2014-Learning Deep Features for Discriminative Localization
论文的方法能干什么?
1、可视化CNN网络的重要区域,提供一种可解释性视角。
2、弱监督物体识别(物体定位)。
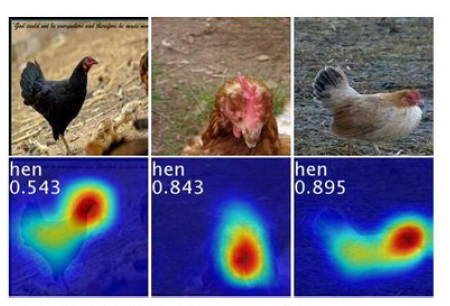
论文的方法是什么?
论文的核心是 使用CAM替换CNN网络原有的 pooling+FC结构。通过CAM的值,可以得到图片的区域“信号强度”(值越大,越重要)。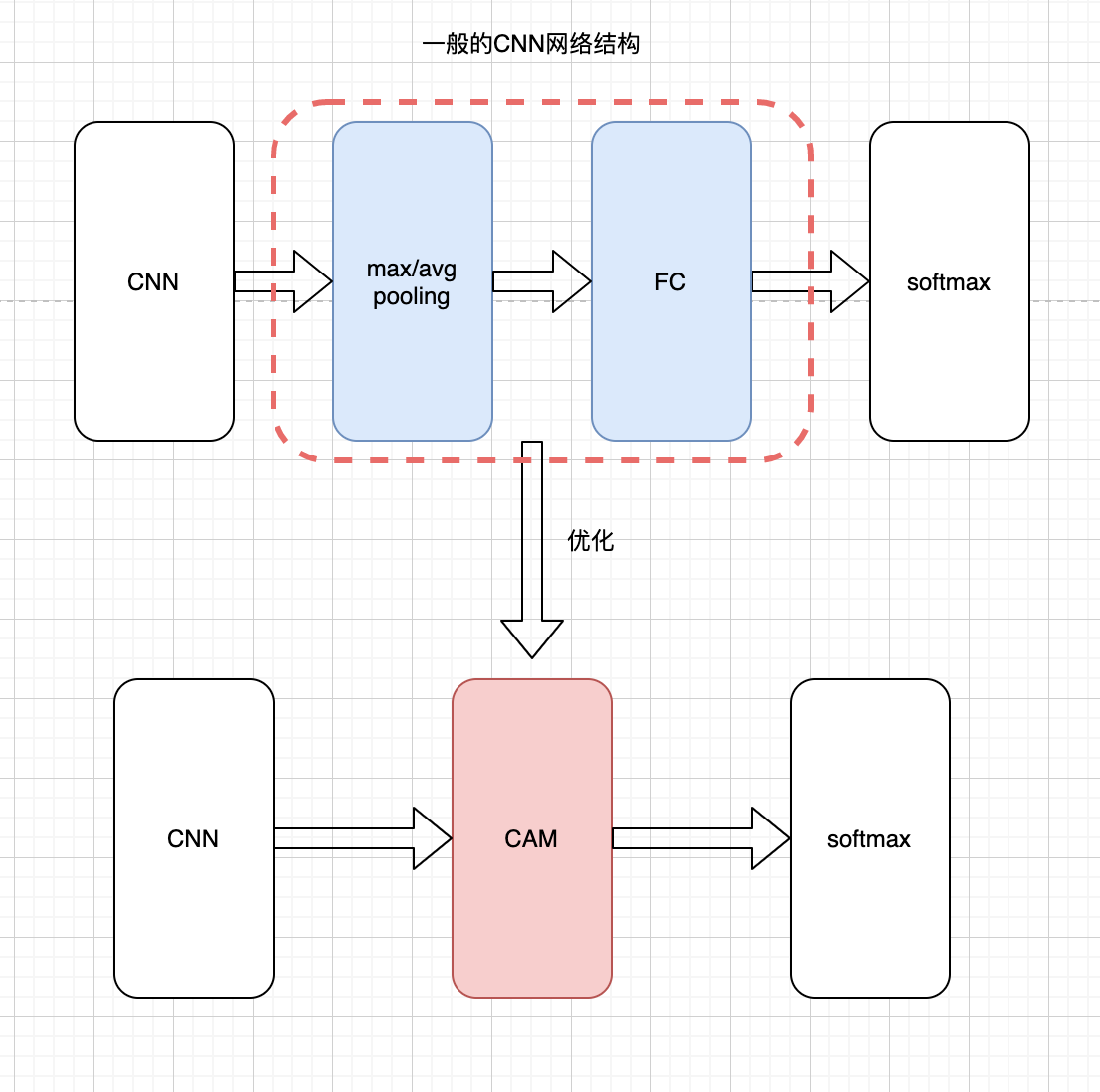
CAM结构:特征图的加权。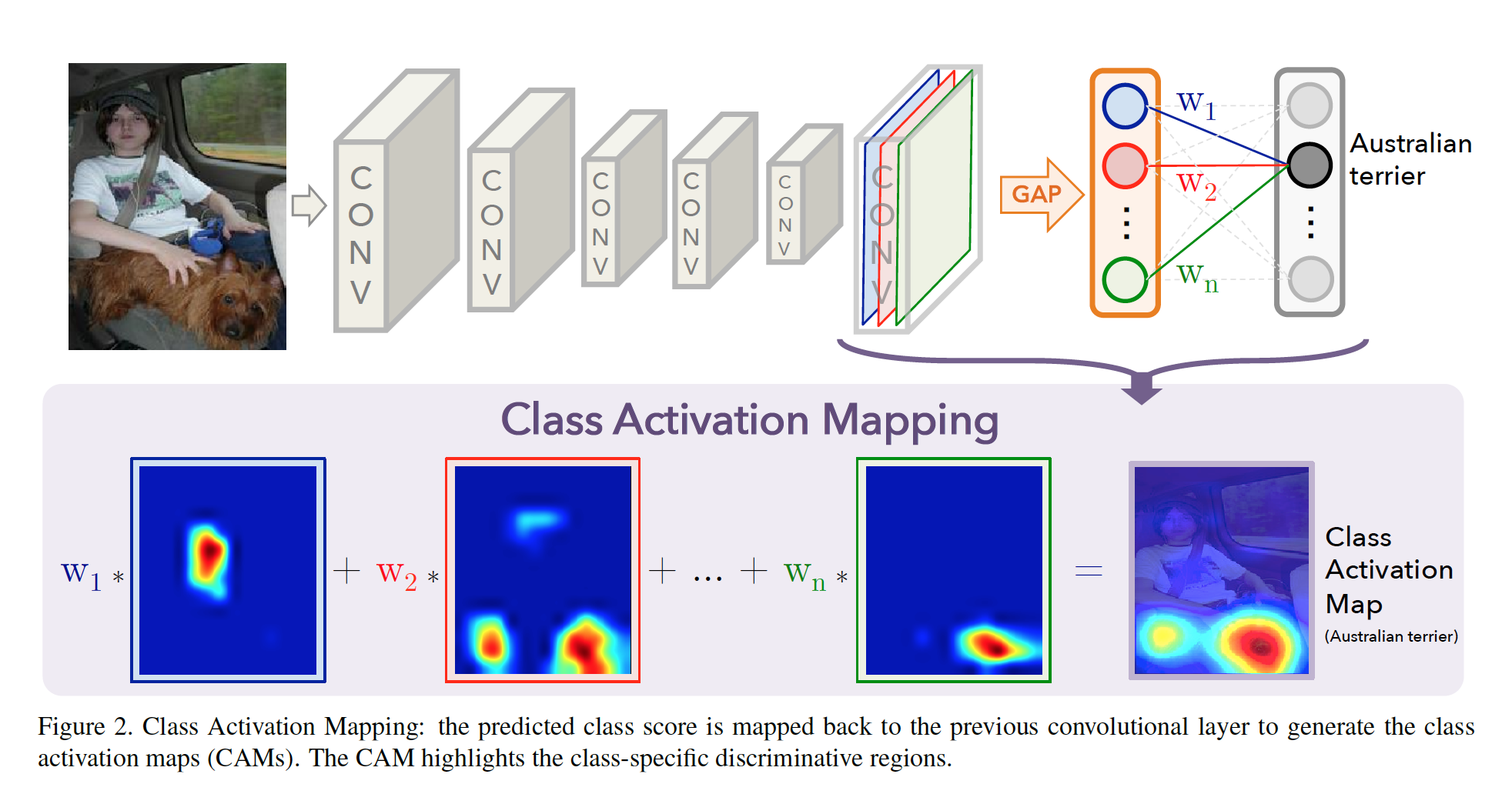
FAQ?
1、global avg pooling 和 global max pooling 都具有物体定位的能力。
avg能够识别重要的区域,所有区域对loss有贡献;max识别的是点。
2、直接使用fc ,通过reshape之后,能不能得到cam类似的效果?
猜测不能。不变性???
3、方法有什么局限性?==》改进 Grad-CAM
cam 与 softmax直接连接,限制了网络结构的多样化,牺牲部分model performance(如下图实验结果)。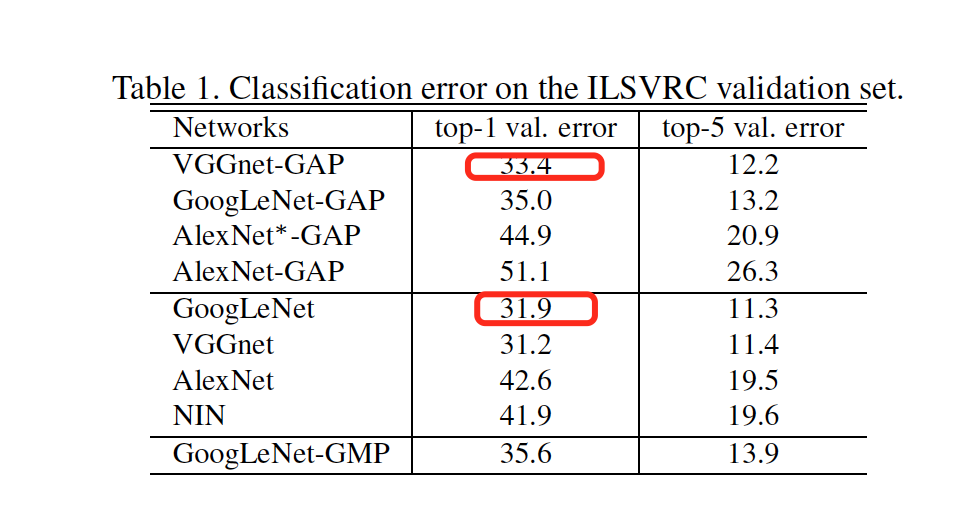

若有收获,就点个赞吧
0 人点赞
