- 梯度消失与爆炸
- Xavier方法
- Kaiming方法
- 常用初始化方法
一、梯度消失与爆炸
二、Xavier方法
方差一致性:保持数据尺度维持在恰当范围,通常方差为1
适合激活函数:饱和函数,如Sigmoid,Tanh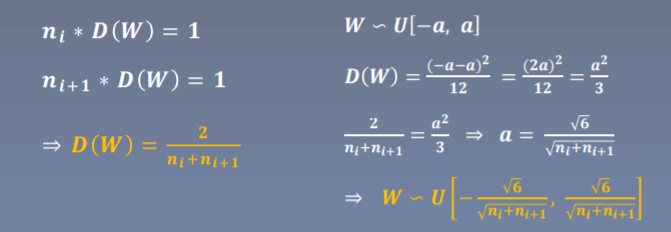
参考文献:Understanding the difficulty of training deep feedforward neural networks
三、Kaiming方法
方差一致性:保持数据尺度维持在恰当范围,通常方差为1
激活函数:ReLU及其变种
nn.init.kaiming_normal_(m.weight.data)
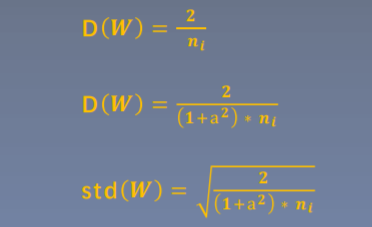
参考文献:Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification
十种初始化方法
- Xavier均匀分布
- Xavier正态分布
- Kaiming均匀分布
- Kaiming正态分布
- 均匀分布
- 正态分布
- 常数分布
- 正交矩阵初始化
- 单位矩阵初始化
- 稀疏矩阵初始化
nn.init.calculate_gain(nonlinearity, param=None)
nn.init.calculate_gain()
- 主要功能:计算激活函数的方差变化尺度
- 主要参数
nonlinearity: 激活函数名称param: 激活函数的参数,如Leaky ReLU的negative_slop

若有收获,就点个赞吧
0 人点赞
