- Transfer Learning & Model Finetune
- PyTorch中的Finetune
一、迁移学习
Transfer Learning:机器学习分支,研究源域(source domain)的知识如何应用到目标域(target domain)
我们在训练一个深度学习模型的时候,经常会听到拿到一个预训练模型进行迁移学习,进行finetune。那么我们模型的微调与迁移学习之间到底是什么关系呢?
首先我们来了解一下迁移学习,它是机器学习下的一个分支,它主要研究源域的知识如何应用到目标域当中。从这里我们知道迁移学习其实他是一个很大的概念。那么我们怎么理解源域中的知识应用到目标域当中呢?
我们来看一个示意图,左边是一个传统的机器学习任务的一个学习过程。传统ML中,对不同的任务分别进行训练,得到三个Learning System,我们称之为模型。这里三个不同任务就会得到三个不同的这个模型。然后迁移学习是怎么样的呢?
我们看到右边的示意图。在右图中,分为South Tasks源任务、Target Task目标任务。这两个任务之间有一定的关联。左边我们对原任务在进行学习,这里我们学习到的称之为Knowledge。而在右边我们的目标任务里,会利用在源任务里学习到了Knowledge进行训练,得到Learning System的这一个模型。这一个过程就是迁移学习的过程。我们看到这个模型的训练不仅用到了我们的target task的数据,还用到了源任务中的Knowledge。这就是一个迁移学习是研究的问题。我们将源任务所学习到知识,应用到目标任务当中,用来提升在目标任务里模型的性能。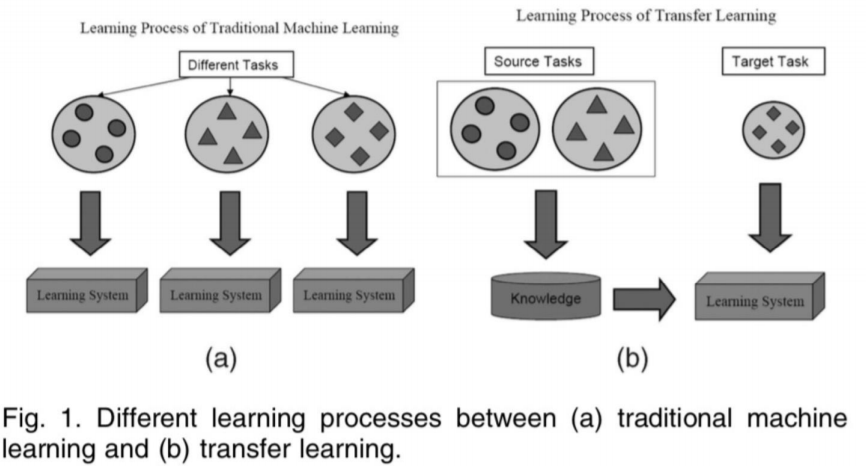
《A Survey on Transfer Learning》
二、模型微调
Model Finetune:模型的迁移学习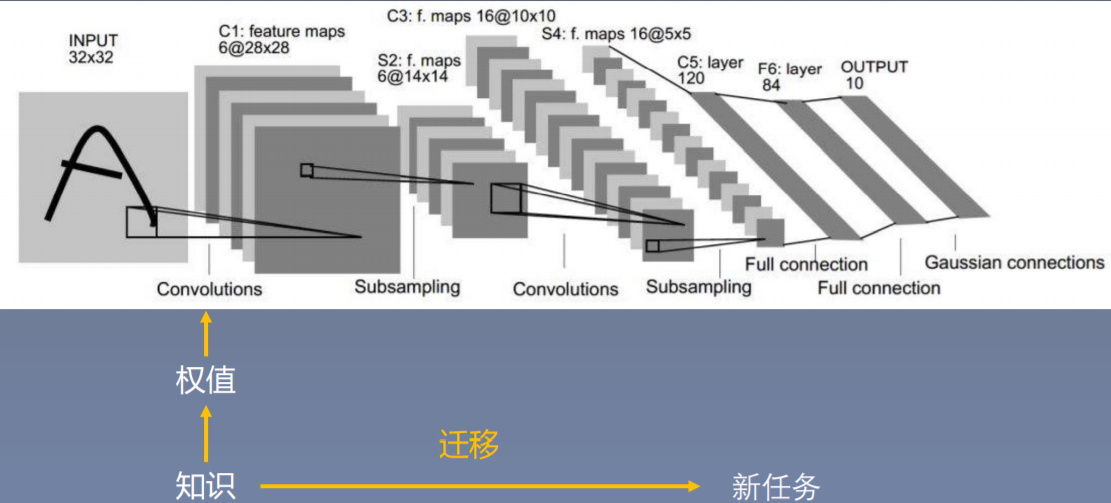
《 How transfer-able are features in deep neural networks?》
**
深度学习模型训练过程当中的模型微调与迁移学习之间的关系。我们知道训练一个模型就是不断的去更新权值。而整个模型的最重要的东西就是权值,我们就可以称之为知识。我们在之前的可视化学习中,将AlexNet中的一个卷积层的卷积核进行可视化,发现卷积核都呈现出图像的边缘信息、或者色彩信息。这些信息就是AlexNet在ImageNet数据集上学习到的知识,可以把这些权值理解为神经网络在特定数据集上学习到的知识。这些知识是可以进行迁移的,将知识用到新的任务当中,这样就完成了一个transfer Learning,这就是模型微调。
将权值认为是知识,将我们原任务的知识应用到新任务当中,这就是transfer learning。
为什么我们需要采用模型微调这一trick呢,这是由于在新任务当中,我们的数据量比较小,不足以去训练一个较大的模型。因此我们就可以采用模型微调的方式来辅助我们在新任务当中去训练一个较好的模型,让我们训练过程更快。这就类比于一个人,如果他学会了骑自行车再去学骑电动车,这样他就学的比较快。这就是知识迁移。那么我们具体来看,我们的神经网络该如何去迁移呢?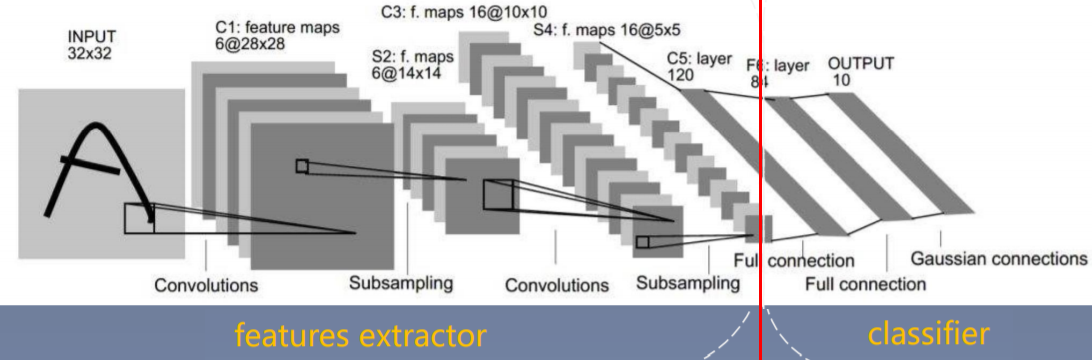 **
**
我们对一个分类任务通常会划分为两个部分:
- 特征提取器:由一系列的卷积池化层组成,通过特征提取器得到feature map,这些特征图就是特征。
- 分类器:全连接层被称为分类器。
这样我们就将一个卷积神经网络东西是两个部分,一部分是特征提取,一部分是是分类器。在特征提取部分中,我们会对这一系列的参数进行一个分析,分析哪一些参数和我们的目标任务是有共性的,哪一些参数为了适应目标任务需要改变呢。
这个时候就会对神经网络参数也会进行一个划分。我们认为特征提取器是非常有共性的地方,可以原封不动的进行迁移。而对于分类器部分,最后一层输出层的单元个数与具体的目标任务有关,需要去改变、去适应我们新任务。
模型微调的一个基本流程:对有共性的地方原封不动的保留,进行迁移;然后将输出层修改为适用于我们新的任务。
三、模型微调步骤
**
模型微调步骤:
- 获取预训练模型参数,源任务中学习到的知识,
- 加载模型(load_state_dict),将源任务学习到的知识加载到新任务的网络中。
- 修改输出层
构建好需要微调的模型的模型之后,在训练过程中也需要一些tricks:
模型微调训练方法:
- 固定预训练的参数
(requires_grad = False;lr=0) - Features Extractor较小学习率(params_group)
我们有时候会固定这一个特征提取部分,也就是一系列卷积层的参数,这些参数不会进行训练。这是因为新任务的训练数据量比较小,我们不足以去训练这么多的参数。同时我们也可以认为前面这些特征提取的部分的参数是有共性的,所以我们可以固定这些参数,让这些参数不更新。
要想达到以上目的,PyTorch当中提供了两种方法:
- 设置这些参数的
requires_grad设置为False,这些参数不需要去计算梯度,也不会再去更新了。对这些参数的学习率设置为0,所以这样参数也不会去更新,这就完成了参数的固定。 - 将特征提取部分的参数设置较小的学习率。而在分类器部分的学习率可以比较大。这时我们就要用到参数组的概念。
在前面优化器部分学过,优化器可以对不同的参数组设置不同的超参数。所以我们可以对不同的参数组设置不同的学习率。让我们的特征提取部分的学习率较小,而全连接层部分的学习率比较大。这就实现了不同的参数设置不同的学习率。
下面我们再通过一个具体例子来学习如何在PyTorch中实现模型的微调
四、PyTorch中的模型微调
# -*- coding: utf-8 -*-"""# @Time : 2020/5/13 9:13# @Author : DarrenZhang# @FileName: finetune_resnet18.py# @Software: PyCharm# @Blog :https://www.yuque.com/darrenzhang# @Brief : 模型finetune方法"""import osimport numpy as npimport torchimport torch.nn as nnfrom torch.utils.data import DataLoaderimport torchvision.transforms as transformsimport torch.optim as optimfrom matplotlib import pyplot as pltfrom tools.my_dataset import AntsDatasetfrom tools.common_tools import set_seedimport torchvision.models as modelsBASEDIR = os.path.dirname(os.path.abspath(__file__))device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # GPU使用print("use device :{}".format(device))set_seed(1) # 设置随机种子label_name = {"ants": 0, "bees": 1}# 参数设置MAX_EPOCH = 25BATCH_SIZE = 16LR = 0.001log_interval = 10val_interval = 1classes = 2start_epoch = -1lr_decay_step = 7# ============================ step 1/5 数据 ============================train_dir = ("H:/PyTorch_From_Zero_To_One/data/hymenoptera_data/train")valid_dir = ("H:/PyTorch_From_Zero_To_One/14_finetune/hymenoptera_data/val")norm_mean = [0.485, 0.456, 0.406]norm_std = [0.229, 0.224, 0.225]train_transform = transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),])valid_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),])# 构建MyDataset实例train_data = AntsDataset(data_dir=train_dir, transform=train_transform)valid_data = AntsDataset(data_dir=valid_dir, transform=valid_transform)# 构建DataLodertrain_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)# ============================ step 2/5 模型 ============================# 1/3 构建模型resnet18_ft = models.resnet18()# 2/3 加载参数# flag = 0flag = 1if flag:path_pretrained_model = ("H:/PyTorch_From_Zero_To_One/14_finetune/15_resnet18-5c106cde.pth")state_dict_load = torch.load(path_pretrained_model)resnet18_ft.load_state_dict(state_dict_load)# 法1 : 冻结卷积层flag_m1 = 0# flag_m1 = 1if flag_m1:for param in resnet18_ft.parameters():param.requires_grad = Falseprint("conv1.weights[0, 0, ...]:\n {}".format(resnet18_ft.conv1.weight[0, 0, ...]))# 3/3 替换fc层num_ftrs = resnet18_ft.fc.in_featuresresnet18_ft.fc = nn.Linear(num_ftrs, classes)resnet18_ft.to(device) # GPU使用:模型# ============================ step 3/5 损失函数 ============================criterion = nn.CrossEntropyLoss() # 选择损失函数# ============================ step 4/5 优化器 ============================# 法2 : conv 小学习率# flag = 0flag = 1if flag:fc_params_id = list(map(id, resnet18_ft.fc.parameters())) # 返回的是parameters的 内存地址base_params = filter(lambda p: id(p) not in fc_params_id, resnet18_ft.parameters())optimizer = optim.SGD([{'params': base_params, 'lr': LR*0}, # 0 -> 不能够更新参数了{'params': resnet18_ft.fc.parameters(), 'lr': LR}], momentum=0.9)else:optimizer = optim.SGD(resnet18_ft.parameters(), lr=LR, momentum=0.9) # 选择优化器scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=lr_decay_step, gamma=0.1) # 设置学习率下降策略# ============================ step 5/5 训练 ============================train_curve = list()valid_curve = list()for epoch in range(start_epoch + 1, MAX_EPOCH):loss_mean = 0.correct = 0.total = 0.resnet18_ft.train()for i, data in enumerate(train_loader):# forwardinputs, labels = datainputs, labels = inputs.to(device), labels.to(device) # GPU使用:数据outputs = resnet18_ft(inputs)# backwardoptimizer.zero_grad()loss = criterion(outputs, labels)loss.backward()# update weightsoptimizer.step()# 统计分类情况_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).squeeze().cpu().sum().numpy()# 打印训练信息loss_mean += loss.item()train_curve.append(loss.item())if (i+1) % log_interval == 0:loss_mean = loss_mean / log_intervalprint("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, i+1, len(train_loader), loss_mean, correct / total))loss_mean = 0.# if flag_m1:print("epoch:{} conv1.weights[0, 0, ...] :\n {}".format(epoch, resnet18_ft.conv1.weight[0, 0, ...]))scheduler.step() # 更新学习率# validate the modelif (epoch+1) % val_interval == 0:correct_val = 0.total_val = 0.loss_val = 0.resnet18_ft.eval()with torch.no_grad():for j, data in enumerate(valid_loader):inputs, labels = datainputs, labels = inputs.to(device), labels.to(device)outputs = resnet18_ft(inputs)loss = criterion(outputs, labels)_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).squeeze().cpu().sum().numpy()loss_val += loss.item()loss_val_mean = loss_val/len(valid_loader)valid_curve.append(loss_val_mean)print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, j+1, len(valid_loader), loss_val_mean, correct_val / total_val))resnet18_ft.train()train_x = range(len(train_curve))train_y = train_curvetrain_iters = len(train_loader)valid_x = np.arange(1, len(valid_curve)+1) * train_iters*val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterationsvalid_y = valid_curveplt.plot(train_x, train_y, label='Train')plt.plot(valid_x, valid_y, label='Valid')plt.legend(loc='upper right')plt.ylabel('loss value')plt.xlabel('Iteration')plt.show()

若有收获,就点个赞吧
0 人点赞
