- 人民币二分类
- DataLoader 与 Dataset
一、人民币二分类
我们将从一个二分类的例子来引入数据的操作。
DataLoader和D``ataSet是数据读取的核心
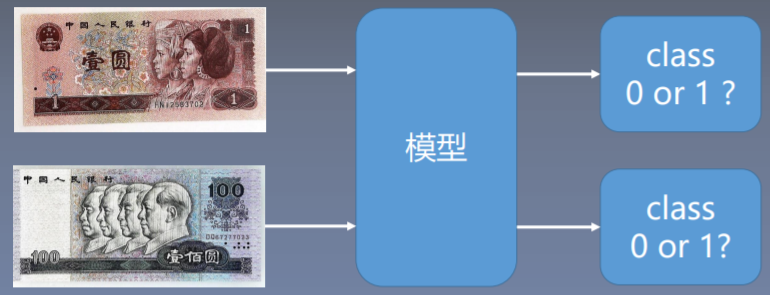
我们要训练一个人民币二分类模型来对第四套人民币的一元和一百元纸币进行分类。具体需求:将一张纸币图片输入,模型给出相应的分类。这里我们可以把我们的人民币图片想象成自变量x,类别的输出就是因变量y。而模型所做的事情就是将自变量的x映射到的因变量y。
我们怎么训练一个机器学习模型呢?机器学习训练模型的五大步骤 ↓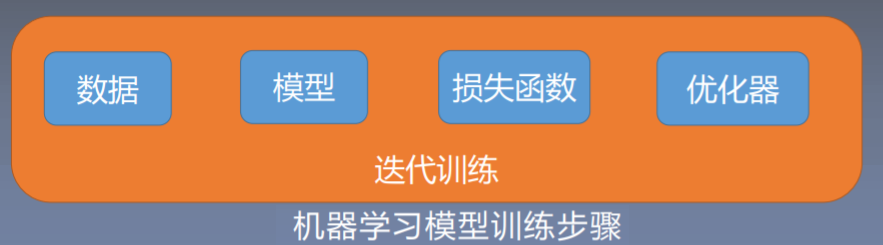
今天主要学习的就是数据模块当中的数据读取。数据模块通常还会分为四个子模块,分别是收集、划分、读取、预处理。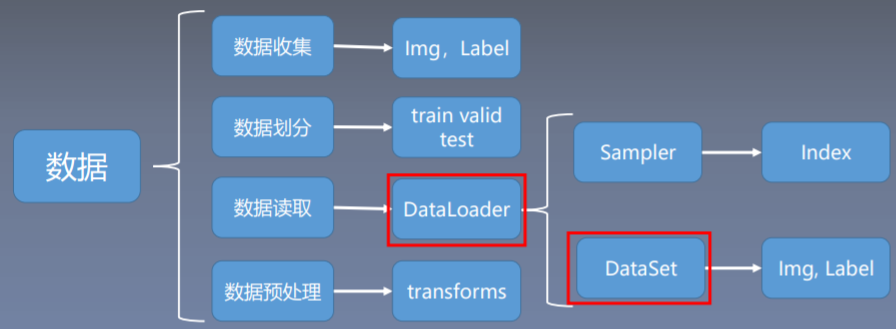
- 数据收集:在进行一个实验之前要收集一批原始样本和标签
- 有了最原始的数据之后,我们会对数据进行数据集的划分。我们会划分为训练集、验证集和测试集。这三个数据集都有他各自的作用。
- 训练集是用来训练我们的模型;
- 验证集用来验证模型是否过拟合(可以理解为用验证集来挑选没有过拟合的模型)
- 测试集用来测试那些我们挑选出来的模型来测试它的性能。
- 数据读取,
PyTorch中的数据读取的核心是DataLoader。其会分为两个子模块,一个是Sampler,一个DataSet。这就是DataLoader的一个基本结构。今天我们主要来学习DataLoader和DataSetSampler的功能是生成索引,也就是样本的序号。DataSet会根据索引去读取我们的图片以及它的标签。。
我们把数据读取进来之后,往往还需要进行一些数据预处理,比如中心化,标准化、旋转、翻转等等。这个在PyTorch中是通过 transforms 进行实现的。
二、DataLoader 与 Dataset
2.1
torch.utils.data.DataLoader()DataLoader(dataset,batch_size=1,shuffle=False,sampler=None,batch_sampler=None,num_workers=0,collate_fn=None,pin_memory=False,drop_last=False,timeout=0,worker_init_fn=None,multiprocessing_context=None)
功能:构建可迭代的数据装载器。在训练的时候,每一次
iteration就是从DataLoader当中去获取一个batchsize大小的数据。dataset: Dataset类,决定数据从哪读取及如何读取batchsize: 批大小num_works: 是否多进程读取数据,减少我们读取数据的时间,加速了模型训练shuffle: 每个epoch是否乱序drop_last:当样本数不能被batchsize整除时,是否舍弃最后一批数据
Epoch : 所有训练样本都已输入到模型中,称为一个EpochIteration :一批样本输入到模型中,称之为一个IterationBatchsize :批大小,决定一个Epoch有多少个Iteration
样本总数:80, Batchsize:8 -> 1 Epoch = 10 Iteration
样本总数:87, Batchsize:8 -> 1 Epoch = 10 Iteration ? drop_last = True
-> 1 Epoch = 11 Iteration ? drop_last = False
2.2 torch.utils.data.Dataset()
class Dataset(object):def __getitem__(self, index):raise NotImplementedErrordef __add__(self, other):return ConcatDataset([self, other])
- 功能:用来定义我们数据从哪里读取以及如何读取的问题。
PyTorch给定的DataSet是抽象类,所有自定义的Dataset需要继承它,并且复写__getitem__()__getitem__(): 是Dataset的核心。功能是:接收一个索引,返回一个样本及标签。至于如何去读取样本,这就是用户所需要去编写的。
数据读取机制的三大问题

- 我们第一个问题是读哪些数据。具体说应该是在每一个
iteration的时候,我们该读取哪一些数据,每一个iteration中读取一个batch_size大小。那假如我们有80个样本,那我们从其中读取8个样本,那该读取哪8个样本???这就是我们第一个问题读哪些数据。 - 第二个问题是从哪读的数据。也就是在硬盘当中,我们该怎么寻找并设置我们的硬盘数据路径
- 最后一个问题怎么读取数据。
现在从代码当中去学习,在进行实现之前,我们首先要收集数据。这数据已经给大家提供好,可从如下百度云盘链接自行获取,提取码:rame。然后在项目根目录下创建一个 data 的文件夹。在这个文件夹里我们有两个文件夹,每一个文件夹就对应的一类图片。这就是模拟我们真实场景当中的最原始的数据。我们有了数据以及标签,接下来我们要对这些数据进行划分。数据集划分为训练验证和测试集合。
# -*- coding: utf-8 -*-"""# @file name : split_dataset.py# @author : DarrenZhang# @date : 2020年5月4日14:54:22# @brief : 将数据集划分为训练集,验证集,测试集"""import osimport randomimport shutildef makedir(new_dir):if not os.path.exists(new_dir):os.makedirs(new_dir)if __name__ == '__main__':random.seed(1)dataset_dir = os.path.join("..", "data", "RMB_data") # 自行调整路径print(dataset_dir)split_dir = os.path.join("..", "data", "rmb_split")print(split_dir)train_dir = os.path.join(split_dir, "train")valid_dir = os.path.join(split_dir, "valid")test_dir = os.path.join(split_dir, "test")# ----- 设置分割比例 ----- #train_pct = 0.8valid_pct = 0.1test_pct = 0.1# ----------------------- #for root, dirs, files in os.walk(dataset_dir):for sub_dir in dirs:imgs = os.listdir(os.path.join(root, sub_dir))imgs = list(filter(lambda x: x.endswith('.jpg'), imgs))random.shuffle(imgs)img_count = len(imgs)train_point = int(img_count * train_pct)valid_point = int(img_count * (train_pct + valid_pct))for i in range(img_count):if i < train_point:out_dir = os.path.join(train_dir, sub_dir)elif i < valid_point:out_dir = os.path.join(valid_dir, sub_dir)else:out_dir = os.path.join(test_dir, sub_dir)makedir(out_dir)target_path = os.path.join(out_dir, imgs[i])src_path = os.path.join(dataset_dir, sub_dir, imgs[i])shutil.copy(src_path, target_path)print('Class:{}, train:{}, valid:{}, test:{}'.format(sub_dir, train_point, valid_point-train_point,img_count-valid_point))
收集原始数据集并且划分数据集之后,我们就可以进行模型训练。我们看一下代码的结构。
# -*- coding: utf-8 -*-# @Time : 2020/5/9 16:27# @Author : DarrenZhang# @FileName: train.py# @Software: PyCharm# @Blog :https://www.yuque.com/darrenzhang# @Brief : 人民币分类模型训练import osimport numpy as npimport torchimport torch.nn as nnimport torchvision.transforms as transformsimport torch.optim as optimimport syssys.path.append("../")from torch.utils.data import DataLoaderfrom matplotlib import pyplot as pltfrom model.lenet import LeNetfrom tools.my_dataset import RMBDatasetfrom tools.common_tools import set_seedset_seed(seed=1) # 设置随机种子rmb_label = {"1": 0, "100": 1}# 参数设置MAX_EPOCH = 10BATCH_SIZE = 16LR = 0.01log_interval = 10val_interval = 1# ============================ step 1/5 数据 ============================train_dir = "H:/PyTorch_From_Zero_To_One/data/rmb_split/train"valid_dir = "H:/PyTorch_From_Zero_To_One/data/rmb_split/valid"norm_mean = [0.485, 0.456, 0.406]norm_std = [0.229, 0.224, 0.225]train_transform = transforms.Compose([transforms.Resize((32, 32)), # resize image to 32 x 32transforms.RandomCrop(32, padding=4), # 随机裁剪transforms.ToTensor(), # 将图片数据转化成张量数据,并且归一化:将0~255的像素值归一化到0~1transforms.Normalize(norm_mean, norm_std), # 将数据的均值为0,标准差为1])valid_transform = transforms.Compose([transforms.Resize((32, 32)), # 不需要随机裁剪,真正考试的时候,是不需要做模拟题的transforms.ToTensor(),transforms.Normalize(norm_mean, norm_std),])# 构建MyDataset实例train_data = RMBDataset(data_dir=train_dir, transform=train_transform)valid_data = RMBDataset(data_dir=valid_dir, transform=valid_transform)# 构建DataLodertrain_loader = DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)valid_loader = DataLoader(dataset=valid_data, batch_size=BATCH_SIZE)# ============================ step 2/5 模型 ============================net = LeNet(classes=2)net.initialize_weights()# ============================ step 3/5 损失函数 ============================criterion = nn.CrossEntropyLoss() # 选择损失函数# ============================ step 4/5 优化器 ============================optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9) # 选择优化器scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略# ============================ step 5/5 训练 ============================train_curve = list()valid_curve = list()for epoch in range(MAX_EPOCH):loss_mean = 0.correct = 0.total = 0.net.train()for i, data in enumerate(train_loader):# forwardinputs, labels = dataoutputs = net(inputs)# backwardoptimizer.zero_grad()loss = criterion(outputs, labels)loss.backward()# update weightsoptimizer.step()# 统计分类情况_, predicted = torch.max(outputs.data, 1)total += labels.size(0)correct += (predicted == labels).squeeze().sum().numpy()# 打印训练信息loss_mean += loss.item()train_curve.append(loss.item())if (i + 1) % log_interval == 0:loss_mean = loss_mean / log_intervalprint("Training:Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, i + 1, len(train_loader), loss_mean, correct / total))loss_mean = 0.scheduler.step() # 更新学习率# validate the modelif (epoch + 1) % val_interval == 0:correct_val = 0.total_val = 0.loss_val = 0.net.eval()with torch.no_grad():for j, data in enumerate(valid_loader):inputs, labels = dataoutputs = net(inputs)loss = criterion(outputs, labels)_, predicted = torch.max(outputs.data, 1)total_val += labels.size(0)correct_val += (predicted == labels).squeeze().sum().numpy()loss_val += loss.item()valid_curve.append(loss_val / valid_loader.__len__())print("Valid:\t Epoch[{:0>3}/{:0>3}] Iteration[{:0>3}/{:0>3}] Loss: {:.4f} Acc:{:.2%}".format(epoch, MAX_EPOCH, j + 1, len(valid_loader), loss_val, correct_val / total_val))train_x = range(len(train_curve))train_y = train_curvetrain_iters = len(train_loader)valid_x = np.arange(1, len(valid_curve) + 1) * train_iters * val_interval # 由于valid中记录的是epochloss,需要对记录点进行转换到iterationsvalid_y = valid_curveplt.plot(train_x, train_y, label='Train')plt.plot(valid_x, valid_y, label='Valid')plt.legend(loc='upper right')plt.ylabel('loss value')plt.xlabel('Iteration')plt.show()# ============================ inference ============================BASE_DIR = os.path.dirname(os.path.abspath(__file__))test_dir = os.path.join(BASE_DIR, "test_data")test_data = RMBDataset(data_dir=test_dir, transform=valid_transform)valid_loader = DataLoader(dataset=test_data, batch_size=1)for i, data in enumerate(valid_loader):# forwardinputs, labels = dataoutputs = net(inputs)_, predicted = torch.max(outputs.data, 1)rmb = 1 if predicted.numpy()[0] == 0 else 100print("模型获得{}元".format(rmb))
训练完成之后,会在他的一个loss曲线图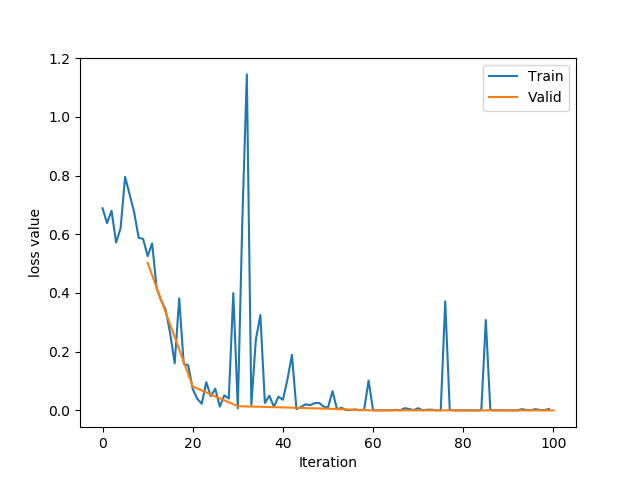
- 首先我们要设置我们硬盘中数据的路径。
- 接着
transforms用来对数据进行一些一定的预处理。resize()、缩放裁剪、然后是一个ToTensor(),把我们的图像转成张量数据。 - 接下来还是我们的重点构建在
**DataSet**和**DataLoader**。- 我们的
dataset必须是用户自己构建的。我们其中中会传入两个主要参数,一个是data_dir也是我们数据的路径;第二个transform是数据处理。这个在下一节课将会详细了解。 - 现在我们来看一下自己创建的
RMBDataset的实现。具体实现代码如下 ```python-- coding: utf-8 --
@Time : 2020年5月9日17:09:04
@Author : DarrenZhang
@FileName: train.py
@Software: PyCharm
@Blog :https://www.yuque.com/darrenzhang
@brief : 各数据集的Dataset定义
- 我们的
import os import random from PIL import Image from torch.utils.data import Dataset
random.seed(1) rmb_label = {“1”: 0, “100”: 1}
class RMBDataset(Dataset): def init(self, data_dir, transform=None): “”” rmb面额分类任务的Dataset :param data_dir: str, 数据集所在路径 :param transform: torch.transform,数据预处理 “”” self.label_name = {“1”: 0, “100”: 1} self.data_info = self.get_img_info(data_dir) # data_info存储所有图片路径和标签,在DataLoader中通过index读取样本 self.transform = transform
def __getitem__(self, index):""" 根据一个index返回数据集中的图片以及标签label:param index::return:"""path_img, label = self.data_info[index] # data_info 需要根据 index 去索取我们的图片和标签img = Image.open(path_img).convert('RGB') # 0~255if self.transform is not None:img = self.transform(img) # 在这里做transform,转为tensor等等return img, labeldef __len__(self):""":return: 返回数据的长度,样本的数量"""return len(self.data_info)@staticmethoddef get_img_info(data_dir):"""用来读取用来获取数据的路径以及标签:param data_dir: 数据路径:return:"""data_info = list()for root, dirs, _ in os.walk(data_dir):# 遍历类别for sub_dir in dirs:img_names = os.listdir(os.path.join(root, sub_dir))img_names = list(filter(lambda x: x.endswith('.jpg'), img_names))# 遍历图片for i in range(len(img_names)):img_name = img_names[i]path_img = os.path.join(root, sub_dir, img_name)label = rmb_label[sub_dir]data_info.append((path_img, int(label)))return data_info
```
- 在构建两个
DataSet一个是训练,一个是验证之后,就可以构建我们的数据迭代器DataLoader。会传入一个dataset(第三步创建好了);传入batch_size;训练集中的shuffle设置为true:每一个Epoch中的样本都是乱序的。 - 然后我们会初始化一个卷积神经网络
LeNet。这里暂时不需要关注这一个模型的具体实现。我们只需要知道模型他是这样,我们这边的x映射到我们y。 - 接着设定一个损失函数,分类任务通常采用交叉熵损失。优化器使用随机梯度下降SGD。设置好数据、模型、损失函数和优化器,就可以开始正式训练。
- 我们的训练是以
Epoch为周期,我们看到先进行一个Epoch的主循环,在每一个Epoch中会有多个循环的训练。我们在每一个iteration当中去训练我们的模型,每一次读取一个batch_size大小的数据,然后输入到模型当中进行前向传播、反向传播、获取梯度、然后更新权值。打印训练过程 - 然后在每一个
Epoch当中我们会进行一个验证集的测试。我们通过验证集来观察我们的模型是否过拟合。
从 train.py 的代码中,我们可以看到我们数据的获取是在第84行,从 data_loader 这个迭代器中不停的去获取一个 batch_size 大小的数据。下面我们就通过代码的调试来观察 PyTorch 是如何读取数据的。
我先我们在第87行上这里设置一个断点,然后执行debug。我看到跳转到了 dataloader.py 文件中276行,用来判断我们是否采用多进程。不同的读取方式有不同的读取机制。这里我们用单进程进行演示,接着执行跳入操作,跳转到 _next_data 函数 ,它会获取数据的 index 和 data 。
现在进入 _next_index() 的函数当中,看一下他是如何获取的 index 的。我们再点击一下 setp into ,进入到了 sampler.py 文件,它是一个采样器,他就是用来告诉我每一个 batch_size 单独取哪一些数据。这里我们可以跳出该函数。现在看一下变量 index 就已经挑选出来了。由于我们样本总共是160个,一个类别是80个。所以看到我们的index应该是在160以内的,batchsize=16,所以index的长度是一个16的list 。我们有了数据的 index ,接下来就是数据获取,这里会进入一个 _dataset_fetcher 。我们 setp into 这一个函数,进入到了一个叫做 _MapDatasetFetcher 类当中。我们在这个类里面实现了具体的数据读取。其中正式调用了我们的 dataset ,我们对 dataset 输入一个 index 一个索引,然后他就会返回 data 。我们把这一系列的data拼接成一个list。我们现在采用步进查看一下这个过程。我看到现在已经跳转到了我们的 my_dataset.py文件当中的 RMBDataset ,直接进入到 `_getitem()函数。在这里我已经实现了一个data_info对数据进行了初步的读取,可以得到图片的路径和标签。然后我们通过Image_open()来读取数据,这就实现了一个数据的读取以及标签的获取。我们可以跳出。在fetch()函数返回的时候,会进入一个collate_fn,它他是数据的整理器,他将我们读取到的这16个数据整理成一个batch` 的形式。
接着我们就可以返回数据。我们的data是一个list的形式。第一个元素是我们的图像,第二个元素是我们的标签。有了图像和标签我们就可以对模型进行训练。这就是 PyTorch 的数据读取机制。
通过这个代码调试,我们现在应该能回答这三个问题。第一个问题是读哪些数据,我们在代码当中看到 index 是从 Sampler 给出的。所以我们读哪些数据是要 Sampler 告诉我们的。第二个问题是从哪读数据,我们在代码当中可以看到 Dataset 里面设置一个参数 data_dir 数据存在于硬盘当中的哪一个文件夹。第三是怎么读数据,这个是在 __getitem__ 。在其中需要我们自己实现根据一个索引去读取数据。但是我们看到 DataLoader 读取数据它是很复杂。我们经过了四五个函数跳转,最终才能读取数据。
现在我们将这一个过程用流程图来表示。我们通过观察流程图来在数据读取机制有一个清晰的认识。首先我们是在for循环当中去使用我们的 DataLoader 。进入 DataLoader 之后,会根据是否采用多进程。接着进入DataLoaderIter 之后,我们会使用 Sampler去获取数据的索引。我们拿到索引之后给到我们的_dataset_fetcher,在这里面会调用我们的 DataSet ,然后在根据我们的索引,在 __getitem__ 当中,从我们的硬盘里面去读取我们实际的图像和我们的标签。我们读取了一个 batch_size 大小的数据之后,通过一个 collate_fn ,将我们这些数据进行整理,整理成一个 batch data的形式,然后就可以输入到模型中去训练了。
我们从这个流程图当中再来回答我们之前所提出的三个问题。

若有收获,就点个赞吧
0 人点赞
