第一步:URL解析
- 地址解析

URI/URL/URN
URI=URL+URN<br /> URI:统一资源标识符<br /> URL:统一资源定位符「URL地址」<br /> URN:统一资源名称<br />
传输协议:
http、https、ftp… 它是客户端和服务器端用来传输信息的方式“快递小哥”
http:超文本传输协议「目前最常用的」
https:http ssl 比http更安全,因为要经过ssl加密「支付类网站都需要使用https」
ftp:文件上传下载协议「往服务器端上传资源等 -> FTP上传工具(FileZilla)」
域名:
购买服务器后,一般都有一个外网IP地址,基于这个IP地址可以找到服务器;但是没有人可以记得住这个IP,所以我们要设置一个让别人好记忆的名字,这个名字就是“域名”
外网IP:供外部访问
内网IP:局域网访问
移动端测试:手机端和电脑端连接到同一个局域网下,首先保证PC端使用本机的局域网IP可以正常访问项目(例如:http://192.168.0.44:5500/index.html),这样在手机端浏览器中输入相同的地址,也可以访问到这个项目…{可能需要关闭电脑的防火墙}
——————————————————————
顶级域名:qq.com「需要买的」
一级域名:www.qq.com
二级域名:sports.qq.com
三级域名:kbs.sports.qq.com
…
com/cn/org/edu/gov/net/vip…
端口号:
0~65535 区分同一台服务器上的不同项目的
http->80<br /> https->443<br /> ftp->21<br /> 我们自己不写端口号,浏览器自己帮我们写上,这就是默认端口号<br />
URL编码:
- encodeURI & decodeURI 编码整个URL{编码的是空格和中文}
encodeURIComponent & decodeURIComponent 只编码问号传递的参数值{它的编码规则比较多,类似于://这样的特殊字符也会编码}
——-上述两个处理前后端通信中的编码和解码
escape & unescape 也可以实现编码解码,但是只能客户端不同页面之间自己用,因为很多后台都不支持这个API
let url =
http://www.qq.com/index.html?lx=1&from=${encodeURIComponent('http://www.wx.com')}&name=${encodeURIComponent('珠峰培训')};
console.log(url);第二步:缓存检查:强缓存&协商缓存
- 先检查是否存在强缓存
- 如果存在则使用强缓存信息;
- 如果不存在则在检测协商缓存,
- 如果协商缓存生效,则使用协商缓存信息
- 如果不生效,则从服务器重新拉取资源信息…
- 两种缓存针对的都是资源文件[html、css、js、image..] 而基于ajax等获取数据不存在这些所谓的强缓存和协商缓存
- 如果获取的是强缓存信息,HTTP状态码也是200【SIZE】=>MEMORY
-
html页面基本上是不做强缓存的,为啥?
一个页面的渲染都是从HTML开始的,再渲染HTML代码的时候,再去发送其它资源(例如:CSS/JS/图片…)的请求
- 一但html都做了强缓存,完了,接下来有效期内,除了ctrl+F5刷新处理,只要访问这个页面,用的都是本地缓存的内容,即使人家服务器端已经把内容更新了,你也拿不到…
如何保证其他资源在服务器更新后,即使本地有对应的强缓存信息,我们也能及时更新呢?
- 请求文件后面设置时间戳
- 文件的名字根据内容更改后,设置不同的HASH名
第一次请求:index.html
时间戳一般放文件最后一次“修改”的时间
…
缓存了:index.css?20210526181400
没有任何文件更改
第二次请求:index.html
…
获取缓存信息
程序员,更新了index.css中的代码,同时需要在index.html中把请求资源的时间戳改了
第三次请求:index.html
…
因为时间戳和上述的不同的,所以不走本地缓存,而是重新从服务器获取
———————————-webpack———————————————————————-
第一次请求:index.html
缓存:adasds433fhghj3w.css
后期程序猿修改了CSS,会生成一个新的文件名 klklkewacz5565ssds.css
第二次请求:index.html
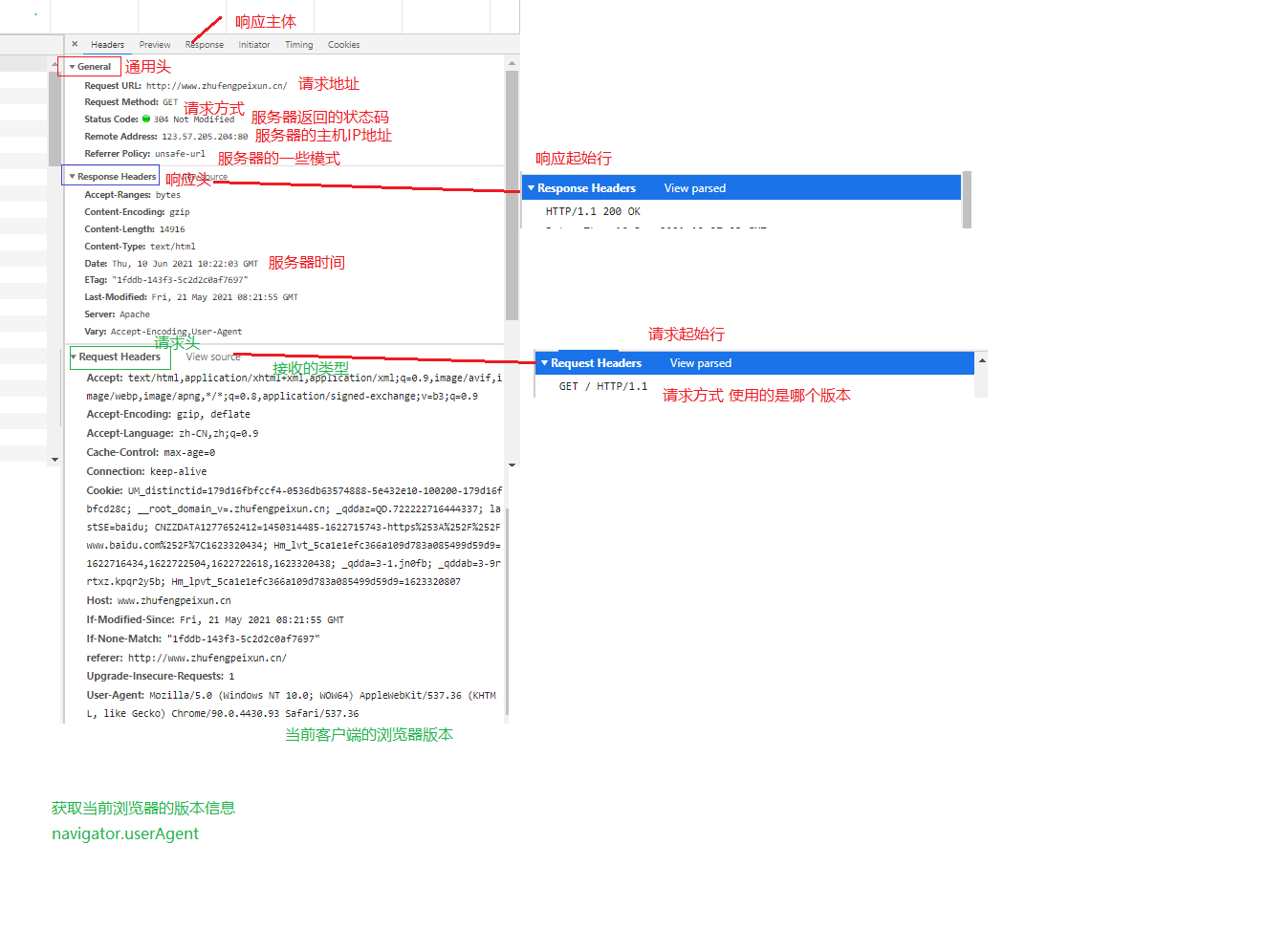
HTTP报文:客户端和服务器端所有通信的信息统称为HTTP报文
谷歌浏览器控制台->NetWork[所有通信信息]中都可以看到
- 起始行:请求起始行、响应起始行
- 首部(头):请求头、响应头【含:自定义的请求和响应头】
主体:请求主体、响应主体
请求起始行+请求头+请求主体,包含了客户端给服务器的所有信息【请求阶段 Request】
- 请求起始行
- 响应起始行+响应头+响应主体 包含了服务器返回给客户端的所有信息【响应阶段 Response】
- 一个完整的HTTP事务,包含了Request+Response

若有收获,就点个赞吧
0 人点赞
