小结
论文在overparameterized 的深度网络上进行了实验,发现这样的网络不一定会过拟合。主要原因是在于 DNN能够自我适应学到关键层,即自我降解网络容量。
网络层可以分为 关键层、非关键层,关键层的改变对模型预测准确率影响很大。关键层的分布没有规律,FC网络越靠前,越critical;而resnet等网络,则不是。
疑问:1、网络层的鲁棒性 与 泛化性 有什么区别? 泛化性是指在未知数据集上的表现;鲁棒性是指网络层抗干扰的能力,能力的衡量方式是对网络层增加噪声等,对比前后在测试集上误差的变化。
一、问题与现状
理解DNN的有效性成为近几年研究的热门主题。
论文研究overparameterized 深度模型各层结构,探索不同层的不同特点。
论文引进 鲁棒性的概念
实验发现,网络层可以分成两种类型的 重要性的(critial) 和 可有可无型的(ambient)。前者重设置后,会导致模型预测结果很糟糕,后者对结果无影响。
设置
网络参数初始化值![[2019-不同层作用]Are All Layers Created Equal - 图1](/uploads/projects/cimon-zswxl@hze8ow/9b4eb4aac1e385abe63e0ce56041372f.svg) 。
。![[2019-不同层作用]Are All Layers Created Equal - 图2](/uploads/projects/cimon-zswxl@hze8ow/99b39c148650598427775d38c9617828.svg) 表示 d层第k次迭代时参数的值,对应的为checkpoint-k。
表示 d层第k次迭代时参数的值,对应的为checkpoint-k。
re-initialization: 给定网络层,把训练好的参数设置成k轮迭代的值,然后再计算模型在测试集上的误差。
re-randomization:给定模型的第d层,重新初始化![[2019-不同层作用]Are All Layers Created Equal - 图3](/uploads/projects/cimon-zswxl@hze8ow/3f56970e315bb9a0eb1c04b10ebc75e4.svg) 。
。
FCN网络分析
实验一
图a的实验现象,1、重随机化任何一层,都会使得表征崩溃、分类准确率变差(**这个现象有点意思,说明初始化对模型结果影响很大**)。2、重初始化时,第一层的网络最为敏感,其他层更鲁棒。
图b、c比较的是参数和初始化值的距离:1、距离和重初始化的鲁棒性之间没有关联。
可以总结出如下结论:由于自身关键层数的限制性,使得基于SGD训练后的超容量深度网络实际上有更低的复杂度
Over-capacitated deep networks trained with stochastic gradient have low-complexity due to self-restriction of the number of critical layers.
直觉上来说,部分参数是可以还原为初始化值的而不影响模型性能,这样说明模型参数、复杂是可以缩减的。
实验二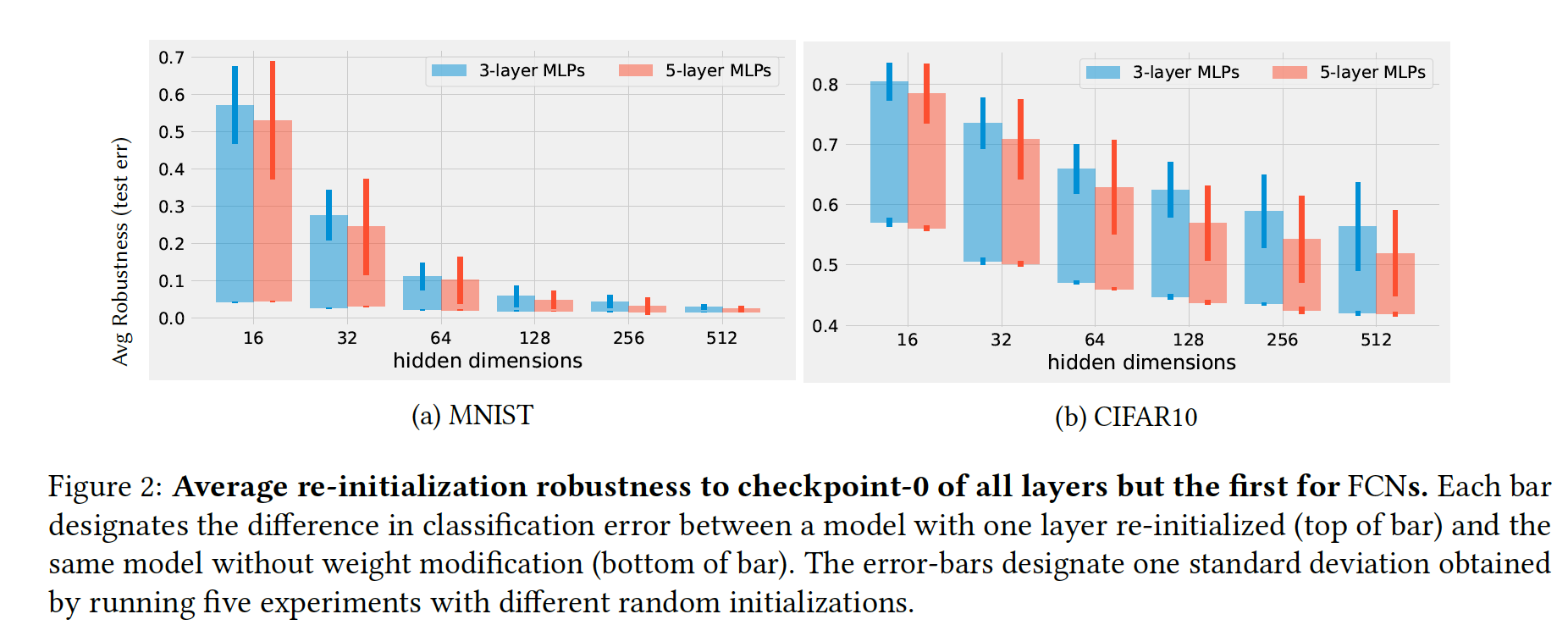
重初始化除第一层的网络层参数为checkpoint-0,研究隐层维度对结果的影响。
从图的现象可以发现:1、网络越宽(网络容量越大),深层的网络越鲁棒。如果网络容量过小,所有层都是很critical;随着网络容量增加,将会更加充分的利用浅层,其他层如同做随机投影一样。 2、CIFAR比MNIST更能拟合,所有需要更大的容量。
结论:神经网络会自适应降解网络容量。
the empirical results of this section provide some evidence that deep networks adjust automatically their de-facto capacity. When a big network is trained on an easy task, only a few layers seem to be playing critical roles.
大型CNN网络实验
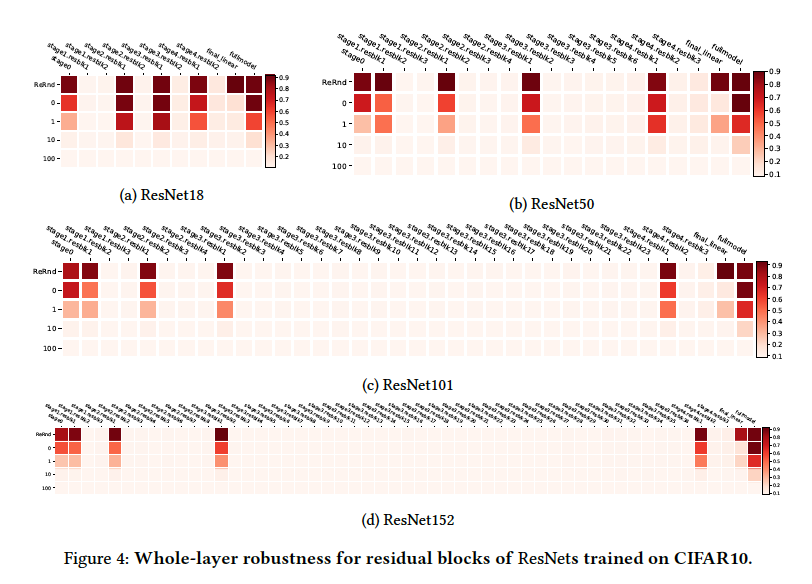
实验现象:critical 层分布没有规律

若有收获,就点个赞吧
0 人点赞
