一、官方DataImport方式
相关配置文件
- data-config.xml
```xml
<?xml version=”1.0” encoding=”UTF-8” ?>
- managed-schema```xml<!-- IK分词 --><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="false"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" conf="ik.conf" useSmart="true"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType><field name="content" type="text_ik" indexed="true" stored="true" omitNorms="true" multiValued="false"/><field name="author" type="text_ik" indexed="true" stored="true"/><field name="title" type="text_ik" indexed="true" stored="true"/><field name="fileName" type="string" indexed="true" stored="true"/><field name="filePath" type="string" indexed="true" stored="true" multiValued="false"/><field name="size" type="plong" indexed="true" stored="true"/><field name="lastModified" type="pdate" indexed="true" stored="true"/><!-- 索引复制,联合索引 --><field name="keyword" type="text_ik" indexed="true" stored="true" omitNorms="true" multiValued="true"/><copyField source="author" dest="keyword" maxChars="30000"/><copyField source="title" dest="keyword" maxChars="30000"/><copyField source="content" dest="keyword" maxChars="30000"/><copyField source="fileName" dest="keyword" maxChars="30000"/>
- solrconfig.xml
<!-- DataImport --><requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"><lst name="defaults"><str name="config">data-config.xml</str></lst></requestHandler>
从 core 中 DataImport 中选择配置的 entity ,点击执行: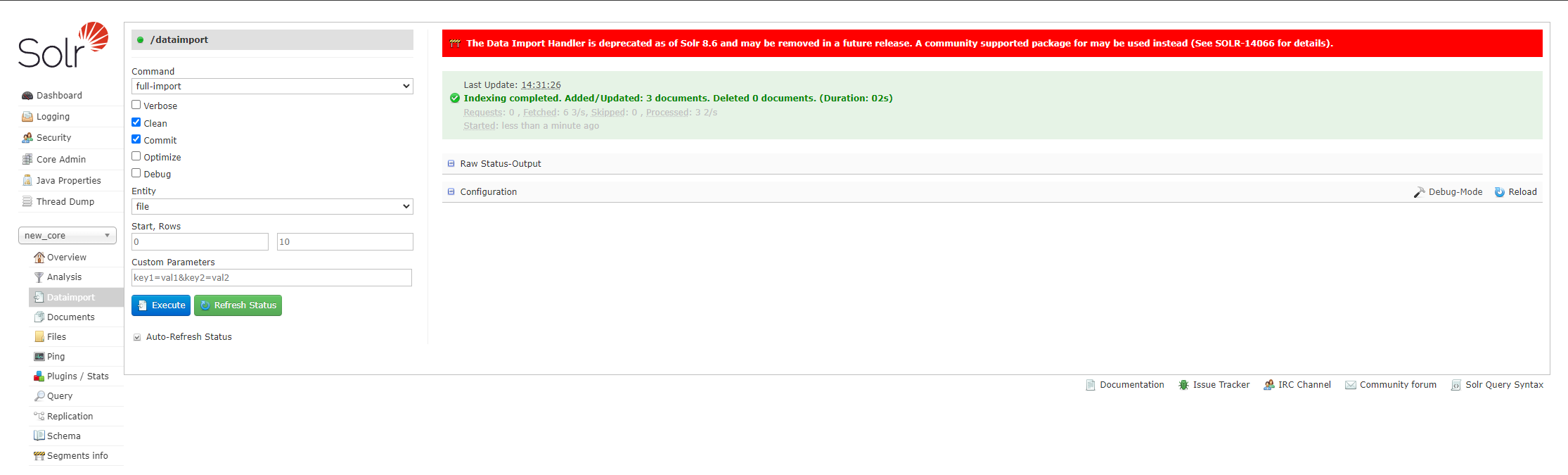
导入成功后在 core 中 Query 中验证是否导入: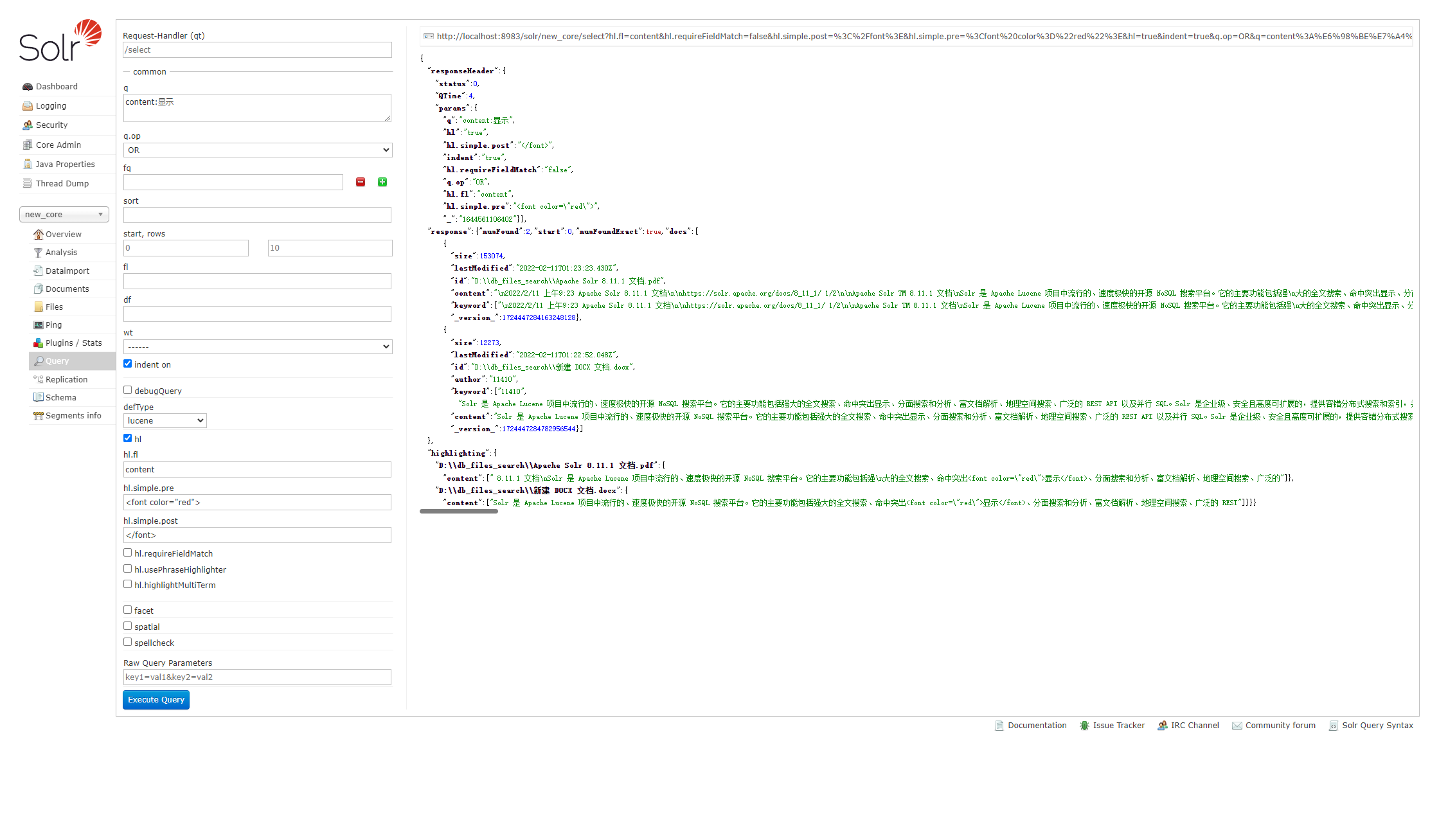
二、使用SolrJ方式索引文档
引入配置文件
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-solr</artifactId><version>2.4.13</version></dependency><dependency><groupId>cn.hutool</groupId><artifactId>hutool-all</artifactId><version>5.7.9</version></dependency>
编写接口
package com.clown.solr_test.controller;import cn.hutool.core.io.FileUtil;import lombok.AllArgsConstructor;import org.apache.solr.client.solrj.SolrClient;import org.apache.solr.client.solrj.SolrQuery;import org.apache.solr.client.solrj.SolrServerException;import org.apache.solr.client.solrj.request.AbstractUpdateRequest;import org.apache.solr.client.solrj.request.ContentStreamUpdateRequest;import org.apache.solr.client.solrj.response.QueryResponse;import org.apache.solr.common.SolrDocumentList;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;import org.springframework.web.multipart.MultipartFile;import java.io.File;import java.io.IOException;import java.time.LocalDateTime;import java.time.format.DateTimeFormatter;import java.util.HashMap;import java.util.Map;import java.util.Objects;import java.util.Optional;import java.util.logging.Handler;/*** @author xq* @date 2022年02月11日 10:36*/@RestController@AllArgsConstructorpublic class SolrTestController {private final SolrClient client;/*** 查询** @return* @throws SolrServerException* @throws IOException*/@PostMapping("/query")public Object get(@RequestParam String content) throws SolrServerException, IOException {SolrQuery query = new SolrQuery();query.add("q", content);// 高亮query.setParam("hl", "true");query.setParam("hl.fl", "content");query.setParam("hl.simple.pre", "<font color=\"red\">");query.setParam("hl.simple.post", "</font>");// 以下方法也可设置高亮// query.setHighlight(true);// query.addHighlightField("content");// query.setHighlightSimplePre("<font color=\"red\">");// query.setHighlightSimplePost("</font>");QueryResponse response = client.query(query);Map<String, Object> map = new HashMap<>(1);map.put("response", response.getResults());map.put("highlighting", Optional.ofNullable(response.getHighlighting()).orElseGet(HashMap::new));return map;}/*** 索引文档** @param multipartFile* @throws IOException* @throws SolrServerException*/@PostMapping("/upload")public void put(@RequestParam MultipartFile multipartFile) throws IOException, SolrServerException {ContentStreamUpdateRequest up = new ContentStreamUpdateRequest("/update/extract");File file = new File(Objects.requireNonNull(multipartFile.getOriginalFilename()));FileUtil.writeFromStream(multipartFile.getInputStream(), file);String contentType = getFileContentType(file.getName());up.addFile(file, contentType);up.setParam("literal.id", file.getAbsolutePath());//up.setParam("uprefix", "ignored_");up.setParam("literal.filePath", file.getAbsolutePath());//up.setParam("literal.author", "clown");up.setParam("literal.title", file.getName());up.setParam("literal.fileName", file.getName());up.setParam("literal.size", String.valueOf(file.getTotalSpace()));up.setParam("literal.lastModified", LocalDateTime.now().format(DateTimeFormatter.ofPattern("yyyy-MM-dd HH:mm:ss")));up.setAction(AbstractUpdateRequest.ACTION.COMMIT, true, true);client.request(up);}/*** 根据文件名获取文件的ContentType类型** @param filename* @return*/public static String getFileContentType(String filename) {String contentType = "";String prefix = filename.substring(filename.lastIndexOf(".") + 1);switch (prefix) {case "xlsx":contentType = "application/vnd.openxmlformats-officedocument.spreadsheetml.sheet";break;case "pdf":contentType = "application/pdf";break;case "doc":contentType = "application/msword";break;case "txt":contentType = "text/plain";break;case "xls":contentType = "application/vnd.ms-excel";break;case "docx":contentType = "application/vnd.openxmlformats-officedocument.wordprocessingml.document";break;case "ppt":contentType = "application/vnd.ms-powerpoint";break;case "pptx":contentType = "application/vnd.openxmlformats-officedocument.presentationml.presentation";break;default:contentType = "othertype";break;}return contentType;}}
通过以上方法可以看出给solr上传文件使用ContentStreamUpdateRequest 封装请求对象,利用
solr.request(up) 实现post请求.
literal 设置的id 是你的schema.xml 中key值 对应的 solrId为其value值,
在schema.xml 中 配置
官网请求参数详细介绍如下:
Input Parameters* fmap.<source_field>=<target_field> - Maps (moves) one field name to another. Example: fmap.content=text will cause the content field normally generated by Tika to be moved to the "text" field.* boost.<fieldname>=<float> - Boost the specified field.* literal.<fieldname>=<value> - Create a field with the specified value. May be multivalued if the Field is multivalued.* uprefix=<prefix> - Prefix all fields that are not defined in the schema with the given prefix. This is very useful when combined with dynamic field definitions. Example: uprefix=ignored_ would effectively ignore all unknown fields generated by Tika given the example schema contains <dynamicField name="ignored_*" type="ignored"/>* defaultField=<Field Name> - If uprefix is not specified and a Field cannot be determined, the default field will be used.* extractOnly=true|false - Default is false. If true, return the extracted content from Tika without indexing the document. This literally includes the extracted XHTML as a string in the response. When viewing manually, it may be useful to use a response format other than XML to aid in viewing the embedded XHTML tags. See TikaExtractOnlyExampleOutput.* resource.name=<File Name> - The optional name of the file. Tika can use it as a hint for detecting mime type.* capture=<Tika XHTML NAME> - Capture XHTML elements with the name separately for adding to the Solr document. This can be useful for grabbing chunks of the XHTML into a separate field. For instance, it could be used to grab paragraphs (<p>) and index them into a separate field. Note that content is also still captured into the overall "content" field.* captureAttr=true|false - Index attributes of the Tika XHTML elements into separate fields, named after the element. For example, when extracting from HTML, Tika can return the href attributes in <a> tags as fields named "a". See the examples below.* xpath=<XPath expression> - When extracting, only return Tika XHTML content that satisfies the XPath expression. See http://tika.apache.org/1.2/parser.html for details on the format of Tika XHTML. See also TikaExtractOnlyExampleOutput.* lowernames=true|false - Map all field names to lowercase with underscores. For example, Content-Type would be mapped to content_type.* literalsOverride=true|false - Solr4.0 When true, literal field values will override other values with same field name, such as metadata and content. If false, then literal field values will be appended to any extracted data from Tika, and the resulting field needs to be multi valued. Default: true* resource.password=<password> - Solr4.0 The optional password for a password protected PDF or OOXML file. File format support depends on Tika.* passwordsFile=<file name> - Solr4.0 The optional name of a file containing file name pattern to password mappings. See chapter "Encrypted Files" belowIf extractOnly is true, additional input parameters:* extractFormat=xml|text - Default is xml. Controls the serialization format of the extract content. xml format is actually XHTML, like passing the -x command to the tika command line application, while text is like the -t command.### Order of field operations1. fields are generated by Tika or passed in as literals via literal.fieldname=value. Before Solr4.0 or if literalsOverride=false, then literals will be appended as multi-value to tika generated field.2. if lowernames==true, fields are mapped to lower case3. mapping rules fmap.source=target are applied4. if uprefix is specified, any unknown field names are prefixed with that value, else if defaultField is specified, unknown fields are copied to that.
译文:
输入参数* fmap.<source_field>=<target_field> - 将一个字段名映射(移动)到另一个。示例: fmap.content=text 将导致通常由 Tika 生成的内容字段移动到“文本”字段。* boost.<fieldname>=<float> - 提升指定的字段。* literal.<fieldname>=<value> - 创建具有指定值的字段。如果字段是多值的,则可能是多值的。* uprefix=<prefix> - 使用给定前缀为架构中未定义的所有字段添加前缀。这在与动态字段定义结合使用时非常有用。示例:uprefix=ignored_ 将有效地忽略 Tika 生成的所有未知字段,因为示例模式包含 <dynamicField name="ignored_*" type="ignored"/>* defaultField=<Field Name> - 如果未指定uprefix 并且无法确定字段,则将使用默认字段。* extractOnly=true|false - 默认为 false。如果为 true,则返回从 Tika 提取的内容而不为文档编制索引。这实际上将提取的 XHTML 作为字符串包含在响应中。手动查看时,使用 XML 以外的响应格式来帮助查看嵌入的 XHTML 标记可能很有用。请参阅 TikaExtractOnlyExampleOutput。* resource.name=<文件名> - 文件的可选名称。 Tika 可以将其用作检测 mime 类型的提示。* capture=<Tika XHTML NAME> - 分别捕获具有名称的 XHTML 元素以添加到 Solr 文档。这对于将 XHTML 块抓取到单独的字段中很有用。例如,它可以用来抓取段落 (<p>) 并将它们索引到一个单独的字段中。请注意,内容仍会被捕获到整个“内容”字段中。* captureAttr=true|false - 将 Tika XHTML 元素的属性索引到单独的字段中,以元素命名。例如,从 HTML 中提取时,Tika 可以将 <a> 标记中的 href 属性作为名为“a”的字段返回。请参阅下面的示例。* xpath=<XPath 表达式> - 提取时,仅返回满足 XPath 表达式的 Tika XHTML 内容。有关 Tika XHTML 格式的详细信息,请参见 http://tika.apache.org/1.2/parser.html。另请参见 TikaExtractOnlyExampleOutput。* lowernames=true|false - 将所有字段名称映射为带下划线的小写。例如,Content-Type 将映射到 content_type。* literalsOverride=true|false - Solr4.0 当为真时,文字字段值将覆盖具有相同字段名称的其他值,例如元数据和内容。如果为 false,则文字字段值将附加到从 Tika 提取的任何数据中,并且结果字段需要是多值的。默认值:真* resource.password=<password> - Solr4.0 受密码保护的 PDF 或 OOXML 文件的可选密码。文件格式支持取决于 Tika。* passwordsFile=<文件名> - Solr4.0 包含文件名模式到密码映射的文件的可选名称。请参阅下面的“加密文件”一章如果 extractOnly 为真,则附加输入参数:* extractFormat=xml|text - 默认为 xml。控制提取内容的序列化格式。 xml 格式实际上是 XHTML,就像将 -x 命令传递给 tika 命令行应用程序一样,而 text 就像 -t 命令一样。### 现场操作顺序1. 字段由 Tika 生成或通过 literal.fieldname=value 作为文字传入。在 Solr4.0 之前或如果 literalsOverride=false,则文字将作为多值附加到 tika 生成的字段。2.如果lowernames==true,则字段映射为小写3. 应用映射规则 fmap.source=target4. 如果指定了uprefix,任何未知的字段名称都以该值作为前缀,否则如果指定了defaultField,未知字段将被复制到那个值。
代码中存在以上实现还不够,
此请求到/update/extract 这个请求处理器在solrconfig.xml中必须有相应的配置
<requestHandler name="/update/extract" startup="lazy" class="solr.extraction.ExtractingRequestHandler"><lst name="defaults"><str name="lowernames">true</str><str name="uprefix">ignored_</str><str name="fmap.content">content</str></lst></requestHandler>
并需把contrib/extraction/lib 及dist下的包全部复制到solr的 WEB-INF的lib下存放

若有收获,就点个赞吧
0 人点赞
