上篇文章学习了如何搭建一个模型。搭建一个模型需要两个要素,第一是构建子模型,第二是拼接子模型。在搭建模型时,还有一个非常重要的属性是模型容器
- 网络层容器(Containers)
- AlexNet构建
一、网络层容器

01. nn.Sequential
nn.Sequential 是 nn.module 的容器,用于按顺序包装一组网络层,将这组网络层看成一个整体。也可以看作是模型当中的一个子模块。
在传统的机器学习当中,有一部叫做特征工程,我们需要人为的去设计特征,然后将特征输入的分类器去分类。在深度学习时代已经弱化了特征工程这一个概念,尤其是卷积神经网络对图像的特征完全不需要人为去设计,这一切都可以交给卷积神经网络自动去学习特征。然后在最后会加上这个全连接层,用于输出分类结果。在早期阶段的神经网络当中用于分类的分类器是由全连接层构成的,所以在深度学习时代也有习惯以全连接层分界线。将网络模型一个特征提取模块和分类模块,对一个大的模型进行划分,以便于在模型进行管理。利用我们的LeNe模型,可以将前面的卷积、池化进行一个包装,把它称为特征提取器。最后把全连接层的部分进行包装,称为一个分类器classifier。对这两个部分在统一的包装构成了LeNet整体网络。
在PyTorch中,可以采用 Sequential 这个容器,将前面四层卷积、池化包装成一个 Sequential ;将三层全连接层包装成一个 Sequential ,组装这两个 Sequential 构成整体的LeNet。下面通过代码来观察使用 Sequential 构建LeNet。
# ============================ Sequential ============================ #class LeNetSequential(nn.Module):def __init__(self, classes):super(LeNetSequential, self).__init__()self.features = nn.Sequential(nn.Conv2d(3, 6, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),nn.Conv2d(6, 16, 5),nn.ReLU(),nn.MaxPool2d(kernel_size=2, stride=2),)self.classifier = nn.Sequential(nn.Linear(16*5*5, 120),nn.ReLU(),nn.Linear(120, 84),nn.ReLU(),nn.Linear(84, classes),)def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xnet = LeNetSequential(classes=2)fake_img = torch.randn((4, 3, 32, 32), dtype=torch.float32)output = net(fake_img)print(net)print(output)
下面我们来观察一下 Sequential 中他实现了一个什么功能。这样我们单步运行到上面代码的第11行,现在采用 step into 进入到 MaxPool2d 类中,然后我们step out 之后,在step into,现在来到了 container.py 文件中的 Sequential类 ,我们看到其还是继承 Module类 。既然他继承于 Module类,所以 Sequential类 还是会有8个有序字典去管理他的属性。还是调用了 Module 父类的 __init__类 去构建相应的属性。
class Sequential(Module):def __init__(self, *args):super(Sequential, self).__init__()if len(args) == 1 and isinstance(args[0], OrderedDict):for key, module in args[0].items():self.add_module(key, module)else:for idx, module in enumerate(args):self.add_module(str(idx), module)
这样我们来看一下这个 self Sequential() 的8个有序字典。接下来会对我们传入的这些网络层参数添加到我们的Sequential 当中。看到这里会做一个判断,按照我们输入的参数的数据类型看是否是一个有序字典。这里应该不是有序字典,所以会跳到else,进入一个for循环,对传入参数进行循环取出每一个网络层,然后采用 add_module方法 将网络层添加到 Sequential 当中。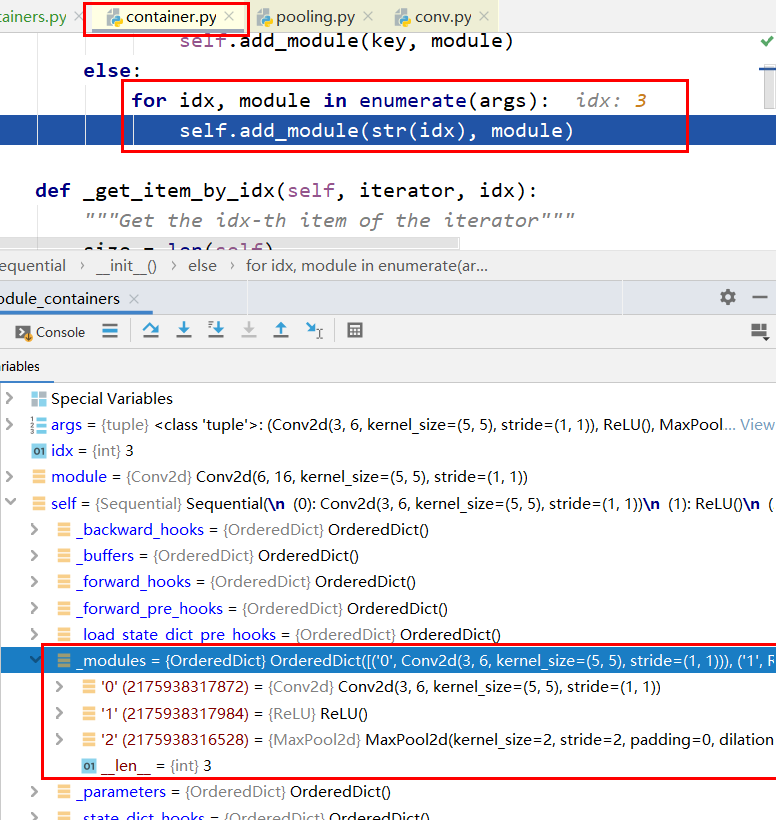
经过不断的循环添加网络层,就完成了一个 Sequential 的构建。现在回到LeNet这个类当中。你们知道LeNet的 _modules 和 _parameters 字典还是空的。因为截至目前,我们的程序只是实现了等号右边 nn.Sequential 的构建。还没有把 nn.Sequential 复制给我们的类型属性 self.features 。当我们赋值完成之后,我们才会在 _modules 字典中看到 Sequential 。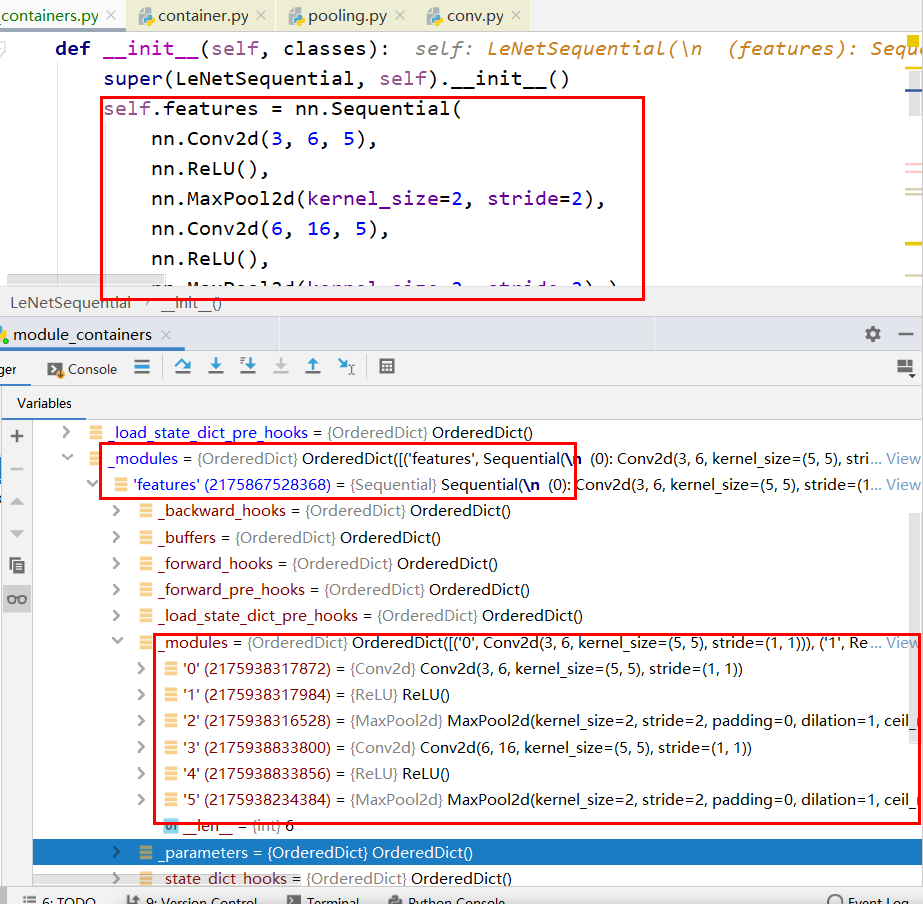
看到在self下的 _modules 字典中出现了 features 这个key,key里头的value就是等号右边这个 Sequential ,我们点开 Sequential ,他又是一个 Module ,所以他还有这8个有序字典。接着我们看到在 features 中的 _modules 有刚刚构建的这6个网络层,这六个网络层是顺序构建的。
分类层同理,这样采用 Sequential 构建网络就完成了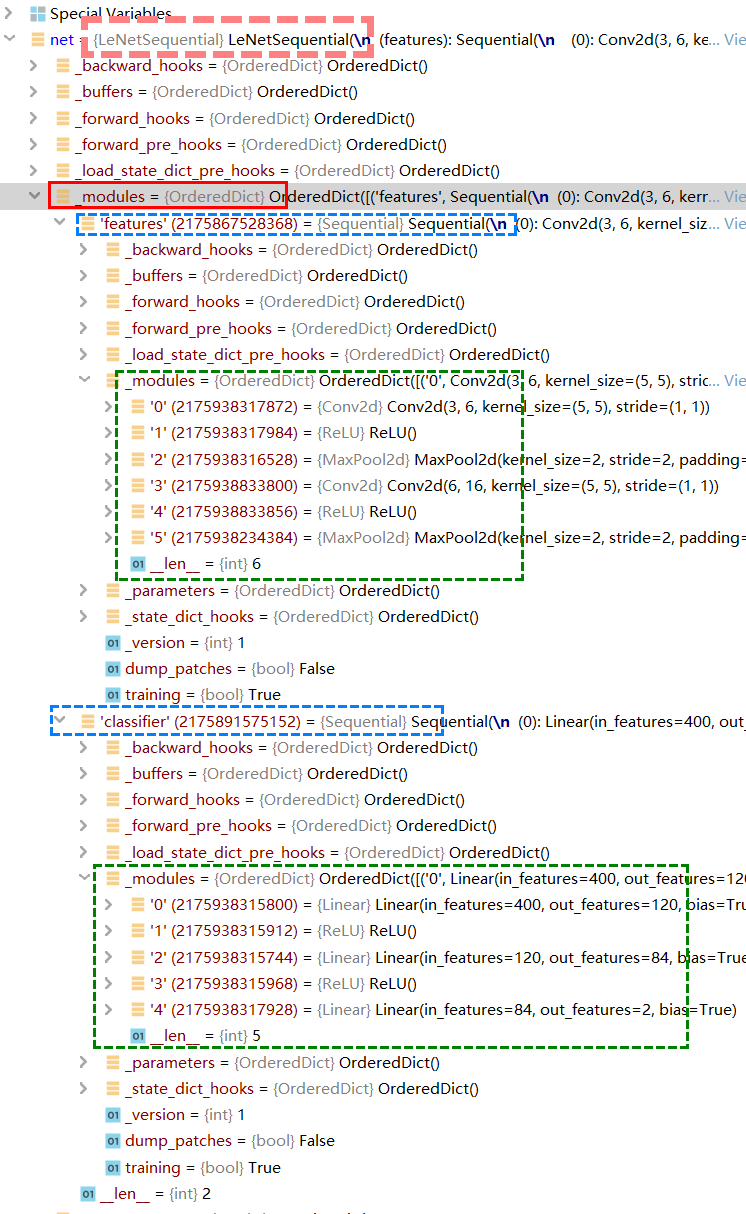
目前为止,构建子模块流程完成,下面我们看一下 PyTorch 是如何拼接各个子模块的。在 LeNetSequential类 中的第21行下断点并进入。进入到的是 module.py 中的 __call__函数 。
def __call__(self, *input, **kwargs):for hook in self._forward_pre_hooks.values():result = hook(self, input)if result is not None:if not isinstance(result, tuple):result = (result,)input = resultif torch._C._get_tracing_state():result = self._slow_forward(*input, **kwargs)else:result = self.forward(*input, **kwargs)for hook in self._forward_hooks.values():hook_result = hook(self, input, result)if hook_result is not None:result = hook_resultif len(self._backward_hooks) > 0:var = resultwhile not isinstance(var, torch.Tensor):if isinstance(var, dict):var = next((v for v in var.values() if isinstance(v, torch.Tensor)))else:var = var[0]grad_fn = var.grad_fnif grad_fn is not None:for hook in self._backward_hooks.values():wrapper = functools.partial(hook, self)functools.update_wrapper(wrapper, hook)grad_fn.register_hook(wrapper)return result
跳转到上面代码的第11行(具体在源码中的位置,自己对应)。然后step into ,就会进入到 LeNetSequential类 中的 forward 函数。然后在点击step into,跳转到 container.py 中的 Sequential类 中的 forward函数 。
class Sequential(Module):...def forward(self, input):for module in self:input = module(input)return input
对 Sequential 中的网络层进行前向传播。
上图是将Conv2d进行前向运算,对input实现了卷积操作。这样迭代的从Sequential中取出网络层进行前向运算。由于是按照严格的顺序进行前向运算,所以数据格式、类型必须要统一。
最终的输出结果如下图所示:
但是从上图看出,各个网络层没有对应的名称,只能通过序号进行索引,如果是个很大的网络,很难通过序号进行索引。所以我们可以通过对网络层命名进行索引。
对 nn.Sequential() 传入有序字典 OrderDict({ , , , }) ,以这种方式来构建我们的网络。
class LeNetSequentialOrderDict(nn.Module):"""给网络层命名"""def __init__(self, classes):super(LeNetSequentialOrderDict, self).__init__()self.features = nn.Sequential(OrderedDict({'conv1': nn.Conv2d(3, 6, 5),'relu1': nn.ReLU(inplace=True),'pool1': nn.MaxPool2d(kernel_size=2, stride=2),'conv2': nn.Conv2d(6, 16, 5),'relu2': nn.ReLU(inplace=True),'pool2': nn.MaxPool2d(kernel_size=2, stride=2),}))self.classifier = nn.Sequential(OrderedDict({'fc1': nn.Linear(16*5*5, 120),'relu3': nn.ReLU(),'fc2': nn.Linear(120, 84),'relu4': nn.ReLU(inplace=True),'fc3': nn.Linear(84, classes),}))def forward(self, x):x = self.features(x)x = x.view(x.size()[0], -1)x = self.classifier(x)return xnet = LeNetSequentialOrderDict(classes=2)fake_img = torch.randn((4, 3, 32, 32), dtype=torch.float32)output = net(fake_img)print(net)print(output)
按照同样的调试步骤,在34行下断点,进入 LeNetSequentialOrderDict类 ,然后在15行进行两次step into,进入 container.py 中的 Sequential类 。
class Sequential(Module):def __init__(self, *args):super(Sequential, self).__init__()if len(args) == 1 and isinstance(args[0], OrderedDict):for key, module in args[0].items():self.add_module(key, module)else:for idx, module in enumerate(args):self.add_module(str(idx), module)
因为传入的是OrderDict,所以进入第一个判断中。对Dict字典中中的key和value取出并加入到module中。key就是网络层的名称,value为网络层module。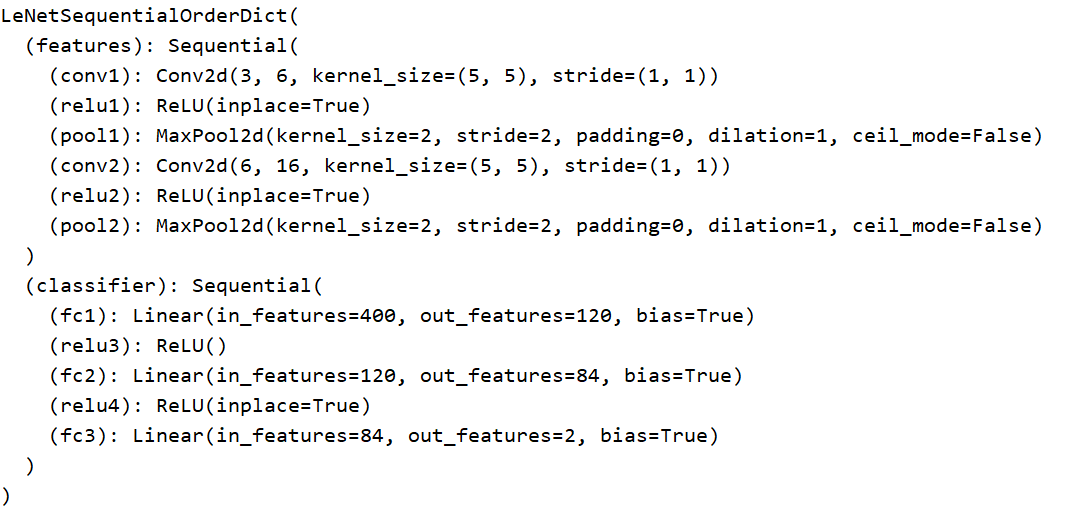
总结:
nn.Sequential 是 nn.module 的容器,用于按顺序包装一组网络层
- 顺序性:各网络层之间严格按照顺序构建 ,一定要保证前后的数据关系一致。
- 自带forward():自带的forward函数,通过for循环依次执行前向传播运算
02. nn.ModuleList
nn.ModuleList 是 nn.module 的容器,用于包装一组网络层,以迭代方式调用网络层
主要方法:
append():在ModuleList后面添加网络层extend():拼接两个ModuleListinsert():指定在ModuleList中位置插入网络层 ```python============================ ModuleList ============================
class ModuleList(nn.Module): def init(self):
super(ModuleList, self).__init__()self.linears = nn.ModuleList([nn.Linear(10, 10) for i in range(20)])
def forward(self, x):
for i, linear in enumerate(self.linears): x = linear(x) return x
net = ModuleList()
print(net)
fake_data = torch.ones((10, 10))
output = net(fake_data)
print(output)
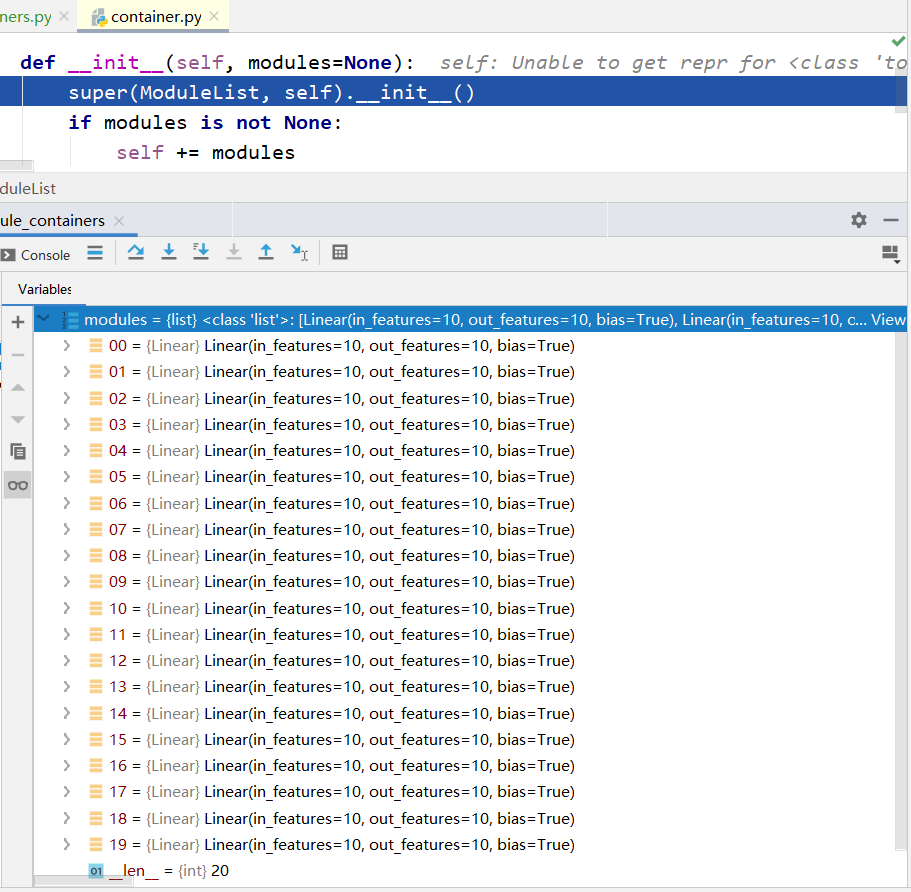
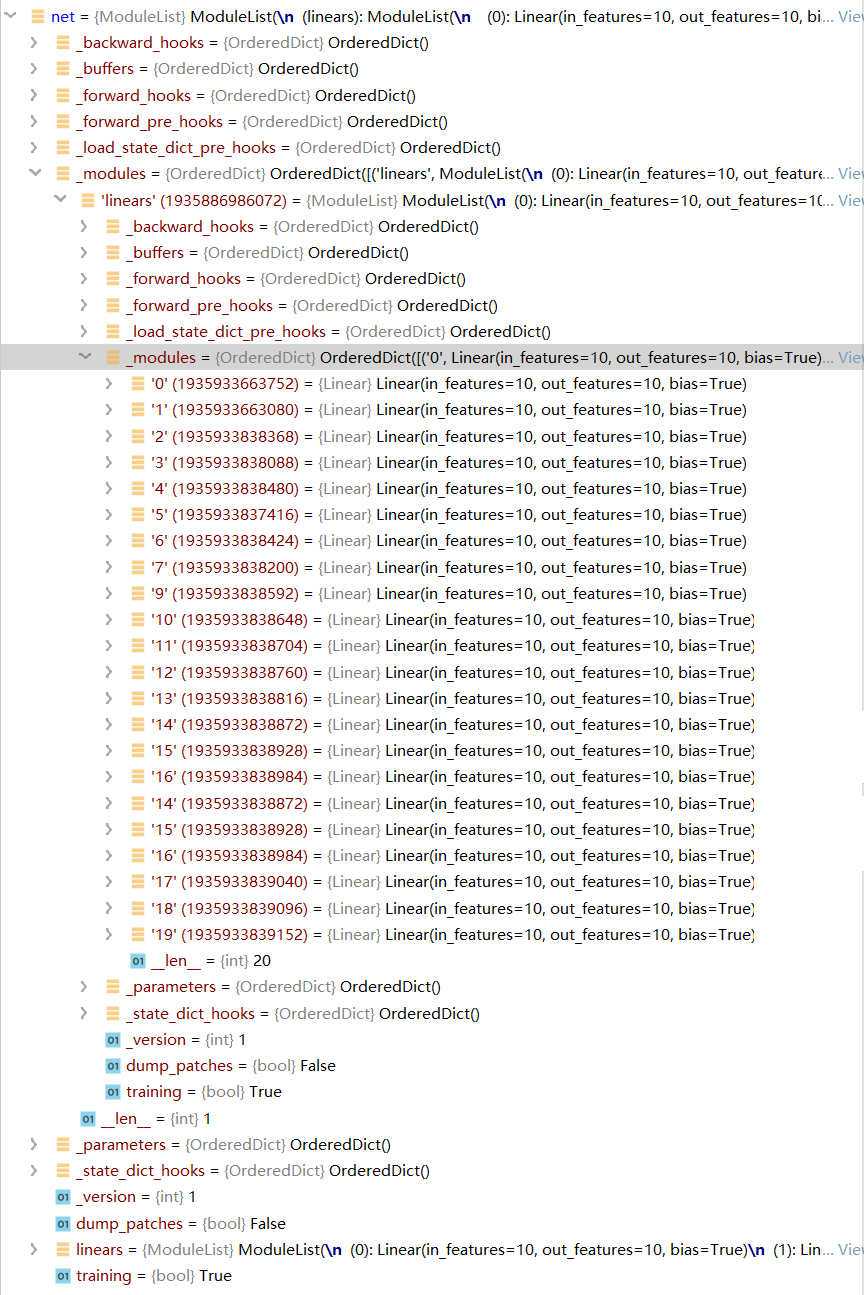
在第13行加上断点,进入到 `ModuleList类` 中,运行到第5行,执行20次循环列表生成之后,setp into到 `container.py` **文件中的 **`ModuleList``类` 中的 `__init__函数`。
```python
class ModuleList(Module):
def __init__(self, modules=None):
super(ModuleList, self).__init__()
if modules is not None:
self += modules
03. nn.ModuleDict
nn.ModuleDict 是 nn.module 的容器,用于包装一组网络层,以索引方式调用网络层
主要方法:
clear():清空ModuleDictitems():返回可迭代的键值对(key-value pairs)keys():返回字典的键(key)values():返回字典的值(value)pop():返回一对键值,并从字典中删除 ```python============================ ModuleDict ============================
class ModuleDict(nn.Module): def init(self):
super(ModuleDict, self).__init__() self.choices = nn.ModuleDict({ 'conv': nn.Conv2d(10, 10, 3), 'pool': nn.MaxPool2d(3) }) self.activations = nn.ModuleDict({ 'relu': nn.ReLU(), 'prelu': nn.PReLU() })def forward(self, x, choice, act):
x = self.choices[choice](x) x = self.activations[act](x) return x
net = ModuleDict() fake_img = torch.randn((4, 10, 32, 32)) output = net(fake_img, ‘conv’, ‘relu’) # 除了输入数据,还需要传入需要选择的网络层 print(output)
<a name="5VZzV"></a>
## 04. 总结
- `nn.Sequential` :**顺序性,**各网络层之间严格按顺序执行,常用于block构建
- `nn.ModuleList` :**迭代性,**常用于大量重复网构建,通过for循环实现重复构建
- `nn.ModuleDict` :**索引性,**常用于可选择的网络层
<a name="wjNys"></a>
# 二、AlexNet搭建
```python
# torchvision.models.AlexNet()
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x

若有收获,就点个赞吧
0 人点赞
