一、问题与现状
标度律是指一些物理量之间的幂次律(power formuula),常用来描写物理过程的相似性。
模型的损失 与 模型大小、数据集大小、训练时使用的算力的函数关系呈幂率分布(长尾分布);
从结构方面来说,网络的宽度、深度 对损失也有影响,但比较小。
简单等式(关系函数) 能体现 过拟合与模型/数据大小的关系;训练速度与模型大小的关系。能应用在算力资源有限的情况下的资源分配。不同大小的模型应该使用合适大小的训练集,有效收敛,节省计算资源。
概括一下:模型的损失是关于 模型大小、数据大小的幂率函数,DNN的宽度、深度对损失的影响较小(实验中经常调网络结构,确实如此,大头还是数据与模型)。模型越大,需要的数据量越大,耗费资源越多;从节省资源的角度来说,给定大小的模型,使用多大的数据大小合适呢?保证效果且提升效率。
二、介绍
总结
论文对transformer类的语言模型进行了研究,有如下几个发现:
1、模型performance 强取决于 规模,与模型结构弱相关。规模主要有3个因素:模型参数数量 N、数据集大小D、用于训练的算力 C。结构主要是:模型宽度、深度等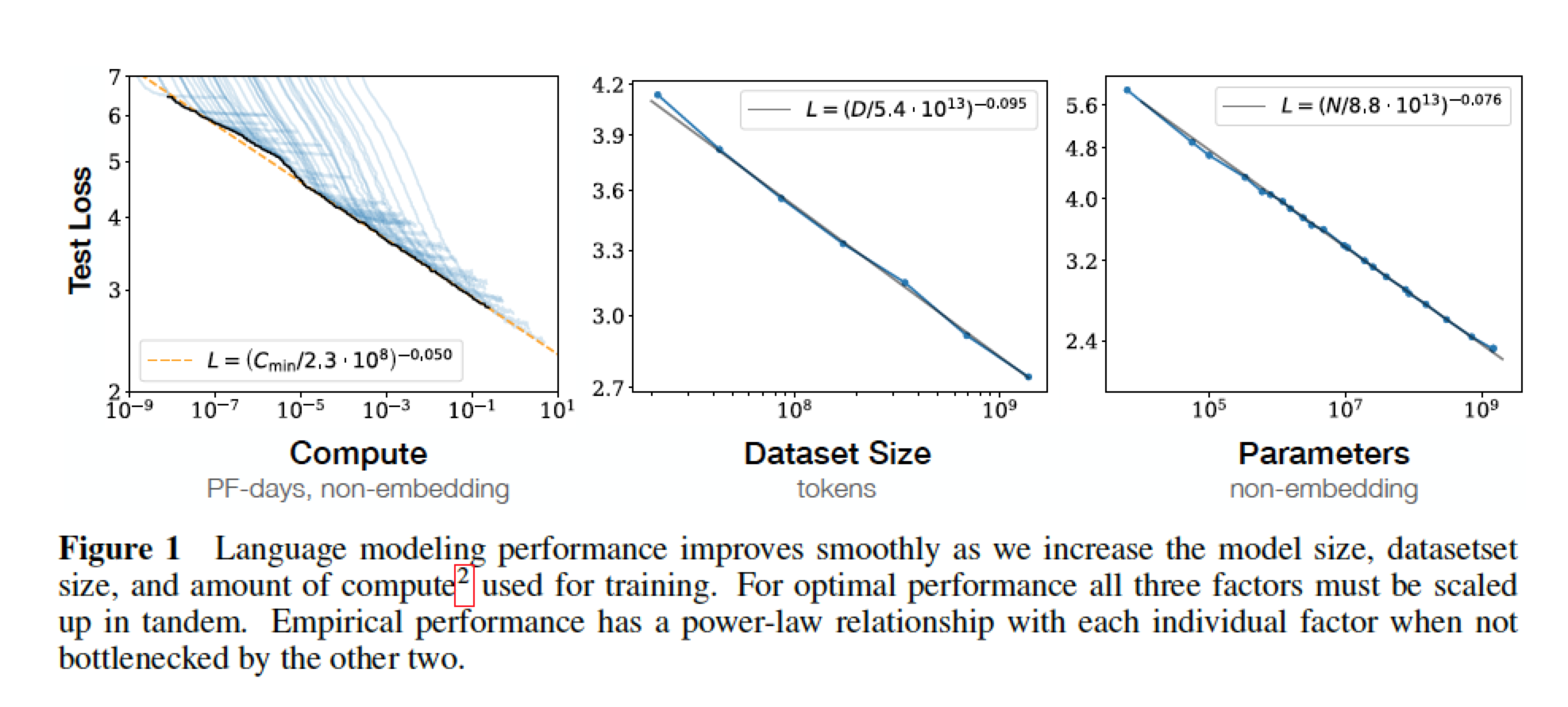
2、平滑的幂律分布。模型performance 与 三个规模因子呈幂律分布。如Figure 1所示。
3、过拟合的一般性规律。只要协同增加N、D,performance就能如预期般地增加。但是如果一者固定,一者变化,performance不能保证。 performance 大概服从 ![[2020-OpenAI]Scaling Laws for Neural Language Models - 图2](/uploads/projects/cimon-zswxl@hze8ow/a0528ce2c359a4698529f8d26b5a9fed.svg) 比例,意思是:增加8倍的模型大小,则需要增加5倍的数据大小,才能保证不过拟合。
比例,意思是:增加8倍的模型大小,则需要增加5倍的数据大小,才能保证不过拟合。
4、训练的一般性规律。训练曲线与模型参数成独立的幂律分布。

若有收获,就点个赞吧
0 人点赞
