核心
1、MysqlReader介绍
2、MysqlWriter介绍
3、案例测试
4、调优
5、shell给Datax的job文件传参
6、真实案例配置
Mysql Reader
1 、快速介绍
MysqlReader插件实现了从Mysql读取数据。在底层实现上,MysqlReader通过JDBC连接远程Mysql数据库,并执行相应的sql语句将数据从mysql库中SELECT出来。不同于其他关系型数据库,MysqlReader不支持FetchSize.
2、 实现原理
简而言之,MysqlReader通过JDBC连接器连接到远程的Mysql数据库,并根据用户配置的信息生成查询SELECT SQL语句,然后发送到远程Mysql数据库,并将该SQL执行返回结果使用DataX自定义的数据类型拼装为抽象的数据集,并传递给下游Writer处理。对于用户配置Table、Column、Where的信息,MysqlReader将其拼接为SQL语句发送到Mysql数据库;对于用户配置querySql信息,MysqlReader直接将其发送到Mysql数据库。
3、参数说明
- jdbcUrl
- 描述:描述的是到对端数据库的JDBC连接信息,使用JSON的数组描述,并支持一个库填写多个连接地址。之所以使用JSON数组描述连接信息,
- 必选:是
- 默认值:无
- username
- 描述:数据源的用户名
- 必选:是
- 默认值:无
- password
- 描述:数据源指定用户名的密码
- 必选:是
- 默认值:无
- table
- 描述:所选取的需要同步的表。使用JSON的数组描述,因此支持多张表同时抽取。当配置为多张表时,用户自己需保证多张表是同一schema结构,MysqlReader不予检查表是否同一逻辑表。注意,table必须包含在connection配置单元中。
- 必选:是
- 默认值:无
- column
- 描述:所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用代表默认使用所有列配置,例如[‘’]。
支持列裁剪,即列可以挑选部分列进行导出。
支持列换序,即列可以不按照表schema信息进行导出。
支持常量配置,用户需要按照Mysql SQL语法格式: [“id”, “table“, “1”, “‘bazhen.csy’”, “null”, “to_char(a + 1)”, “2.3” , “true”] id为普通列名,table为包含保留在的列名,1为整形数字常量,’bazhen.csy’为字符串常量,null为空指针,to_char(a + 1)为表达式,2.3为浮点数,true为布尔值。 - 必选:是
- 默认值:无
- 描述:所配置的表中需要同步的列名集合,使用JSON的数组描述字段信息。用户使用代表默认使用所有列配置,例如[‘’]。
- splitPk
- 描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
推荐splitPk用户使用表主键,因为表主键通常情况下比较均匀,因此切分出来的分片也不容易出现数据热点。
目前splitPk仅支持整形数据切分,不支持浮点、字符串、日期等其他类型。如果用户指定其他非支持类型,MysqlReader将报错!如果splitPk不填写,包括不提供splitPk或者splitPk值为空,DataX视作使用单通道同步该表数据。 - 必选:否
- 默认值:空
- 描述:MysqlReader进行数据抽取时,如果指定splitPk,表示用户希望使用splitPk代表的字段进行数据分片,DataX因此会启动并发任务进行数据同步,这样可以大大提供数据同步的效能。
- where
- 描述:筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。
where条件可以有效地进行业务增量同步。如果不填写where语句,包括不提供where的key或者value,DataX均视作同步全量数据。 - 必选:否
- 默认值:无
- 描述:筛选条件,MysqlReader根据指定的column、table、where条件拼接SQL,并根据这个SQL进行数据抽取。在实际业务场景中,往往会选择当天的数据进行同步,可以将where条件指定为gmt_create > $bizdate 。注意:不可以将where条件指定为limit 10,limit不是SQL的合法where子句。
- querySql
- 描述:在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项之后,DataX系统就会忽略table,column这些配置型,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
当用户配置querySql时,MysqlReader直接忽略table、column、where条件的配置,querySql优先级大于table、column、where选项。 - 必选:否
- 默认值:无
MysqlWriter
1、快速介绍
MysqlWriter 插件实现了写入数据到 Mysql 主库的目的表的功能。在底层实现上, MysqlWriter 通过 JDBC 连接远程 Mysql 数据库,并执行相应的 insert into … 或者 ( replace into …) 的 sql 语句将数据写入 Mysql,内部会分批次提交入库,需要数据库本身采用 innodb引擎。MysqlWriter 面向ETL开发工程师,他们使用 MysqlWriter 从数仓导入数据到 Mysql。同时 MysqlWriter 亦可以作为数据迁移工具为DBA等用户提供服务
- 描述:在有些业务场景下,where这一配置项不足以描述所筛选的条件,用户可以通过该配置型来自定义筛选SQL。当用户配置了这一项之后,DataX系统就会忽略table,column这些配置型,直接使用这个配置项的内容对数据进行筛选,例如需要进行多表join后同步数据,使用select a,b from table_a join table_b on table_a.id = table_b.id
2、实现原理
MysqlWriter 通过 DataX 框架获取 Reader 生成的协议数据,根据你配置的 writeMode 生成
- insert into…(当主键/唯一性索引冲突时会写不进去冲突的行)
或者
- replace into…(没有遇到主键/唯一性索引冲突时,与 insert into 行为一致,冲突时会用新行替换原有行所有字段) 的语句写入数据到 Mysql。出于性能考虑,采用了 PreparedStatement + Batch,并且设置了:rewriteBatchedStatements=true,将数据缓冲到线程上下文 Buffer 中,当 Buffer 累计到预定阈值时,才发起写入请求。
注意:目的表所在数据库必须是主库才能写入数据;整个任务至少需要具备 insert/replace
into…的权限,是否需要其他权限,取决于你任务配置中在 preSql 和 postSql 中指定的语句。
3、参数说明
jdbcUrl
描述:目的数据库的 JDBC 连接信息。作业运行时,DataX 会在你提供的 jdbcUrl 后面追加如下属性:
yearIsDateType=false&zeroDateTimeBehavior=convertToNull&rewriteBatchedStatements=true1、在一个数据库上只能配置一个 jdbcUrl 值。这与 MysqlReader支持多个备库探测不同,因为此处不支持同一个数据库存在多个主库的情况(双主导入数据情况)2、jdbcUrl按照Mysql官方规范,并可以填写连接附加控制信息,比如想指定连接编码为 gbk ,则在 jdbcUrl 后面追加属性 useUnicode=true&characterEncoding=gbk。
必选:是
- 默认值:无
- username
- 描述:目的数据库的用户名
- 必选:是
- 默认值:无
- password
- 描述:目的数据库的密码
- 必选:是
- 默认值:无
table
描述:目的表的表名称。支持写入一个或者多个表。当配置为多张表时,必须确保所有表结构保持一致。
table 和 jdbcUrl 必须包含在 connection 配置单元中
必选:是
- 默认值:无
column
描述:目的表需要写入数据的字段,字段之间用英文逗号分隔。例如: “column”: [“id”,”name”,”age”]。如果要依次写入全部列,使用表示, 例如: “column”: [“”]。 column配置项必须指定,不能留空!
1、我们强烈不推荐你这样配置,因为当你目的表字段个数、类型等有改动时,你的任务可能运行不正确或者失败
2、 column 不能配置任何常量值必选:是
- 默认值:无
- session
- 描述:DataX在获取Mysql连接时,执行session指定的SQL语句,修改当前connection session属性
- 必选:否
- 默认值:空
- preSql
- 描述:写入数据到目的表前,会先执行这里的标准语句。如果 Sql 中有你需要操作到的表名称,这样在实际执行 Sql 语句时,会对变量按照实际表名称进行替换。比如你的任务是要写入到目的端的100个同构分表(表名称为:datax_00,datax01, … datax_98,datax_99),并且你希望导入数据前,先对表中数据进行删除操作,那么你可以这样配置:”preSql”:[“delete from 表名”],效果是:在执行到每个表写入数据前,会先执行对应的 delete from 对应表名称
- 必选:否
- 默认值:无
- postSql
- 描述:写入数据到目的表后,会执行这里的标准语句。(原理同 preSql )
- 必选:否
- 默认值:无
- writeMode
- 描述:控制写入数据到目标表采用 insert into 或者 replace into 或者 ON DUPLICATE KEY UPDATE 语句
- 必选:是
- 所有选项:insert/replace/update
- 默认值:insert
- batchSize
insert into datax(id,name,bir_date) values(1,”xlucas”,”2011-10-24 17:56:34”); insert into datax(id,name,bir_date) values(2,”xlucas1”,”2012-10-24 17:56:34”); insert into datax(id,name,bir_date) values(3,”xlucas2”,”2013-10-24 17:56:34”); insert into datax(id,name,bir_date) values(4,”xlucas3”,”2014-10-24 17:56:34”);
<a name="GYxio"></a>## datax job准备(输出)```json{"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","column": [ "id", "name", "bir_date" ],"splitPk": "id","connection": [ { "table": [ "datax" ], "jdbcUrl": [ "jdbc:mysql://192.168.18.160/datax" ] } ] }},"writer": {"name": "streamwriter","parameter": {"print":true }}}]}}
这个是直接打印在终端上面
[hadoop@cdh2 bin]$ python datax.py ../job/mysql1.jsonDataX (DATAX-OPENSOURCE-3.0), From Alibaba !Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2018-03-18 23:16:14.084 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl2018-03-18 23:16:14.134 [main] INFO Engine - the machine info =>osInfo: Oracle Corporation 1.8 25.111-b14jvmInfo: Linux amd64 2.6.32-431.el6.x86_64cpu num: 6totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_sizePS Eden Space | 256.00MB | 256.00MBCode Cache | 240.00MB | 2.44MBCompressed Class Space | 1,024.00MB | 0.00MBPS Survivor Space | 42.50MB | 42.50MBPS Old Gen | 683.00MB | 683.00MBMetaspace | -0.00MB | 0.00MB2018-03-18 23:16:14.239 [main] INFO Engine -{"content":[{"reader":{"name":"mysqlreader","parameter":{"column":["id","name","bir_date"],"connection":[{"jdbcUrl":["jdbc:mysql://192.168.18.160/datax"],"table":["datax"]}],"password":"******","splitPk":"id","username":"root"}},"writer":{"name":"streamwriter","parameter":{"print":true}}}],"setting":{"errorLimit":{"percentage":0.02,"record":0},"speed":{"channel":3}}}2018-03-18 23:16:14.315 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null2018-03-18 23:16:14.320 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=02018-03-18 23:16:14.320 [main] INFO JobContainer - DataX jobContainer starts job.2018-03-18 23:16:14.326 [main] INFO JobContainer - Set jobId = 02018-03-18 23:16:15.682 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.2018-03-18 23:16:15.719 [job-0] INFO OriginalConfPretreatmentUtil - table:[datax] has columns:[id,name,bir_date].2018-03-18 23:16:15.757 [job-0] INFO JobContainer - jobContainer starts to do prepare ...2018-03-18 23:16:15.758 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .2018-03-18 23:16:15.759 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do prepare work .2018-03-18 23:16:15.759 [job-0] INFO JobContainer - jobContainer starts to do split ...2018-03-18 23:16:15.759 [job-0] INFO JobContainer - Job set Channel-Number to 3 channels.2018-03-18 23:16:15.773 [job-0] INFO SingleTableSplitUtil - split pk [sql=SELECT MIN(id),MAX(id) FROM datax] is running...2018-03-18 23:16:15.843 [job-0] INFO SingleTableSplitUtil - After split(), allQuerySql=[select id,name,bir_date from datax where (1 <= id AND id < 2)select id,name,bir_date from datax where (2 <= id AND id < 3)select id,name,bir_date from datax where (3 <= id AND id <= 4)select id,name,bir_date from datax where id IS NULL].2018-03-18 23:16:15.843 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [4] tasks.2018-03-18 23:16:15.844 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] splits to [4] tasks.2018-03-18 23:16:15.874 [job-0] INFO JobContainer - jobContainer starts to do schedule ...2018-03-18 23:16:15.892 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.2018-03-18 23:16:15.895 [job-0] INFO JobContainer - Running by standalone Mode.2018-03-18 23:16:15.912 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [3] channels for [4] tasks.2018-03-18 23:16:15.925 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.2018-03-18 23:16:15.925 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.2018-03-18 23:16:15.950 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[3] attemptCount[1] is started2018-03-18 23:16:15.961 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started2018-03-18 23:16:15.973 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[2] attemptCount[1] is started2018-03-18 23:16:15.974 [0-0-3-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where id IS NULL] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:16:15.991 [0-0-2-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where (3 <= id AND id <= 4)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:16:15.991 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where (1 <= id AND id < 2)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:16:16.005 [0-0-3-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where id IS NULL] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:16:16.023 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where (1 <= id AND id < 2)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:16:16.027 [0-0-2-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where (3 <= id AND id <= 4)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].1 xlucas 2011-10-24 17:56:343 xlucas2 2013-10-24 17:56:344 xlucas3 2014-10-24 17:56:342018-03-18 23:16:16.175 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[222]ms2018-03-18 23:16:16.175 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[2] is successed, used[202]ms2018-03-18 23:16:16.178 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] attemptCount[1] is started2018-03-18 23:16:16.190 [0-0-1-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where (2 <= id AND id < 3)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:16:16.203 [0-0-1-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where (2 <= id AND id < 3)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2 xlucas1 2012-10-24 17:56:342018-03-18 23:16:16.279 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] is successed, used[101]ms2018-03-18 23:16:16.280 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[3] is successed, used[340]ms2018-03-18 23:16:16.281 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.2018-03-18 23:16:25.917 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 63 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.054s | Percentage 100.00%2018-03-18 23:16:25.918 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.2018-03-18 23:16:25.920 [job-0] INFO JobContainer - DataX Writer.Job [streamwriter] do post work.2018-03-18 23:16:25.921 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.2018-03-18 23:16:25.922 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.2018-03-18 23:16:25.925 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/datax/hook2018-03-18 23:16:25.928 [job-0] INFO JobContainer -[total cpu info] =>averageCpu | maxDeltaCpu | minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info] =>NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTimePS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000sPS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s2018-03-18 23:16:25.928 [job-0] INFO JobContainer - PerfTrace not enable!2018-03-18 23:16:25.930 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 63 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.054s | Percentage 100.00%2018-03-18 23:16:25.933 [job-0] INFO JobContainer -任务启动时刻 : 2018-03-18 23:16:14任务结束时刻 : 2018-03-18 23:16:25任务总计耗时 : 11s任务平均流量 : 6B/s记录写入速度 : 0rec/s读出记录总数 : 4读写失败总数 : 0
datax job准备(数据读写)
{"job": {"setting": {"speed": {"channel": 3},"errorLimit": {"record": 0,"percentage": 0.02}},"content": [{"reader": {"name": "mysqlreader","parameter": {"username": "root","password": "123456","column": [ "id", "name", "bir_date" ],"splitPk": "id","connection": [ { "table": [ "datax" ], "jdbcUrl": [ "jdbc:mysql://192.168.18.160/datax" ] } ] }},"writer": {"name": "mysqlwriter","parameter": {"writeMode": "insert","username": "root","password": "123456","column": [ "id", "name", "bir_date" ],"session": [ "set session sql_mode='ANSI'" ],"preSql": [ "delete from datax1" ],"connection": [ { "jdbcUrl": "jdbc:mysql://192.168.18.160/datax?useUnicode=true&characterEncoding=gbk", "table": [ "datax1" ] } ] }}}]}}
从mysql中读取出来,写入到另外一个表里面
[hadoop@cdh2 bin]$ python datax.py ../job/mysql.jsonDataX (DATAX-OPENSOURCE-3.0), From Alibaba !Copyright (C) 2010-2017, Alibaba Group. All Rights Reserved.2018-03-18 23:22:33.014 [main] INFO VMInfo - VMInfo# operatingSystem class => sun.management.OperatingSystemImpl2018-03-18 23:22:33.023 [main] INFO Engine - the machine info =>osInfo: Oracle Corporation 1.8 25.111-b14jvmInfo: Linux amd64 2.6.32-431.el6.x86_64cpu num: 6totalPhysicalMemory: -0.00GfreePhysicalMemory: -0.00GmaxFileDescriptorCount: -1currentOpenFileDescriptorCount: -1GC Names [PS MarkSweep, PS Scavenge]MEMORY_NAME | allocation_size | init_sizePS Eden Space | 256.00MB | 256.00MBCode Cache | 240.00MB | 2.44MBCompressed Class Space | 1,024.00MB | 0.00MBPS Survivor Space | 42.50MB | 42.50MBPS Old Gen | 683.00MB | 683.00MBMetaspace | -0.00MB | 0.00MB2018-03-18 23:22:33.049 [main] INFO Engine -{"content":[{"reader":{"name":"mysqlreader","parameter":{"column":["id","name","bir_date"],"connection":[{"jdbcUrl":["jdbc:mysql://192.168.18.160/datax"],"table":["datax"]}],"password":"******","splitPk":"id","username":"root"}},"writer":{"name":"mysqlwriter","parameter":{"column":["id","name","bir_date"],"connection":[{"jdbcUrl":"jdbc:mysql://192.168.18.160/datax?useUnicode=true&characterEncoding=gbk","table":["datax1"]}],"password":"******","preSql":["delete from datax1"],"session":["set session sql_mode='ANSI'"],"username":"root","writeMode":"insert"}}}],"setting":{"errorLimit":{"percentage":0.02,"record":0},"speed":{"channel":3}}}2018-03-18 23:22:33.073 [main] WARN Engine - prioriy set to 0, because NumberFormatException, the value is: null2018-03-18 23:22:33.075 [main] INFO PerfTrace - PerfTrace traceId=job_-1, isEnable=false, priority=02018-03-18 23:22:33.075 [main] INFO JobContainer - DataX jobContainer starts job.2018-03-18 23:22:33.078 [main] INFO JobContainer - Set jobId = 02018-03-18 23:22:33.518 [job-0] INFO OriginalConfPretreatmentUtil - Available jdbcUrl:jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.2018-03-18 23:22:33.541 [job-0] INFO OriginalConfPretreatmentUtil - table:[datax] has columns:[id,name,bir_date].2018-03-18 23:22:34.197 [job-0] INFO OriginalConfPretreatmentUtil - table:[datax1] all columns:[id,name,bir_date].2018-03-18 23:22:34.210 [job-0] INFO OriginalConfPretreatmentUtil - Write data [insert INTO %s (id,name,bir_date) VALUES(?,?,?)], which jdbcUrl like:[jdbc:mysql://192.168.18.160/datax?useUnicode=true&characterEncoding=gbk&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true]2018-03-18 23:22:34.210 [job-0] INFO JobContainer - jobContainer starts to do prepare ...2018-03-18 23:22:34.211 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do prepare work .2018-03-18 23:22:34.211 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do prepare work .2018-03-18 23:22:34.222 [job-0] INFO CommonRdbmsWriter$Job - Begin to execute preSqls:[delete from datax1]. context info:jdbc:mysql://192.168.18.160/datax?useUnicode=true&characterEncoding=gbk&yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true.2018-03-18 23:22:34.223 [job-0] INFO JobContainer - jobContainer starts to do split ...2018-03-18 23:22:34.224 [job-0] INFO JobContainer - Job set Channel-Number to 3 channels.2018-03-18 23:22:34.236 [job-0] INFO SingleTableSplitUtil - split pk [sql=SELECT MIN(id),MAX(id) FROM datax] is running...2018-03-18 23:22:34.259 [job-0] INFO SingleTableSplitUtil - After split(), allQuerySql=[select id,name,bir_date from datax where (1 <= id AND id < 2)select id,name,bir_date from datax where (2 <= id AND id < 3)select id,name,bir_date from datax where (3 <= id AND id <= 4)select id,name,bir_date from datax where id IS NULL].2018-03-18 23:22:34.260 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] splits to [4] tasks.2018-03-18 23:22:34.261 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] splits to [4] tasks.2018-03-18 23:22:34.285 [job-0] INFO JobContainer - jobContainer starts to do schedule ...2018-03-18 23:22:34.293 [job-0] INFO JobContainer - Scheduler starts [1] taskGroups.2018-03-18 23:22:34.296 [job-0] INFO JobContainer - Running by standalone Mode.2018-03-18 23:22:34.306 [taskGroup-0] INFO TaskGroupContainer - taskGroupId=[0] start [3] channels for [4] tasks.2018-03-18 23:22:34.310 [taskGroup-0] INFO Channel - Channel set byte_speed_limit to -1, No bps activated.2018-03-18 23:22:34.310 [taskGroup-0] INFO Channel - Channel set record_speed_limit to -1, No tps activated.2018-03-18 23:22:34.320 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] attemptCount[1] is started2018-03-18 23:22:34.324 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] attemptCount[1] is started2018-03-18 23:22:34.327 [0-0-0-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where (1 <= id AND id < 2)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.327 [0-0-1-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where (2 <= id AND id < 3)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.328 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[2] attemptCount[1] is started2018-03-18 23:22:34.335 [0-0-2-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where (3 <= id AND id <= 4)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.335 [0-0-1-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.347 [0-0-0-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.356 [0-0-1-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.356 [0-0-1-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where (2 <= id AND id < 3)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.356 [0-0-2-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where (3 <= id AND id <= 4)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.367 [0-0-2-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.379 [0-0-0-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where (1 <= id AND id < 2)] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.384 [0-0-0-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.391 [0-0-2-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.430 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[0] is successed, used[107]ms2018-03-18 23:22:34.431 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[1] is successed, used[113]ms2018-03-18 23:22:34.431 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[2] is successed, used[104]ms2018-03-18 23:22:34.434 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[3] attemptCount[1] is started2018-03-18 23:22:34.455 [0-0-3-reader] INFO CommonRdbmsReader$Task - Begin to read record by Sql: [select id,name,bir_date from datax where id IS NULL] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.465 [0-0-3-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.467 [0-0-3-reader] INFO CommonRdbmsReader$Task - Finished read record by Sql: [select id,name,bir_date from datax where id IS NULL] jdbcUrl:[jdbc:mysql://192.168.18.160/datax?yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true].2018-03-18 23:22:34.475 [0-0-3-writer] INFO DBUtil - execute sql:[set session sql_mode='ANSI']2018-03-18 23:22:34.535 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] taskId[3] is successed, used[101]ms2018-03-18 23:22:34.536 [taskGroup-0] INFO TaskGroupContainer - taskGroup[0] completed it's tasks.2018-03-18 23:22:44.320 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 63 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%2018-03-18 23:22:44.321 [job-0] INFO AbstractScheduler - Scheduler accomplished all tasks.2018-03-18 23:22:44.322 [job-0] INFO JobContainer - DataX Writer.Job [mysqlwriter] do post work.2018-03-18 23:22:44.323 [job-0] INFO JobContainer - DataX Reader.Job [mysqlreader] do post work.2018-03-18 23:22:44.324 [job-0] INFO JobContainer - DataX jobId [0] completed successfully.2018-03-18 23:22:44.326 [job-0] INFO HookInvoker - No hook invoked, because base dir not exists or is a file: /opt/datax/hook2018-03-18 23:22:44.329 [job-0] INFO JobContainer -[total cpu info] =>averageCpu | maxDeltaCpu | minDeltaCpu-1.00% | -1.00% | -1.00%[total gc info] =>NAME | totalGCCount | maxDeltaGCCount | minDeltaGCCount | totalGCTime | maxDeltaGCTime | minDeltaGCTimePS MarkSweep | 0 | 0 | 0 | 0.000s | 0.000s | 0.000sPS Scavenge | 0 | 0 | 0 | 0.000s | 0.000s | 0.000s2018-03-18 23:22:44.329 [job-0] INFO JobContainer - PerfTrace not enable!2018-03-18 23:22:44.331 [job-0] INFO StandAloneJobContainerCommunicator - Total 4 records, 63 bytes | Speed 6B/s, 0 records/s | Error 0 records, 0 bytes | All Task WaitWriterTime 0.000s | All Task WaitReaderTime 0.000s | Percentage 100.00%2018-03-18 23:22:44.333 [job-0] INFO JobContainer -任务启动时刻 : 2018-03-18 23:22:33任务结束时刻 : 2018-03-18 23:22:44任务总计耗时 : 11s任务平均流量 : 6B/s记录写入速度 : 0rec/s读出记录总数 : 4读写失败总数 : 0
调优
Datax日志
接下来直接看datax日志最后打印的统计日志。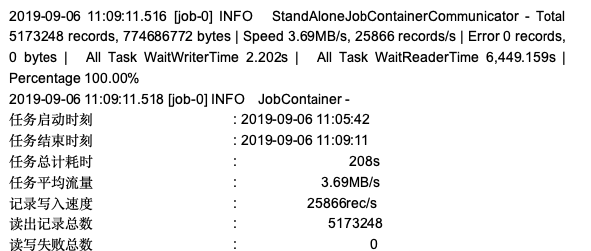
可以很明显的看到datax给我们的提示是:
All Task WaitReaderTime 6449.159s ,All Task WaitWriterTime 2.202s
定位的重点需要看一下datax对于rds的读取逻辑,看看是不是有提升的空间。看task源码后得知,datax本身是额外加了一些监控设置的,但默认不开启的,因此需要改一下{datax-path}/conf/core.json配置文件将其开启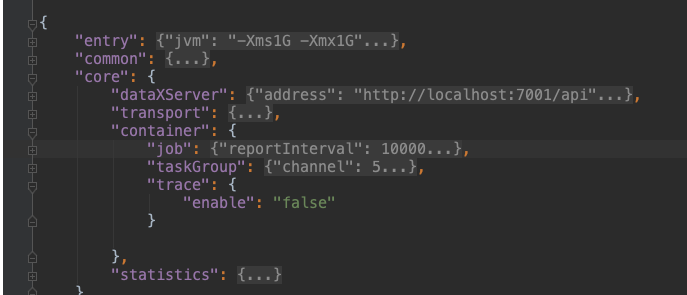
将trace :enable改为true,重跑一下任务可以看到更加详细的日志文件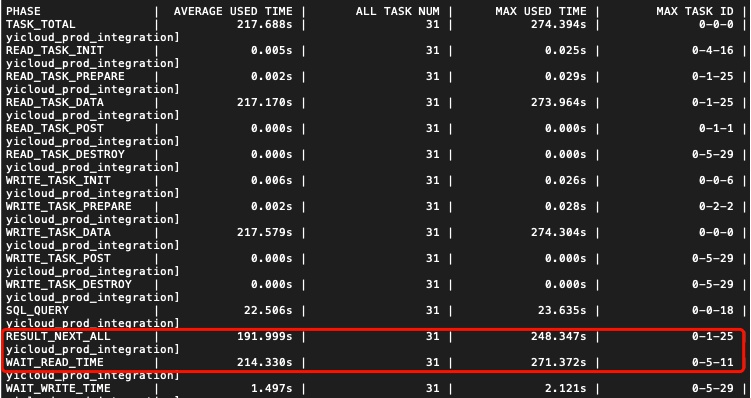
发现是RESULT_NEXT_ALL平均耗时在191秒,最大的一个任务耗时248秒。全局搜索一下这个参数,可以定位到这个是统计了CommonRdbmsReader中rs.next()的时间。
进入到Mysql driver的源码底层,发现当fetchSize值为Integer.MIN_VALUE时,每次都只从服务器获取一条记录,因此顺着这个思路需要验证下最终是不是走的这个逻辑。
package com.mysql.jdbc;public class RowDataCursor implements RowData {private void fetchMoreRows() throws SQLException {if (this.lastRowFetched) {this.fetchedRows = new ArrayList<ResultSetRow>(0);return;}synchronized (this.owner.connection.getConnectionMutex()) {boolean oldFirstFetchCompleted = this.firstFetchCompleted;if (!this.firstFetchCompleted) {this.firstFetchCompleted = true;}int numRowsToFetch = this.owner.getFetchSize();if (numRowsToFetch == 0) {numRowsToFetch = this.prepStmt.getFetchSize();}if (numRowsToFetch == Integer.MIN_VALUE) {// Handle the case where the user used 'old'// streaming result setsnumRowsToFetch = 1;}this.fetchedRows = this.mysql.fetchRowsViaCursor(this.fetchedRows,this.statementIdOnServer, this.metadata, numRowsToFetch,this.useBufferRowExplicit);this.currentPositionInFetchedRows = BEFORE_START_OF_ROWS;if ((this.mysql.getServerStatus() & SERVER_STATUS_LAST_ROW_SENT) != 0) {this.lastRowFetched = true;if (!oldFirstFetchCompleted && this.fetchedRows.size() == 0) {this.wasEmpty = true;}}}}}
因此接下来主要的代码逻辑需要重新梳理一下这个fetchSize是怎么一步步传下来的。所以从Datax Reader开始看看有没有设置fetchSize的地方(重点需要查看的代码逻辑:MysqlReader.task->CommonRdbmsReader.task)
Datax-MysqlReader
注:以下代码经过删减,为了方便查看。
先看MysqlReader,果然它在init时做了一步操作,直接忽略用户设置的fetSize任何值,将fetchSize默认配置成了 Inter.MIN_VALUE,并且在task中将其取了出来。(主要注意的是:虽说job中的conf和task的conf名称不一样,但值是一样的都是 super.getPluginJobConf()而来,因此在job初始化时,就已经默认将fetchsize设置成了int的最小值)
package com.alibaba.datax.plugin.reader.mysqlreader;public class MysqlReader extends Reader {private static final DataBaseType DATABASE_TYPE = DataBaseType.MySql;public static class Job extends Reader.Job {private static final Logger LOG = LoggerFactory.getLogger(Job.class);@Overridepublic void init() {this.originalConfig = super.getPluginJobConf();Integer userConfigedFetchSize = this.originalConfig.getInt(Constant.FETCH_SIZE);if (userConfigedFetchSize != null) {LOG.warn("对 mysqlreader 不需要配置 fetchSize, mysqlreader 将会忽略这项配置. 如果您不想再看到此警告,请去除fetchSize 配置.");}this.originalConfig.set(Constant.FETCH_SIZE, Integer.MIN_VALUE);this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DATABASE_TYPE);this.commonRdbmsReaderJob.init(this.originalConfig);}}public static class Task extends Reader.Task {@Overridepublic void init() {this.readerSliceConfig = super.getPluginJobConf();this.commonRdbmsReaderTask = new CommonRdbmsReader.Task(DATABASE_TYPE, super.getTaskGroupId(), super.getTaskId());this.commonRdbmsReaderTask.init(this.readerSliceConfig);}@Overridepublic void startRead(RecordSender recordSender) {int fetchSize = this.readerSliceConfig.getInt(Constant.FETCH_SIZE);this.commonRdbmsReaderTask.startRead(this.readerSliceConfig, recordSender,super.getTaskPluginCollector(), fetchSize);}}}
可以看到mysqlReaderTask初始化之后,最终走的是commRdbmsReaderTask.startRead方法。
package com.alibaba.datax.plugin.rdbms.reader;public class CommonRdbmsReader {public static class Task {public void startRead(Configuration readerSliceConfig,RecordSender recordSender,TaskPluginCollector taskPluginCollector, int fetchSize) {String querySql = readerSliceConfig.getString(Key.QUERY_SQL);String table = readerSliceConfig.getString(Key.TABLE);PerfTrace.getInstance().addTaskDetails(taskId, table + "," + basicMsg);LOG.info("Begin to read record by Sql: [{}\n] {}.",querySql, basicMsg);PerfRecord queryPerfRecord = new PerfRecord(taskGroupId,taskId, PerfRecord.PHASE.SQL_QUERY);queryPerfRecord.start();Connection conn = DBUtil.getConnection(this.dataBaseType, jdbcUrl,username, password);// session config .etc relatedDBUtil.dealWithSessionConfig(conn, readerSliceConfig,this.dataBaseType, basicMsg);int columnNumber = 0;ResultSet rs = null;try {rs = DBUtil.query(conn, querySql, fetchSize);queryPerfRecord.end();ResultSetMetaData metaData = rs.getMetaData();columnNumber = metaData.getColumnCount();//这个统计干净的result_Next时间PerfRecord allResultPerfRecord = new PerfRecord(taskGroupId, taskId, PerfRecord.PHASE.RESULT_NEXT_ALL);allResultPerfRecord.start();long rsNextUsedTime = 0;long lastTime = System.nanoTime();while (rs.next()) {rsNextUsedTime += (System.nanoTime() - lastTime);this.transportOneRecord(recordSender, rs,metaData, columnNumber, mandatoryEncoding, taskPluginCollector);lastTime = System.nanoTime();}allResultPerfRecord.end(rsNextUsedTime);//目前大盘是依赖这个打印,而之前这个Finish read record是包含了sql查询和result next的全部时间LOG.info("Finished read record by Sql: [{}\n] {}.",querySql, basicMsg);}catch (Exception e) {throw RdbmsException.asQueryException(this.dataBaseType, e, querySql, table, username);} finally {DBUtil.closeDBResources(null, conn);}}protected Record transportOneRecord(RecordSender recordSender, ResultSet rs,ResultSetMetaData metaData, int columnNumber, String mandatoryEncoding,TaskPluginCollector taskPluginCollector) {Record record = buildRecord(recordSender,rs,metaData,columnNumber,mandatoryEncoding,taskPluginCollector);recordSender.sendToWriter(record);return record;}}
接着再看fetchSize传入到了DBUtil.query中
DBUtil.java:
public static ResultSet query(Connection conn, String sql, int fetchSize, int queryTimeout)throws SQLException {// make sure autocommit is offconn.setAutoCommit(false);Statement stmt = conn.createStatement(ResultSet.TYPE_FORWARD_ONLY,ResultSet.CONCUR_READ_ONLY);stmt.setFetchSize(fetchSize);stmt.setQueryTimeout(queryTimeout);return query(stmt, sql);}
将fetchSize=Integer.MIN_VALUE值设置到了Statement 中,并且通过游标的方式去服务器端获取结果。
至此结合最开始看的mysql driver底层,就可得知当fetchSize=Integer.MIN_VALUE时,导致每次从外网读取rds记录时,是以每次一条去获取,会浪费大量的网络开销,因此解决方案就是将fetchSize值改大,减少取数据时的网络开销。
结合网上查阅资料:mysql的jdbc中fetchsize支持的问题
下边开始调整:
1、修改MysqlReader代码使其能够使用用户自定义配置,而不是粗暴的都走fetchSize=Integer.MIN_VALUE
需要调整MysqlReader代码,加个判断逻辑,如果driver版本低于5.0的还是走默认的fetchSize(当然如果你的Mysql 服务的版本低于5.0,即使用的高版本驱动,fetchSize也可能不生效),否则可以使用用户自定义配置的fetchSize去取数据。这里如果确定了版本,把那行默认设置的代码直接删了也是可以的。
public static class Job extends Reader.Job {@Overridepublic void init() {this.originalConfig = super.getPluginJobConf();Integer userConfigedFetchSize = this.originalConfig.getInt(Constant.FETCH_SIZE);if("5.0".compareTo(Driver.VERSION) > 0 ){if (userConfigedFetchSize != null) {LOG.warn("对mysql版本低于5.0的 mysqlreader 不需要配置 fetchSize, mysqlreader 将会忽略这项配置. 如果您不想再看到此警告,请去除fetchSize 配置.");}this.originalConfig.set(Constant.FETCH_SIZE, Integer.MIN_VALUE);}this.commonRdbmsReaderJob = new CommonRdbmsReader.Job(DATABASE_TYPE);this.commonRdbmsReaderJob.init(this.originalConfig);}}
接着修改自己的job.json去指定一个fetchSize值
{"job": {"content": [{"reader": {"parameter": {"modifyUserName": "","password": "","column": [],"connection": [{"jdbcUrl": [],"table": []}],"username": "root","fetchSize": 5000},"name": "mysqlreader"},"writer": {"parameter": {},"name": ""}}],"setting": {"errorLimit": {"record": 0},"speed": {"channel": 5,"throttle": false}}}}
2、修改运行的job.json或者修改datax源码方式,去修改jdbc连接参数
在DataBaseType里可以看到datax默认会为我们加上一系列参数,因此很简单,我们只需要在后边加上
&useCursorFetch=true
package com.alibaba.datax.plugin.rdbms.util;import com.alibaba.datax.common.exception.DataXException;import java.util.regex.Matcher;import java.util.regex.Pattern;/*** refer:http://blog.csdn.net/ring0hx/article/details/6152528* <p/>*/public enum DataBaseType {public String appendJDBCSuffixForReader(String jdbc) {String result = jdbc;String suffix = null;switch (this) {case MySql:case DRDS:suffix = "yearIsDateType=false&zeroDateTimeBehavior=convertToNull&tinyInt1isBit=false&rewriteBatchedStatements=true&useCursorFetch=true";if (jdbc.contains("?")) {result = jdbc + "&" + suffix;} else {result = jdbc + "?" + suffix;}break;case Oracle:break;case SQLServer:break;case DB2:break;case PostgreSQL:break;case RDBMS:break;case HANA:break;case ELK:break;default:throw DataXException.asDataXException(DBUtilErrorCode.UNSUPPORTED_TYPE, "unsupported database type.");}return result;}}
优化效果
自己配置的fetchSize。看一下优化后的效果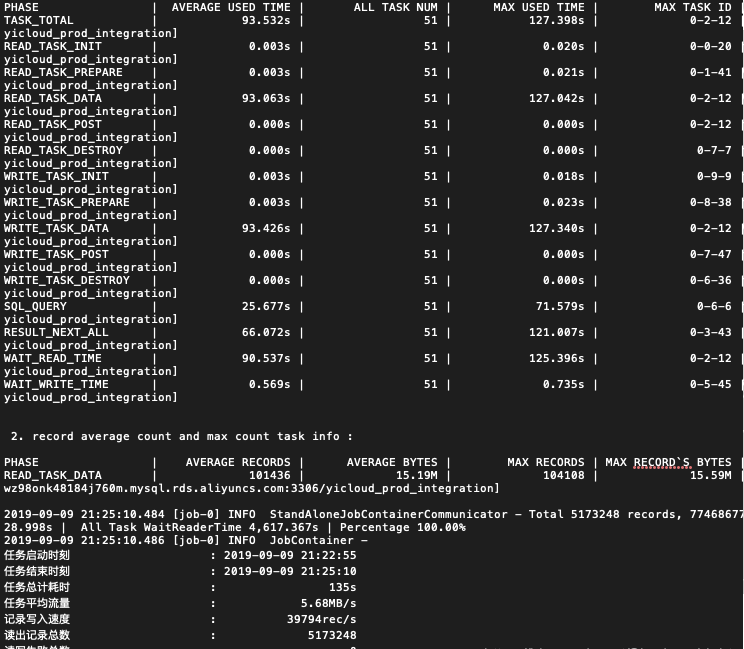
效果还是挺明显的,从212s提升到135s,但继续增加fetchSize提升也不是很明显。在大佬的提醒下,mysql在网络传输时应该有压缩的策略。因此网上找了一下jdbc连接参数里有没有,找到了另一个参数useCompression默认还是关闭的状态。
&useCompression=true

所以立马将这个参数也加到了代码中,运行测试一下。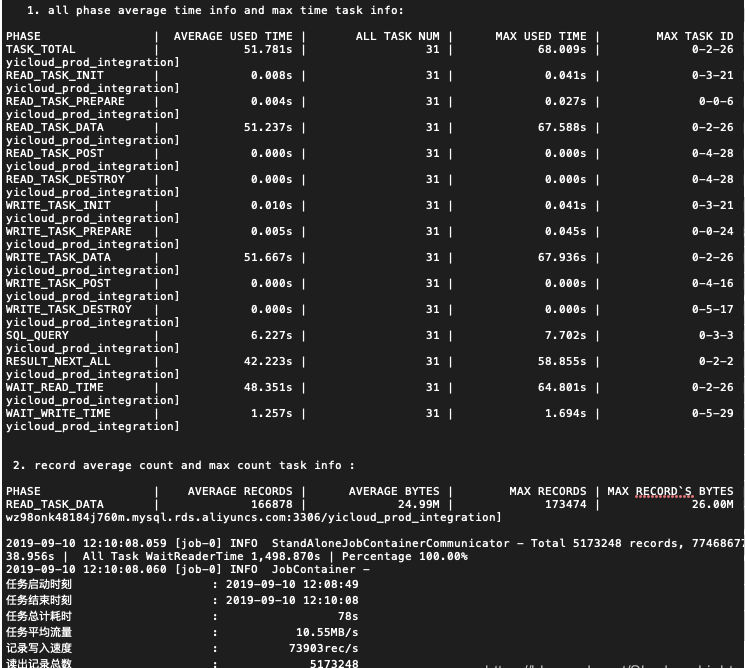
运行时间又从135s缩减到了78s,效果也是很明显的。
Shell脚本给DataX的job文件传参
由于要求每次导入Mongo的是增量的数据,但HDFS中没有相应的字段对数据进行标识哪些是新增的。需要依据相应的策略去判断相应的增量数据。
通过Hive的SQL将每天的全量数据与历史的增量数据进行关联(LEFT OUTER JOIN)where条件是右表的关联字段IS NULL,而关联条件是基于判重的字段组合生成MD5,以md5进行数据是否是新增数据的判断依据。
SELECT*FROM olap.community_six t1LEFT JOIN olap.community_six_inc t2 ON t1.md5 = t2.md5
得到新增数据后,写入以日期为分区字段的新增数据表相应的分区中。通过DataX抽取增量数据写入Mongo,但是要求每天读取当天的分区,避免导入重复的数据。
以下为shell脚本:
#!/bin/bashTODAY=`date +"%Y-%m-%d"`python /export/servers/datax/bin/datax.py -p "-DTODAY=${TODAY}" \/export/servers/datax/job/deal.json
以下为DataX的job文件中需要传入动态参数的地方:
"reader": {"name": "hdfsreader","parameter": {"path":"/user/hive/warehouse/olap.db/community_six/update_date=${TODAY}/*","defaultFS": "hdfs://10.66.202.88:9000"
真实案例配置
{"job":{"setting":{"speed":{"channel": 8,"record":-1,"byte":-1,"batchSize":2048}},"content":[{"reader":{"name":"mysqlreader","parameter":{"username":"qaqcsync","password":"Jingye-00","column":["recid","orgid","projectid","type","blockid","blockname","floorcnt","unitscnt","images","$createUser","$createDept","now()","$createUser","now()","1","0","$projectid","0"],"where":"projectid='$where'","connection":[{"table":["basedata_blocklist"],"jdbcUrl":["jdbc:mysql://192.168.102.205:3306/aiis?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&serverTimezone=GMT%2B8&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true"]}]}},"writer":{"name":"mysqlwriter","parameter":{"writeMode":"insert","username":"qcdm","password":"Hzky@2020","column":["rec_id","org_code","project_code","type","block_code","block_name","floor_cnt","units_cnt","images","create_user","create_dept","create_time","update_user","update_time","status","is_deleted","project_id","sort"],"preSql":["update qcdm_project_block set qcdm_project_block.is_deleted=1 where qcdm_project_block.project_code='$where' AND qcdm_project_block.is_deleted=0 AND qcdm_project_block.project_id='$projectid' AND qcdm_project_block.project_code='$where'"],"postSql":["update qcdm_project_block set qcdm_project_block.building_code=CONCAT(qcdm_project_block.project_code,'-',qcdm_project_block.block_code) where qcdm_project_block.is_deleted=0 and qcdm_project_block.project_code='$where' and qcdm_project_block.project_id='$projectid'","insert into qcdm_project_sycn_logs VALUES(0,now())"],"connection":[{"jdbcUrl":"jdbc:mysql://192.168.102.208:3306/qcdm?useSSL=false&useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&serverTimezone=GMT%2B8&nullCatalogMeansCurrent=true&allowPublicKeyRetrieval=true","table":["qcdm_project_block"]}]}}}]}}

若有收获,就点个赞吧
0 人点赞
