1 Solr介绍
1.1 什么是solr?
Solr 是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML文件,生成索引;也可以通过Http Get操作提出查找请求,并得到XML格式的返回结果。
Solr 是 apache 的顶级开源项目,它是使用java开发 ,基于lucene的全文检索服务器。
Solr 比 lucene 提供了更多的查询语句,而且它可扩展、可配置,同时它对 lucene 的性能进行了优化。
Solr 是如何实现全文检索的呢?
1,索引流程:solr客户端(浏览器、java程序)可以向solr服务端发送POST请求,请求内容是包含Field等信息的一个xml文档,通过该文档,solr实现对索引的维护(增删改)2,搜索流程:solr客户端(浏览器、java程序)可以向solr服务端发送GET请求,solr服务器返回一个xml/json文档。
1.2 Solr和lucene的区别
lucene 是一个全文检索引擎工具包,它只是一个jar包,不能独立运行,对外提供服务。
Solr 是一个全文检索服务器,它可以单独运行在 servlet 容器,可以单独对外提供搜索和索引功能。 Solr 比 lucene 在开发全文检索功能时,更快捷、更方便。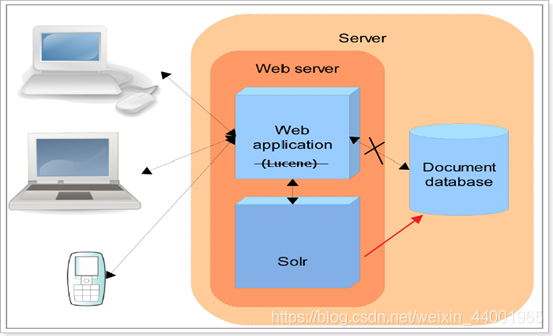
2 Solr安装配置
2.1 下载solr
Solr和lucene的版本是同步更新的,最新的版本是8.1.0/
本课程使用的版本:8.11.1
下载地址:https://www.apache.org/dyn/closer.lua/lucene/solr/8.11.1/solr-8.11.1.zip?action=download
下载版本:8.11.1
- src.tgz:带src表示是带源码文件的压缩包,无src是已经编译过的压缩包
- .tgz:Linux相关操作系统使用的压缩包
- .zip:Windows操作系统使用的压缩包
2.2 启动Solr

solr的启动、停止、查看命令:
- 启动:bin\solr.cmd start 或者 bin\solr.cmd start -m 4g (对于可能出现的outofMer…Exception)
- 停止:bin\solr stop 或bin\solr stop -all
- 查看:bin\solr status
访问地址:http://localhost:8983/solr/#/
2.4 solr界面介绍
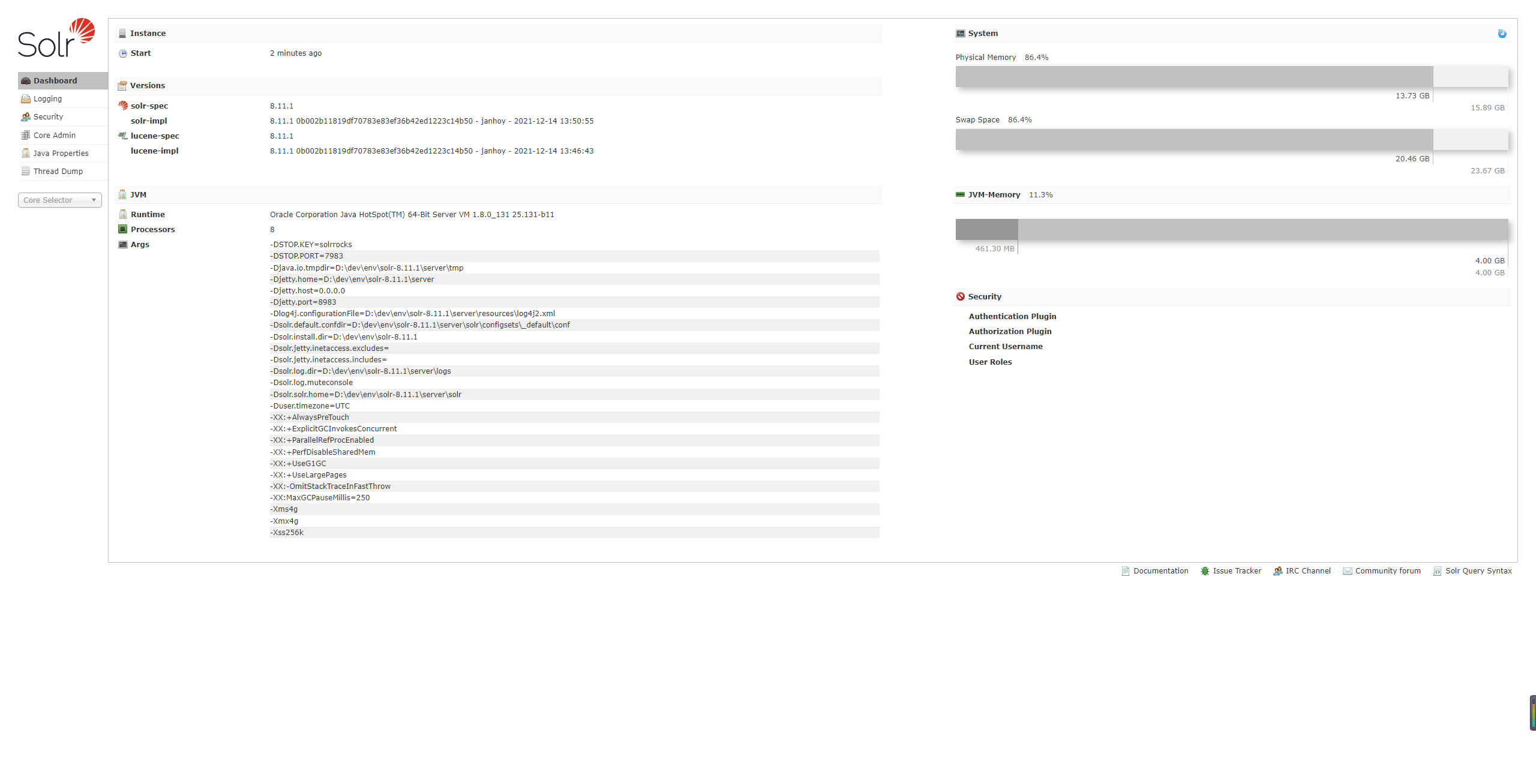
2.4.1 Dashboard
仪表盘,显示了该Solr实例开始启动运行的时间、版本、系统资源、jvm等信息。
2.4.2 Logging
显示solr运行出现的异常或错误
2.4.3 Core Admin
Solr Core的管理界面。在这里可以添加SolrCore实例。
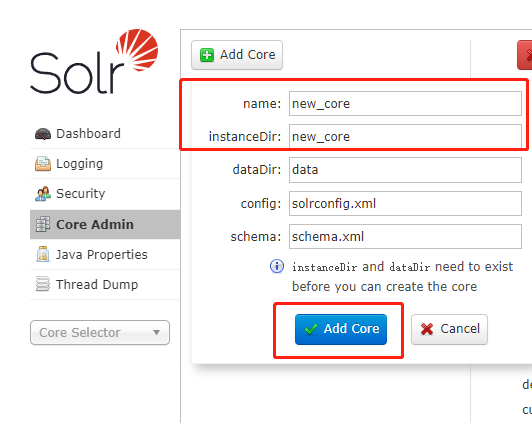
主要有Add Core(添加核心), Unload(卸载核心),Rename(重命名核心),Reload(重新加载核心),Optimize(优化索引库)Add Core是添加core:主要是在instanceDir对应的文件夹里生成一个core.properties文件 。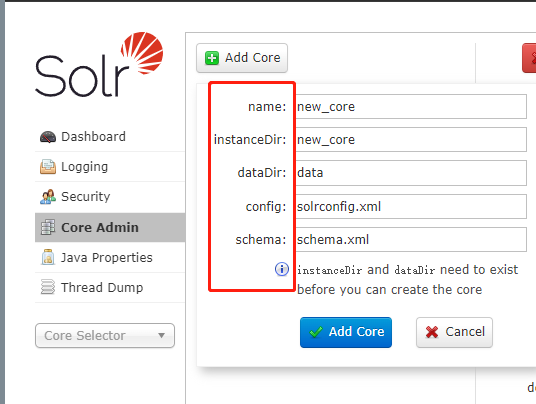
name:给core起的名字;instanceDir:与我们在配置solr到tomcat里时的solr_home里新建的core文件夹名一致;dataDir:确认Add Core时,会在new_core目录下生成名为data的文件夹config:new_core下的conf下的config配置文件(solrconfig.xml)schema: new_core下的conf下的schema文件(schema.xml)
2.4.4 java properties
Solr在JVM 运行环境中的属性信息,包括类路径、文件编码、jvm内存设置等信息。可查看到java相关的一些属性的信息。
2.4.5 Tread Dump
显示Solr Server中当前活跃线程信息,同时也可以跟踪线程运行栈信息。
2.4.6 Core selector(重点)
需要在Core Admin里添加了core后才有可选项。
选择一个SolrCore进行详细操作,如下: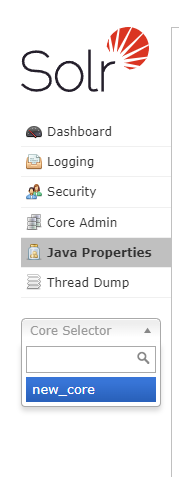
2.4.6.1 Analysis(重点)
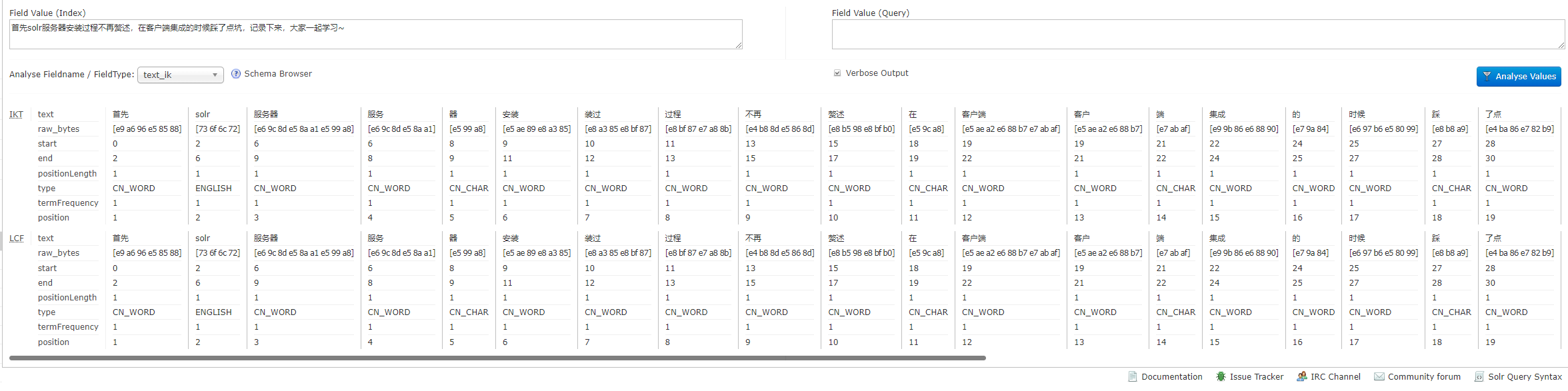
通过此界面可以测试索引分析器和搜索分析器的执行情况。
注:solr中,分析器是绑定在域的类型中的。
2.4.6.2 dataimport
可以定义数据导入处理器,从关系数据库将数据导入到Solr索引库中。
默认没有配置,需要手工配置。
2.4.6.3 Document
通过/update表示更新索引,solr默认根据id(唯一约束)域来更新Document的内容,如果根据id值搜索不到id域则会执行添加操作,如果找到则更新。
通过此菜单可以创建索引、更新索引、删除索引等操作。
2.4.6.4 Query(重点)
通过/select执行搜索索引,必须指定“q”查询条件方可搜索。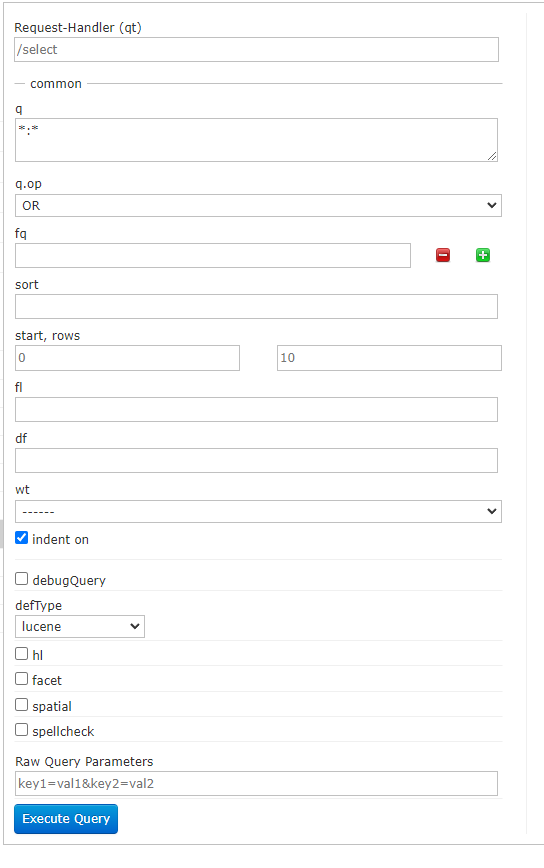
2.5 Solr core的配置(创建)
1、新建core(创建new_core文件夹)
新建的solrhome文件的位置为:%SOLR_HOME%\server\solr\new_core
2、%SOLR_HOME%\server\solr\configsets_default\ 目录下conf文件夹复制到%SOLR_HOME%\server\solr\new_core下
3、 在http://localhost:8983/solr/#/管理页面中添加new_core
点击 add Core 按钮进行添加
3 Solr导入数据
3.1 查看core
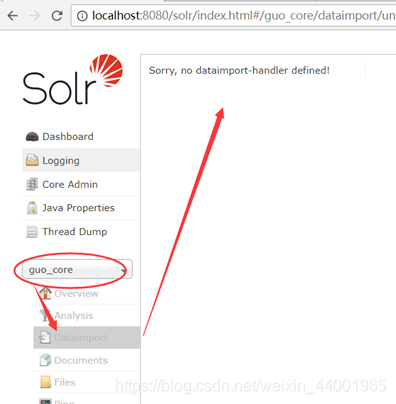
通过此查看创建的guo_core,则说明没有相关配置文件,需要添加并修改。
3.2 DataImport导入数据
该功能是将数据库中数据通过Sql语句方式导入到Solr索引库中。
3.2.1 第一步:添加jar包
%SOLR_HOME%\dist 下的jar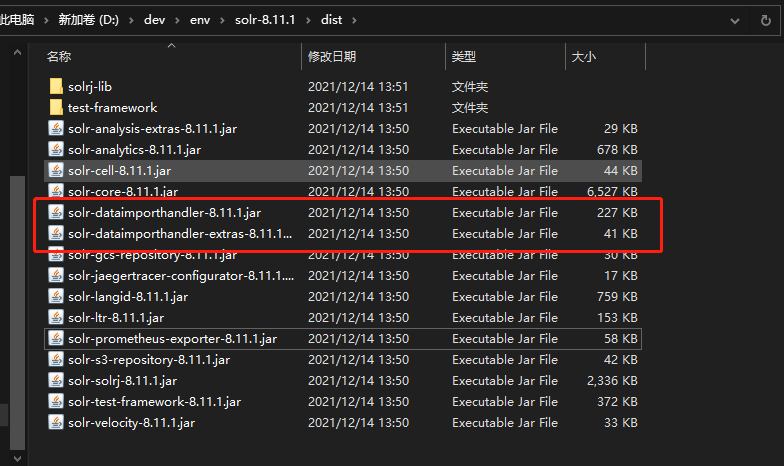
mysql jar
配置Solr: 配置IKAnalyzer分词器
参考IKAnalyzer使用说明
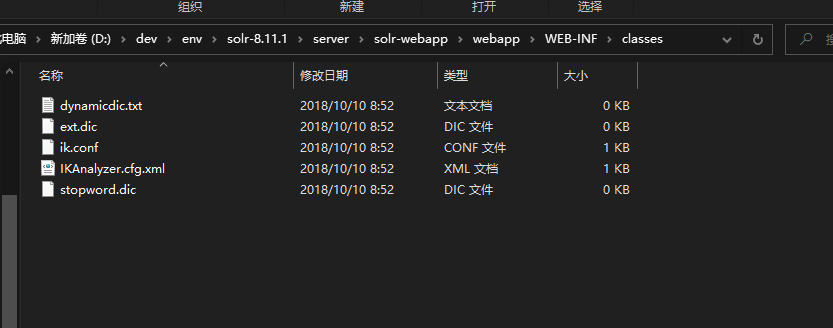
- 使用上面的下载地址下载IK,并解压,将IK目录下src/main/resources中的5个文件拷贝到Solr的WEB-INF/classes/目录下(注classes文件夹如果没有,则手工创建)
① IKAnalyzer.cfg.xml② ext.dic③ stopword.dic④ ik.conf⑤ dynamicdic.txt
 下载IK jar包,将jar拷贝到Solr的WEB-INF/lib目录下
下载IK jar包,将jar拷贝到Solr的WEB-INF/lib目录下
3.2.2 第二步:配置中文分词器
修改同目录下的managed-schema文件
1、在文件中插入中文分词器:

<fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
3.2.3 managed-schema文件详解
在managed-schema.xml文件中,主要配置SolrCoe数据信息,包括:Field和FieldType的定义等信息,在solr中,Field和FieldType都需要先定义后使用
Field详解:
学习详细参考:http://blog.csdn.net/mine_song/article/details/58065323
https://www.cnblogs.com/gslblog/p/6582008.html
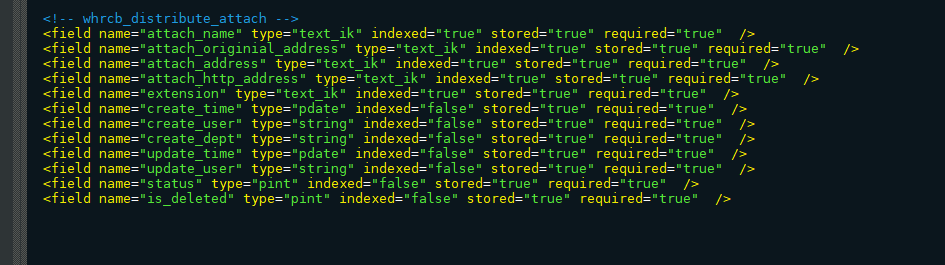
name:指定域的名称(自定义)type:指定域的类型indexed:是否索引 是:(将分好的词进行索引,索引的目的,就是为了搜索), 否:不索引,也就是不对该field域进行搜索。stored:是否存储 是:将field域中的内容存储到文档域中。存储的目的,就是为了搜索页面显示取值用的 ,否:不将field域中的内容存储到文档域中。不存储,则搜索页面中没法获取该field域的值。required:是否必须multiValued:是否多值,比如查询数据需要关联多个字段数据,一个Field存储多个值信息,必须将multiValued设置为true。
dynamicField详解: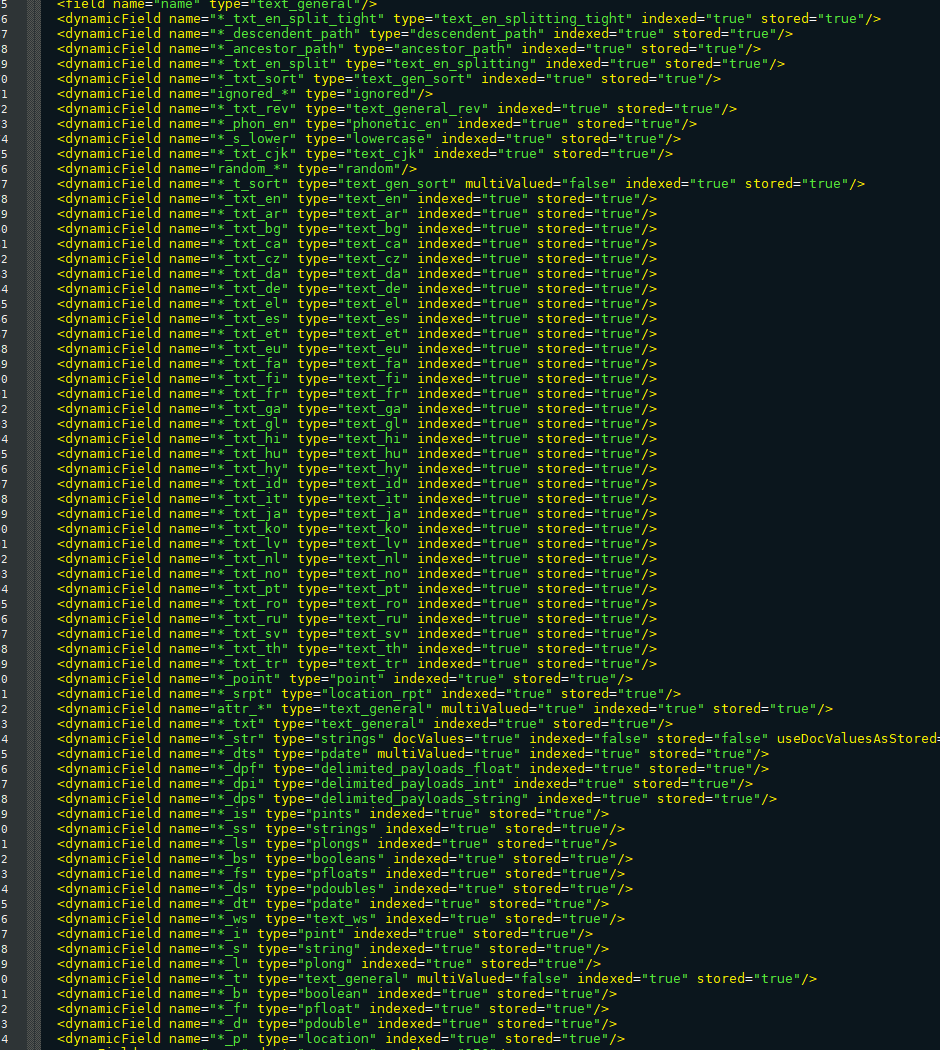
name为*i,定义它的type为int,那么在使用这个字段的时候,任何以_i结果的字段都被认为符合这个定义。
_uniqueKey
其中的id是在Field标签中已经定义好的域名,而且该域设置为required为true。
一个managed-schema文件中必须有且仅有一个唯一键
copyField
复制域
应用场景:我们在搜索时比如输入java,一篇文章分为标题、简介、内容等很多字段,输入的关键字需要制定solr中的域进行检索,不可能从一个表中将所有字段进行索引,因为有些字段不需要索引,所以出现copyField域,把多个域的关键词复制到同一个域,多个域时,可以放到一个域中。就不用定义那么多域了。搜索比较方便
实例:<copyField source="projectName" dest="keywords"/>Source:是Field域的名称Dest:是destination的缩写 目标域
使用案例:
1、 两个普通域 :title和author
2、 使用复制域,将两个域进行索引检索
3、 该域名field name=”text”即是复制域
fieldType
域类型:

- Name:指定域类型的名称
- Class:指定该域类型对应的solr的类型
- Analyzer:指定分析器
- Type:index、query,分别指定搜索和索引时的分析器
- Tokenizer:指定分词器
- Filter:指定过滤器
3.2.4 第三步:修改 solrconfig.xml文件
找到%SOLR_HOME%\server\solr\new_core文件夹下的solrconfig.xml,添加dataimport
首先查询是否存在dataimport的requestHandler,如果不存在,因此需要手动添加。为了以后便于维护此文件,我们就在requestHandler起始位置,约为720行处,添加如下内容
<!-- DataImport --><requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"><lst name="defaults"><str name="config">data-config.xml</str></lst></requestHandler>

3.2.5 第四步:创建data-config.xml
data-config.xml作用:数据库连接相关信息、SQL以及查询结果映射对应域中
在solrconfig.xml同级目录下,创建data-config.xml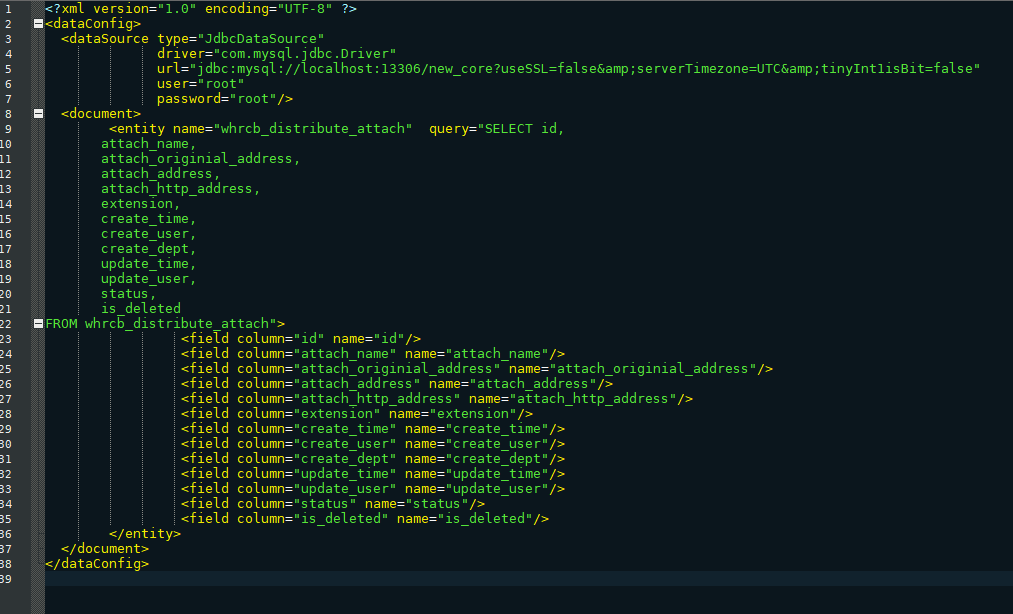
- Query代表:查询的SQL语句
- Column代表:SQL查询的列名
- Name代表:Solr 域Filed中的域名
<?xml version="1.0" encoding="UTF-8" ?><dataConfig><dataSource type="JdbcDataSource"driver="com.mysql.jdbc.Driver"url="jdbc:mysql://localhost:13306/new_core?useSSL=false&serverTimezone=UTC&tinyInt1isBit=false"user="root"password="root"/><document><entity name="whrcb_distribute_attach" query="SELECT id,attach_name,attach_originial_address,attach_address,attach_http_address,extension,create_time,create_user,create_dept,update_time,update_user,status,is_deletedFROM whrcb_distribute_attach"><field column="id" name="id"/><field column="attach_name" name="attach_name"/><field column="attach_originial_address" name="attach_originial_address"/><field column="attach_address" name="attach_address"/><field column="attach_http_address" name="attach_http_address"/><field column="extension" name="extension"/><field column="create_time" name="create_time"/><field column="create_user" name="create_user"/><field column="create_dept" name="create_dept"/><field column="update_time" name="update_time"/><field column="update_user" name="update_user"/><field column="status" name="status"/><field column="is_deleted" name="is_deleted"/></entity></document></dataConfig>

3.2.6 第四步:定义域
修改同目录下的managed-schema文件
配置其Field域:来配置字段【这里的名字要与data-config中的域名一模一样】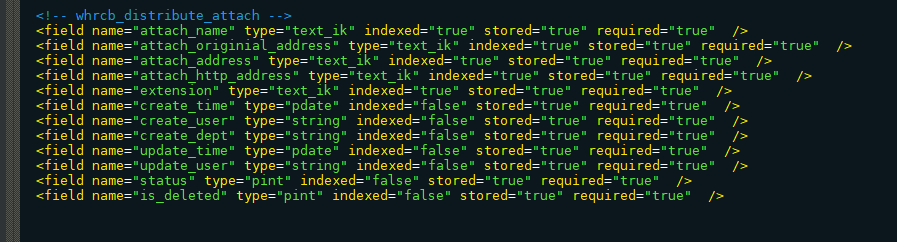
其中<!-- whrcb_distribute_attach --><field name="attach_name" type="text_ik" indexed="true" stored="true" required="true" /><field name="attach_originial_address" type="text_ik" indexed="true" stored="true" required="true" /><field name="attach_address" type="text_ik" indexed="true" stored="true" required="true" /><field name="attach_http_address" type="text_ik" indexed="true" stored="true" required="true" /><field name="extension" type="text_ik" indexed="true" stored="true" required="true" /><field name="create_time" type="pdate" indexed="false" stored="true" required="true" /><field name="create_user" type="string" indexed="false" stored="true" required="true" /><field name="create_dept" type="string" indexed="false" stored="true" required="true" /><field name="update_time" type="pdate" indexed="false" stored="true" required="true" /><field name="update_user" type="string" indexed="false" stored="true" required="true" /><field name="status" type="pint" indexed="false" stored="true" required="true" /><field name="is_deleted" type="pint" indexed="false" stored="true" required="true" />
attach_name需要模糊查询(中文分词),故将其类型改为text_ik
3.2.7 第五步:启动服务
1、启动服务器:bin\solr.cmd start -m 4g
2、查看数据导入结果
进入new_core,测试中文分词器效果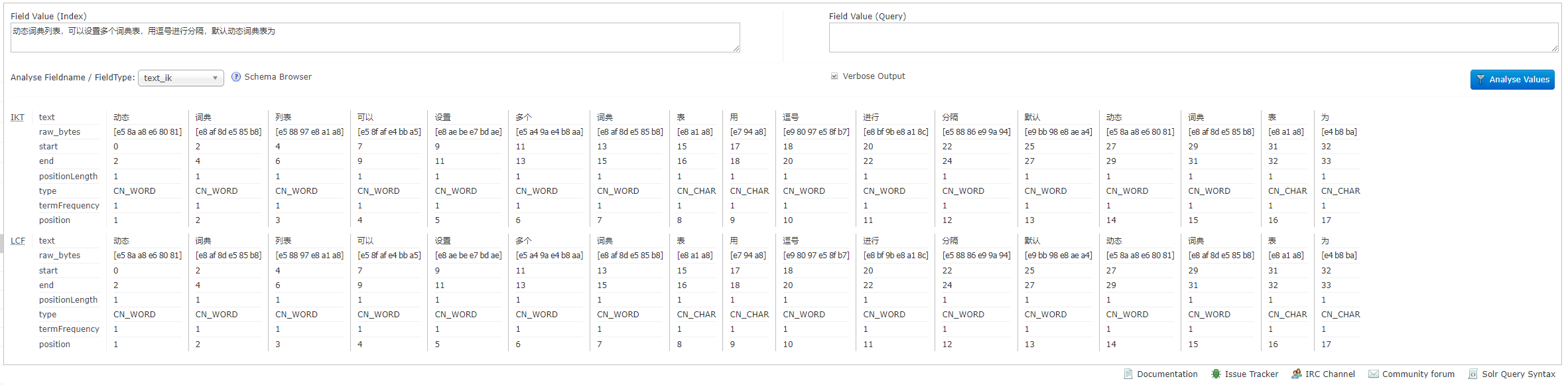
进入new_core中DataImport执行execute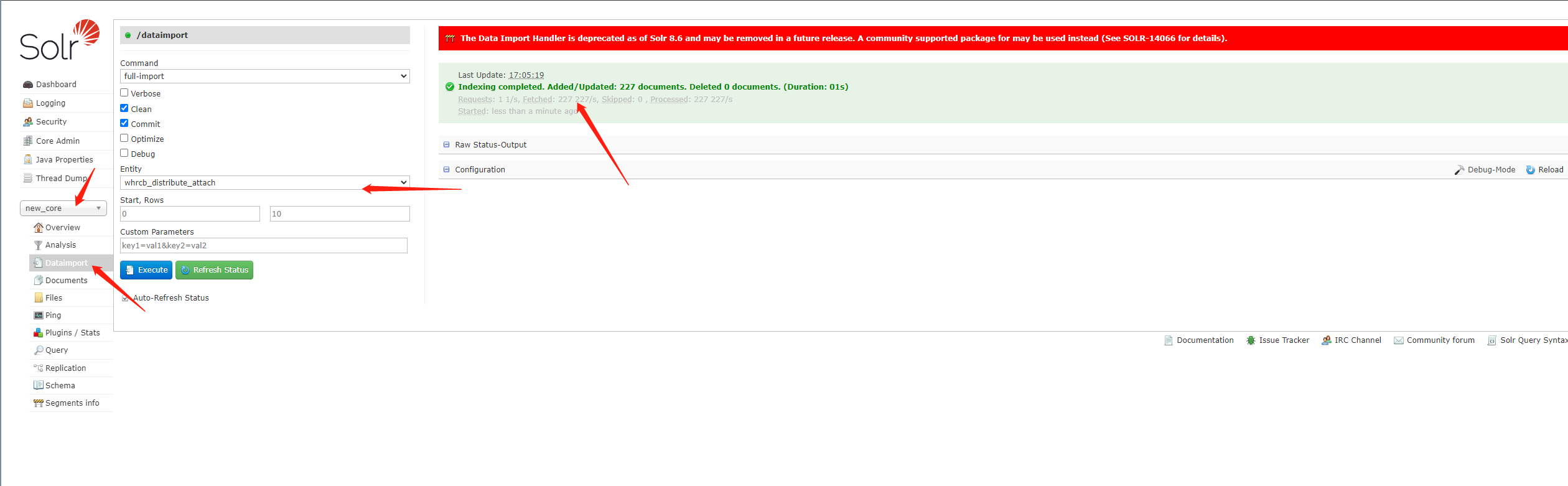
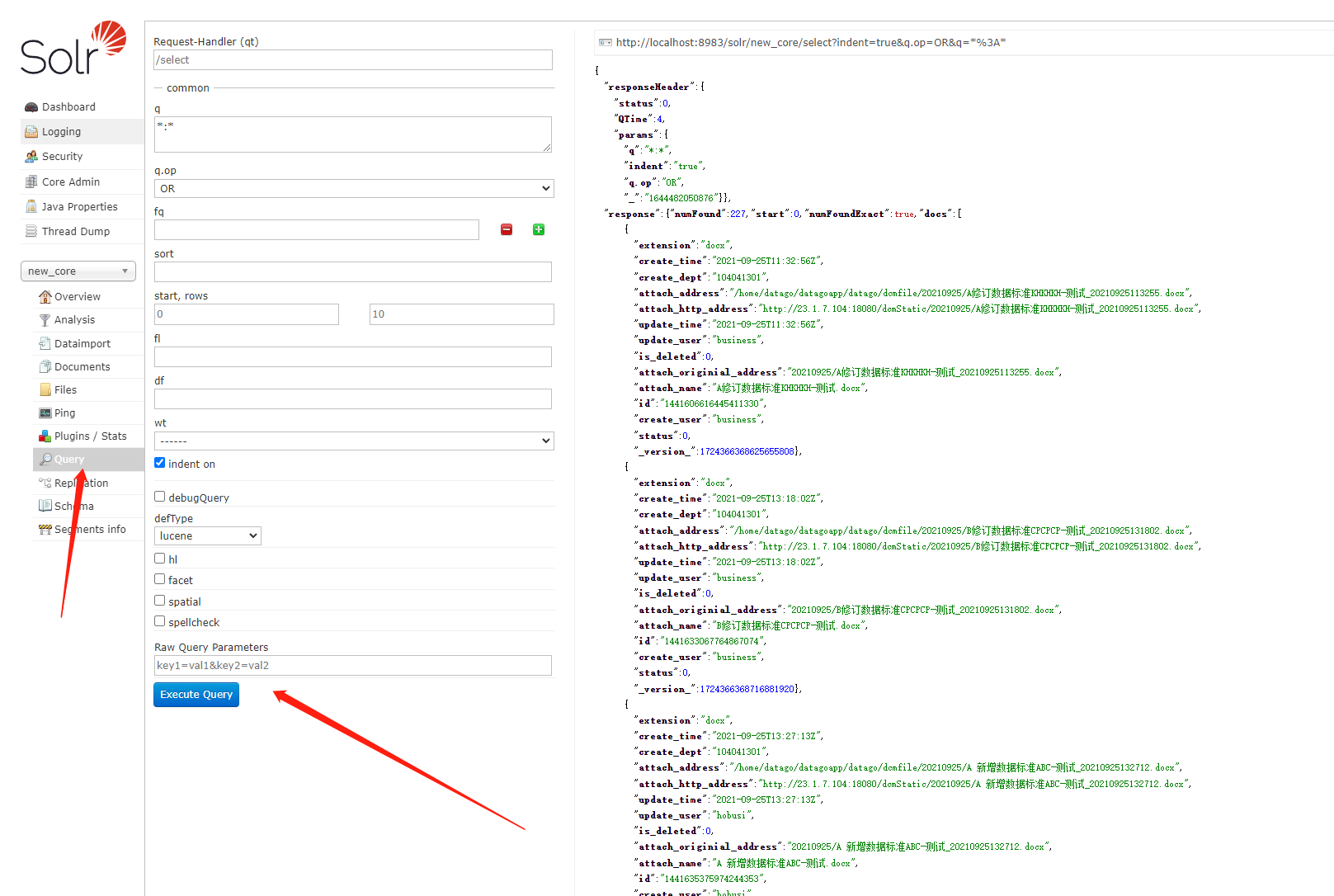
查询描述1,q 查询的关键字,此参数最为重要,例如,q=id:1,默认为q=:,2,fl 指定返回(回显)哪些字段,用逗号或空格分隔,注意:字段区分大小写,例如,fl= id,title,sort3,start 返回结果的第几条记录开始,一般分页用,默认0开始4,rows 指定返回结果最多有多少条记录,默认值为 10,配合start实现分页5,sort 排序方式,例如id desc 表示按照 “id” 降序6,wt (writer type)指定输出格式,有 xml, json等7,fq (filter query)过虑查询,提供一个可选的筛选器查询。返回在q查询符合结果中同时符合的fq条件的查询结果,例如:q=id:1&fq=sort:[1 TO 5],找关键字id为1 的,并且sort是1到5之间的。8,df 默认的查询字段,一般默认指定。9,h1 是否高亮,
3.3 客户端查询语法
- q查询关键字,查询所有使用*。
请求的q是字符串
多个条件可以:之间用AND 或 OR 关联 
fq(filter query)过滤查询,作用:在q查询符合结果中同时是fq查询符合的,例如:请求fq是一个数组(多个值)
过滤查询价格从1到1的记录。
也可以在“q”查询条件中使用product_price:[1 TO 20],如下: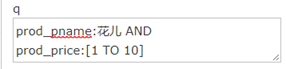
也可以使用“*”表示无限,例如:10以上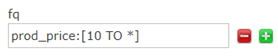
10以下
sort排序,格式:sort=<field name>+<desc|asc>[,<field name>+<desc|asc>]….示例: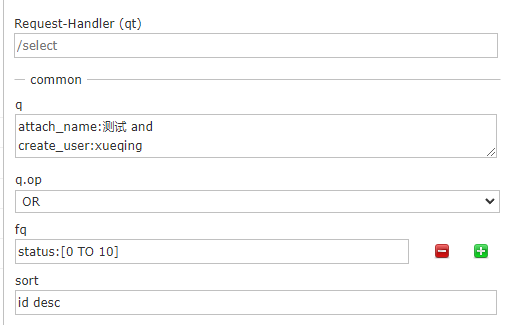
start- 分页显示使用,开始记录下标,从0开始
5.rows- 指定返回结果最多有多少条记录,配合start来实现分页。
实际开发时,知道当前页码和每页显示的个数最后求出开始下标。fl- 指定返回那些字段内容,用逗号或空格分隔多个(回显)
df-指定一个搜索默认Field
q => 测试
df => attach_namewt- (writer type)指定输出格式
hl是否高亮 ,设置高亮Field,设置格式前缀和后缀。
hl.fl指定高亮域的名称

若有收获,就点个赞吧
0 人点赞
