一、问题与现状
本文重新考虑[13]中提出的global average pooling layer,发现其有出色的定位能力(remarkable localization
ability)。这项技术作为均值而提出,用于调整训练过程。我们发现它能够学到 可定位的深度表征,可以应用各种任务。
论文提出的网络在不同任务上都有定位具有区别性的图片区域,即使网络并不是特定为该任务训练的。
二、介绍
global average pooling 常用做 正则项,防止过拟合。在我们的实验中,
三、相关工作
weakly-supervised object localization(弱监督物体定位):
全局最大池化:定位object的一个点。
全局平均池化:识别object的整体轮廓。背后的直觉是,相比较最大池化来说,平均池化的损失考虑的是所有具有区别性的图片区域。
class activation map :加权激活图。
visualizing CNN(CNN可视化):
可视化CNN便于理解CNN的属性。
很多文献都忽略了一个问题:全连接不能绘制出图片的全部,本文把全连接移除且performance基本不变,这样做更 易于理解论文提出的网络。
四、模型
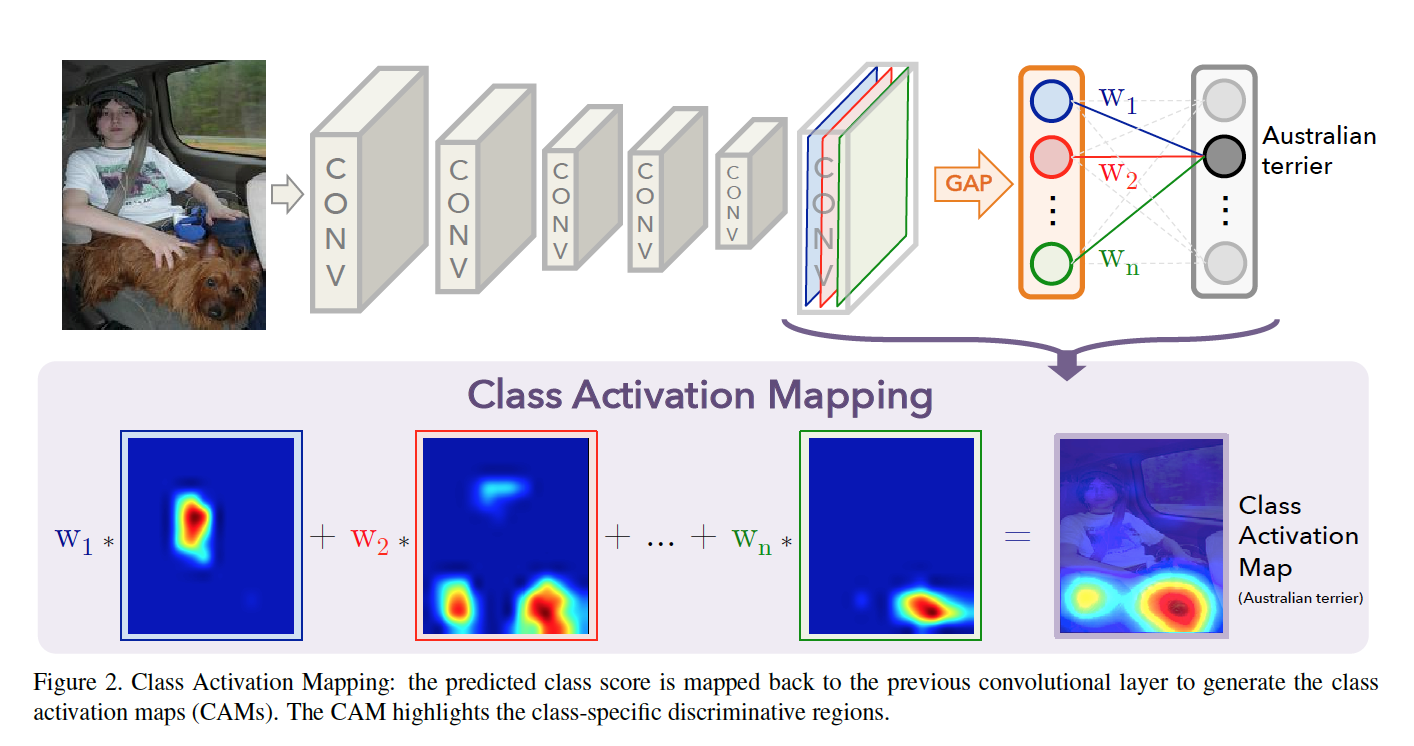<br />论文的核心是 **class activation maps(CAM)** 。<br /> 表示第k个特征图的坐标位置,<br />给定类别,softmax的输入是,  表示类别c 的第k个特征图的重要性。和类别绑定?==>实质上是网络计算的。<br />概率。<br />定义类别c的**class activation map(CAM)**,,特征图按权重相加。<br />也有
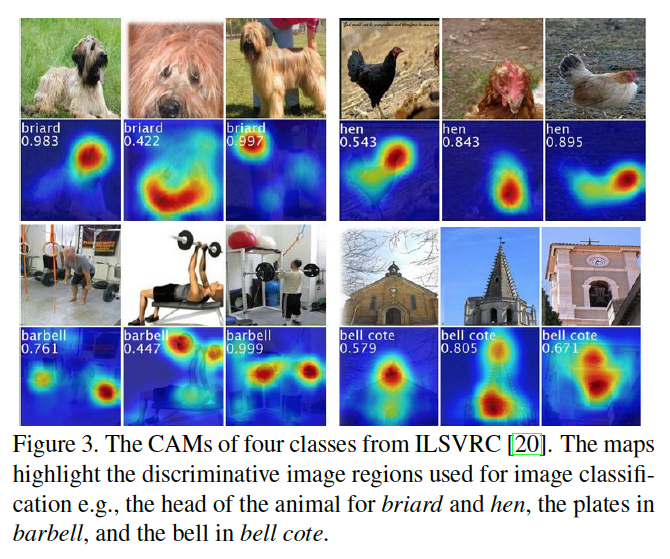
期望每个特征图通过其感受野内(receptive field)的可视化模型而被激活,CAM可以认为是不同坐标位置的可视化模型的加权和。通过upsample把CAM 映射到图片原始大小。如Figure3,可以看到 区别性区域 不同类别不同。
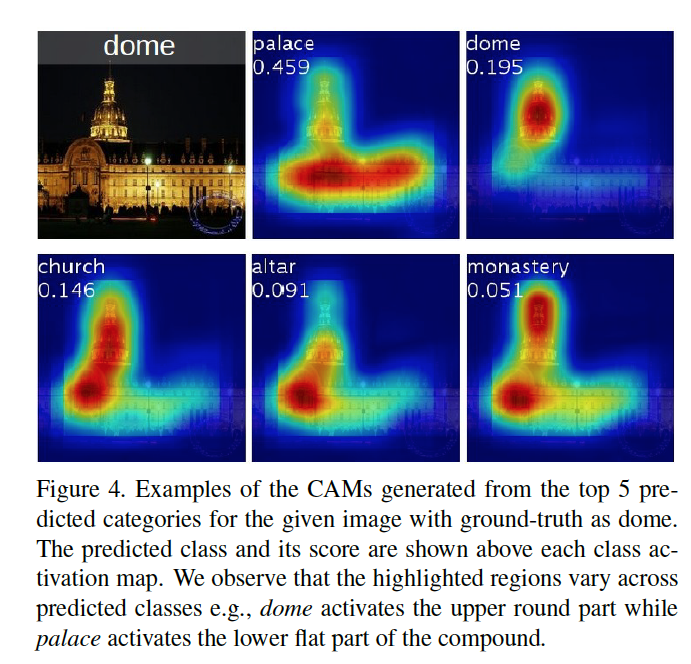
Figure4,使用不同类别c的![[2015-CAM]Learning Deep Features for Discriminative Localization - 图1](/uploads/projects/cimon-zswxl@hze8ow/8b8f7adaae73a9b4a8196d074223cc28.svg) 得到同一个图片的CAM图。
得到同一个图片的CAM图。
Global average pooling (GAP) vs global max pooling (GMP)
之前的一些工作在弱监督物体定位中使用GMP。直觉上来说GAP和GMP的不同,GAP的loss 识别的是物体的整个轮廓,而GMP则是识别一个具有区别性的区域。这就是GMP为什么能够找所有的具有区别性的区域。此外,GAP并没有降低model 的performance。
五、实验-弱监督的物体定位
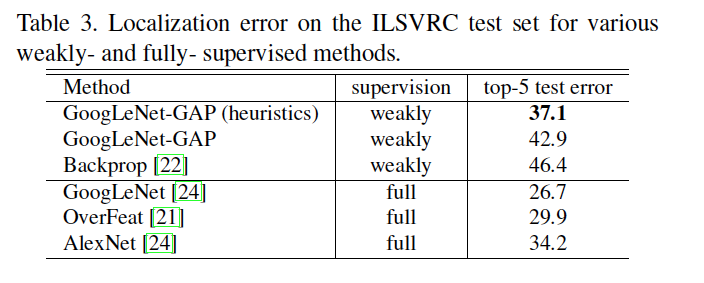
Localization:生成边界框。首先得到CAM图中值top20%的区域,然后选取联通的最大区域。
对比的最后一层是CAM 和 全连接 定位能力的区别。
六、实验-模式发现(Pattern Discovery)
CAM能够在场景中发现有信息的物体;在弱标签图片下有概念性的定位性
七、实验-可视化
与FC相比,CAM能够有效地图片上高信息区域。
参考
[13] M. Lin, Q. Chen, and S. Yan. Network in network. International Conference on Learning Representations, 2014.
[16] M. Oquab, L. Bottou, I. Laptev, and J. Sivic. Is object localization for free? weakly-supervised learning with convolutional neural networks. Proc. CVPR, 2015.

若有收获,就点个赞吧
0 人点赞
