("new_state_dict:\n{}".format(new_state_dict))
net.load_state_dict(new_state_dict)
# 使用特定的
CUDA_VISIBLE_DEVICES=2 python training.py
补充:
这里需要说明的是,device定义中的cuda:0可以不变,无论你多卡的GPU如何选取。device_ids=[0,1,2,3]也相对固定,如果有两张卡就定义device_ids=[0,1],如果有八张卡就定义device_ids=[0,1,2,3,4,5,6,7]。在多卡并行时,会有一个相对的主卡,就是cuda:0所指向的GPU。介绍到主卡就得引入os.environ[“CUDA_VISIBLE_DEVICES”] = “0,1,2,3”,在这里主卡是0卡。如果定义为cuda:1,os.environ[“CUDA_VISIBLE_DEVICES”] = “1,2,3”,这里主卡是2卡。
提示:需要注意的是device_ids中包含的卡数要和os.environ[“CUDA_VISIBLE_DEVICES”]中包含的卡数相等。这里的卡数是指数量,无需具体卡号一一对应,此外,batch_size的数量需要大于GPU的数量。
OK,最核心的部分给大家介绍完了,剩下的工作就是将之前单卡运行时的所有.cuda()替换为.to(device)即可。

若有收获,就点个赞吧
0 人点赞
