- 一、1D Conv、2D Conv、3D Conv
- 二、
nn.Conv2d() - ================================= load img ==================================
- print(os.path.dirname(os.path.abspath(file))) # 当前文件路径
- convert to tensor
- ================================= create convolution layer ==================================
- ================ 2d
- flag = 0
- ================ transposed
- flag = 1
- ================================= visualization ==================================
- 三、转置卷积
本章前两篇文章学习了如何搭建一个网络模型以及搭建网络模型过程中采用的容器 Sequential 、 ModuleList 、 ModuleDict 。今天开始我们来学习神经网络中常见的网络层 — 卷积层。分为三个主要的部分。
- 1D Conv、2D Conv、3D Conv
- 卷积模块
nn.Conv2d() - 转置卷积
nn.ConvTranspose()
一、1D Conv、2D Conv、3D Conv
首先我们看什么是卷积操作。卷积运算。卷积运算是用卷积核在输入图像上进行滑动。然后计算相应位置的一个乘加操作:就是对应位置进行乘法,然后再相加起来。
卷积核:又称为滤波器,过滤器,可认为是某种模式,某种特征。 卷积过程类似于用一个模版去图像上寻找与它相似的区域,与卷积核模式越相似,激活值越高,从而实现特征提取。
卷积操作是一个特征检测器在输入的图像上进行扫描。不断的去检测图像的每一个区域与我们的特征检测器的模式是否相似,若越相似,他的激活值越高,从而实现了一个特征提取功能。所以在深度学习当中,我会把它卷积核看作特征提取器的检测器。
上图是AlexNet卷积核可视化,发现卷积核学习到的是边缘,条纹,色彩这一些细节的特征,这也印证了卷积核是某些特征的特征提取器。那么具体是那种特征、哪种模式是由模型去学习来的。
那我们是怎么区分卷积核是几维的呢?
卷积维度:一般情况下,一个卷积核在一个信号上的几个维度上滑动,就是几维卷积。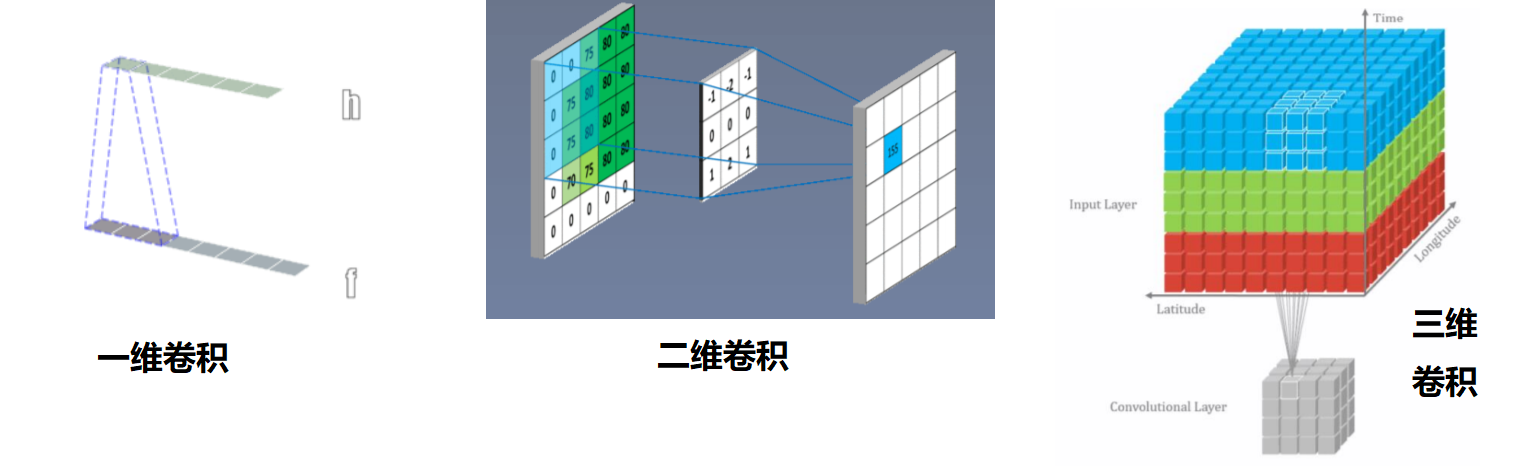
二、nn.Conv2d()
nn.Conv2d(in_channels,out_channels,kernel_size,stride=1,padding=0,dilation=1,groups=1,bias=True,padding_mode='zeros')
- 功能:对多个二维信号进行二维卷积
- 主要参数:
in_channels:输入通道数out_channels:输出通道数,等价于卷积核个数kernel_size:卷积核尺寸stride:步长padding:填充个数dilation:空洞卷积大小groups:分组卷积设置bias:偏置
- 尺寸计算
- 简化版:

- 完整版:
 ```python
import os
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
from tools.common_tools import transform_invert, set_seed
```python
import os
import torch.nn as nn
from PIL import Image
from torchvision import transforms
from matplotlib import pyplot as plt
from tools.common_tools import transform_invert, set_seed
- 简化版:
set_seed(3) # 设置随机种子
================================= load img ==================================
print(os.path.dirname(os.path.abspath(file))) # 当前文件路径
pathimg = os.path.join(os.path.dirname(os.path.abspath(_file)), “lena.png”) img = Image.open(path_img).convert(‘RGB’) # 0~255
convert to tensor
imgtransform = transforms.Compose([transforms.ToTensor()]) img_tensor = img_transform(img) img_tensor.unsqueeze(dim=0) # CHW to BCH*W 加上batch维度
================================= create convolution layer ==================================
================ 2d
flag = 1
flag = 0
if flag: convlayer = nn.Conv2d(3, 1, 3) # input:(i, o, size) weights:(o, i , h, w) nn.init.xavier_normal(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
================ transposed
flag = 1
flag = 0 if flag: convlayer = nn.ConvTranspose2d(3, 1, 3, stride=2) # input:(i, o, size) nn.init.xavier_normal(conv_layer.weight.data)
# calculation
img_conv = conv_layer(img_tensor)
================================= visualization ==================================
print(“卷积前尺寸:{}\n卷积后尺寸:{}”.format(img_tensor.shape, img_conv.shape)) img1 = img_tensor[0, 0:2, …] print(img1.shape) img_conv = transform_invert(img_conv[0, 0:1, …], img_transform) img_raw = transform_invert(img_tensor.squeeze(), img_transform) plt.subplot(122).imshow(img_conv, cmap=’gray’) plt.subplot(121).imshow(img_raw) plt.show()
报错
```python
RuntimeError: Can't call numpy() on Variable that requires grad. Use var.detach().numpy() instead.
原因:
做了一次卷积之后,是有计算图存在的,在 transform_invert类中 修改了img_,就改变了计算图,会造成梯度计算错误。所以修改思路是放弃计算图。
def transform_invert(img_, transform_train):
"""
将输入的tensor数据进行反transfrom操作,对输入的数据进行可视化展示
:param img_: tensor
:param transform_train: torchvision.transforms
:return: PIL image
"""
if 'Normalize' in str(transform_train):
norm_transform = list(filter(lambda x: isinstance(x, transforms.Normalize), transform_train.transforms))
mean = torch.tensor(norm_transform[0].mean, dtype=img_.dtype, device=img_.device)
std = torch.tensor(norm_transform[0].std, dtype=img_.dtype, device=img_.device)
img_.mul_(std[:, None, None]).add_(mean[:, None, None]) # 乘方差 加均值
img_ = img_.transpose(0, 2).transpose(0, 1) # C*H*W --> H*W*C
if 'ToTensor' in str(transform_train):
img_ = img_.detach() # 添加该行密码
img_ = np.array(img_) * 255
# 将numpy_array转化为PIL
if img_.shape[2] == 3:
img_ = Image.fromarray(img_.astype('uint8')).convert('RGB')
elif img_.shape[2] == 1:
img_ = Image.fromarray(img_.astype('uint8').squeeze())
else:
raise Exception("Invalid img shape, expected 1 or 3 in axis 2, but got {}!".format(img_.shape[2]) )
return img_
.detach()方法
img = img.detach() 会从当前计算图中返回一个Tensor -> img(从计算图中隔离), 这个Tensor img是不需要梯度的。
三、转置卷积
转置卷积又称为反卷积(Deconvolution)和部分跨越卷积(Fractionally strided Convolution) ,用于对图像进行上采样(UpSample)
为什么称为转置卷积?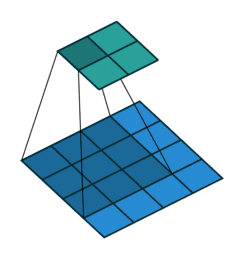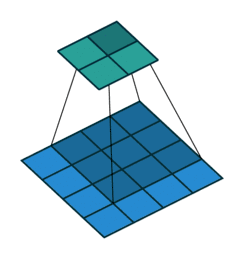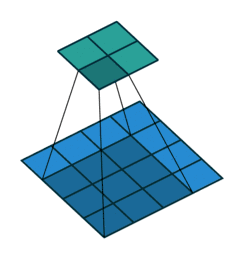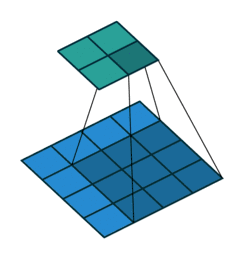
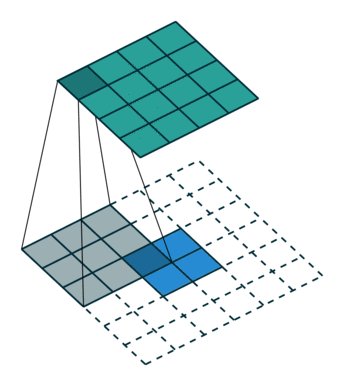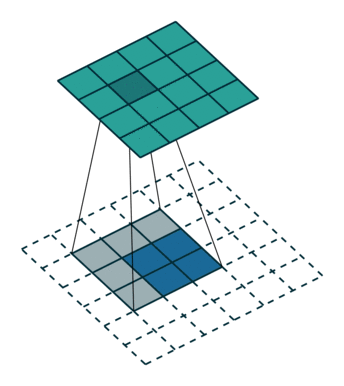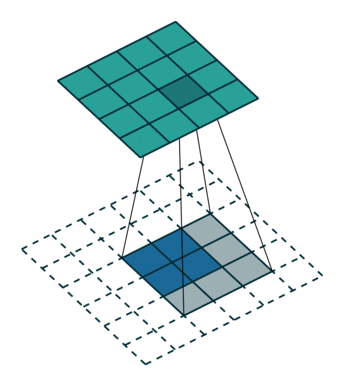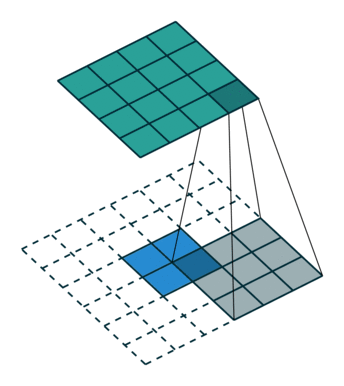
- 正常卷积:
假设图像尺寸为
 ,卷积核为
,卷积核为 ,padding=0,stride=1
,padding=0,stride=1- 图像:
 ;卷积核:
;卷积核: ;输出:
;输出:
- 图像:
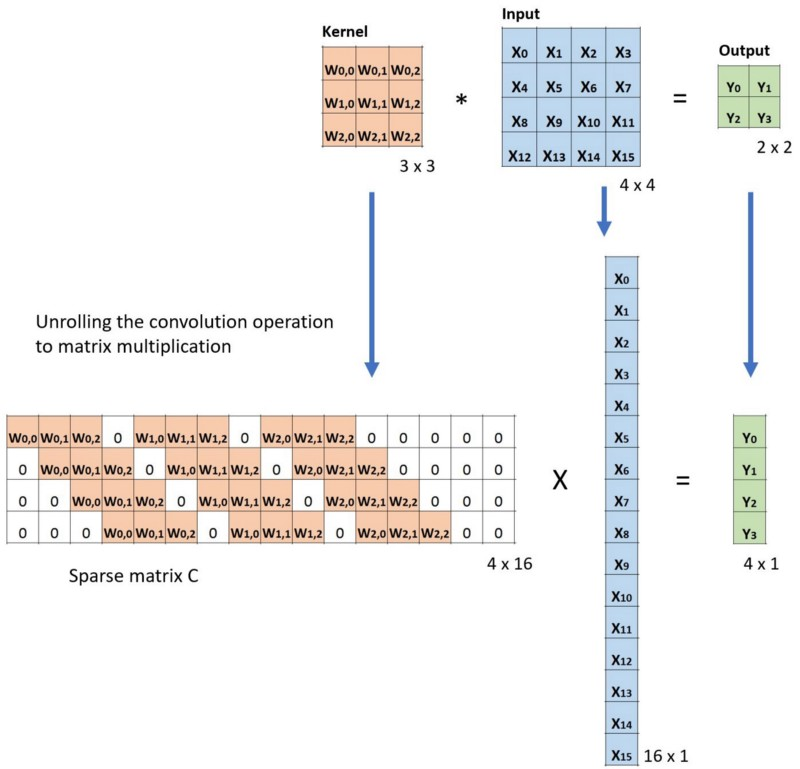
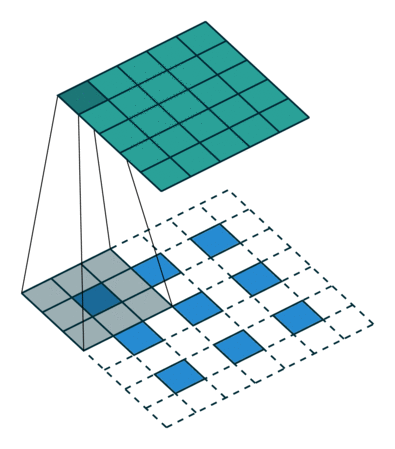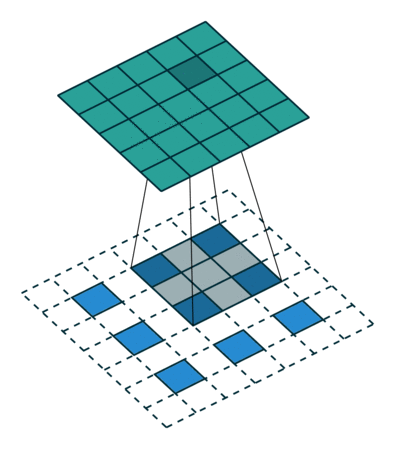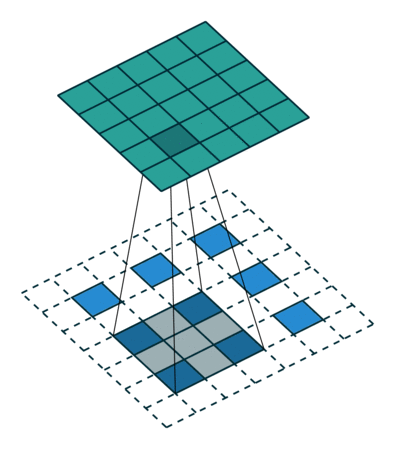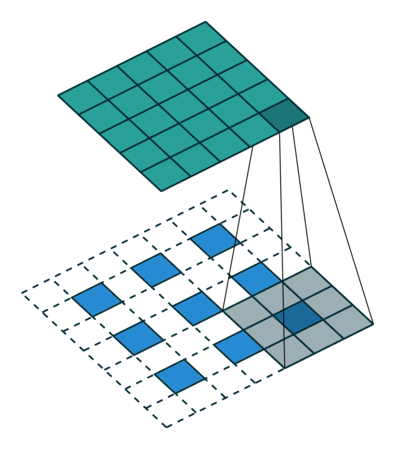
转置卷积: 假设图像尺寸为
 ,卷积核为,padding=0,stride=1
,卷积核为,padding=0,stride=1in_channels:输入通道数out_channels:输出通道数kernel_size:卷积核尺寸stride:步长padding:填充个数dilation:空洞卷积大小groups:分组卷积设置bias:偏置
 ;卷积核:
;卷积核: ;输出:
;输出:
尺寸计算
- 简化版:

- 完整版:

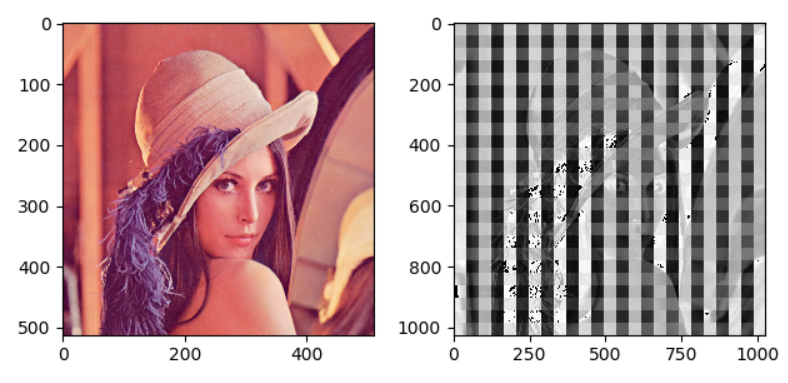
转置卷积的通病,是由不均匀重叠导致的
棋盘效应:推荐文章《 Deconvolution and Checkerboard Artifacts》

若有收获,就点个赞吧
0 人点赞
