彻底掌握基于HTTP网络层的 “前端性能优化”
产品性能优化方案
- HTTP网络层优化
- 代码编译层优化 webpack
- 代码运行层优化 html/css + javascript + vue + react
- 安全优化 xss + csrf
- 数据埋点及性能监控
- ……
CRP(Critical [ˈkrɪtɪkl] Rendering [ˈrendərɪŋ] Path)关键渲染路径
域名就是给服务器外网起个别名
从输入URL地址到看到页面,中间都经历了啥

第一步:URL解析
- 地址解析

打开网页:查找 disk cache 中是否有匹配,如有则使用,如没有则发送网络请求
普通刷新 (F5):因TAB没关闭,因此memory cache是可用的,会被优先使用,其次才是disk cache
强制刷新 (Ctrl + F5):浏览器不使用缓存,因此发送的请求头部均带有 Cache-control: no-cache,服务器直接返回 200 和最新内容强缓存 Expires / Cache-Control 状态码都是200
浏览器对于强缓存的处理:根据第一次请求资源时返回的响应头来确定的
- Expires:缓存过期时间,用来指定资源到期的时间(HTTP/1.0)
- Cache-Control:cache-control: max-age=2592000第一次拿到资源后的2592000秒内(30天),再次发送请求,读取缓存中的信息(HTTP/1.1)
- 两者同时存在的话,Cache-Control优先级高于Expires
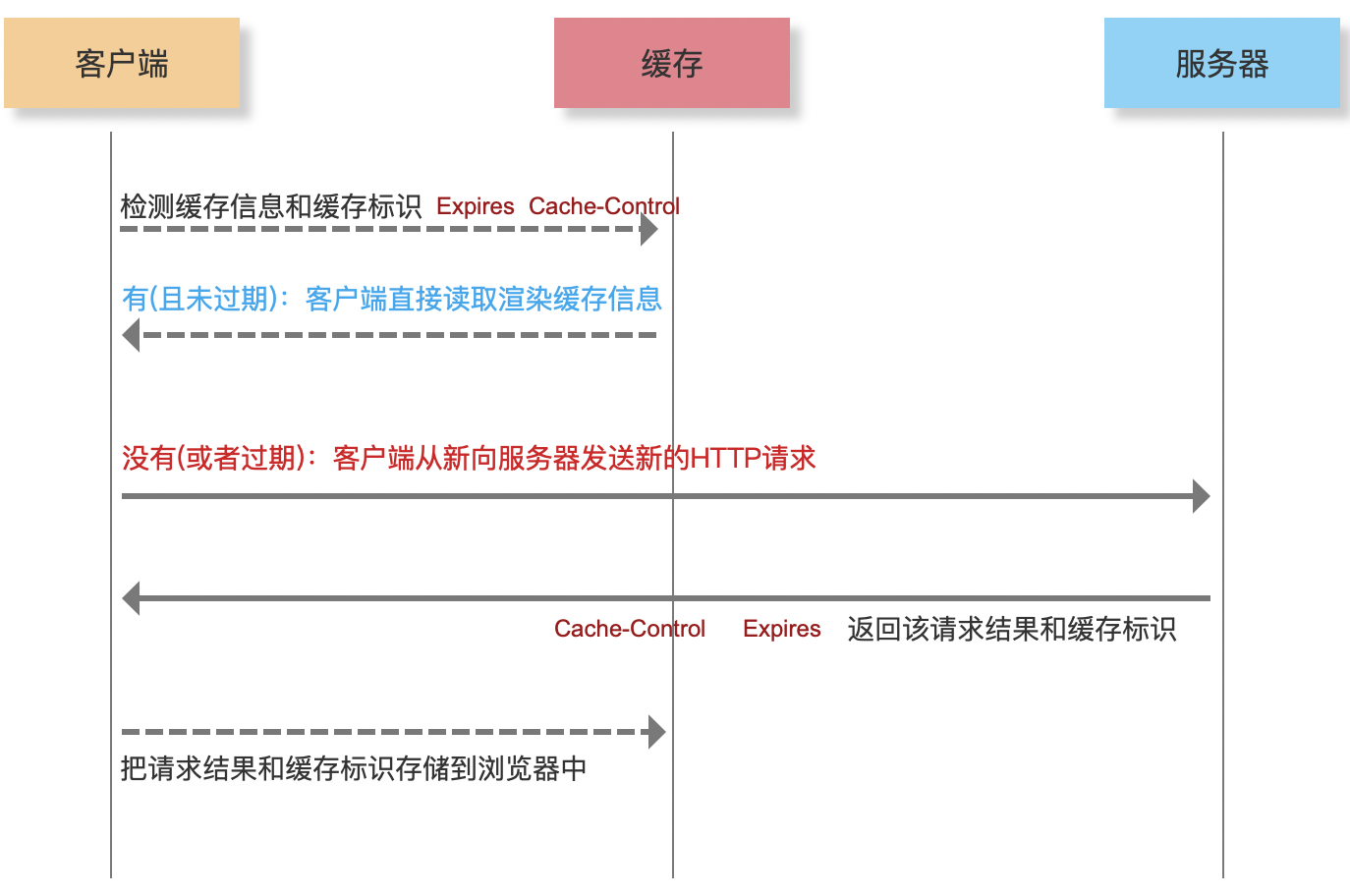
协商缓存 Last-Modified[http:1.0] / ETag[http:1.1]
- 第一次请求:客户端本地无协商缓存对应的标识,则直接向服务器发送请求;而服务器端会把资源信息给客户端「同样也会在响应头中设置对应的字段:Last-Modified(存储当前文件在服务器最后修改的时间) & Etag(服务器把当前文件修改后,可以生成一个唯一的标识) 给客户端」;客户端获取到内容后,把资源文件和标识都缓存在本地…
- 第二次请求:我们需要把本地存储的Last-Modified/Etag,基于请求头中的If-Modified-Since/If-None-Match这两个字段,传递给服务器;服务器收到对应的标识后,会去检查现有服务器文件最后修改的时间,和你传递给我的时间是否一致;
- 如果是一致的,说明这个文件从上一次请求到现在没有修改过,服务器无需重新返回文件信息,只需要返回304状态码即可;客户端获取到304状态码后,会从本地缓存中读取信息进行渲染;
- 如果不一致,说明服务器这个文件已经修改过了,此时服务器返回200的状态码,并且把最新的资源及最新的Last-Modified/Etag都返回给客户端端;客户端从新存储到本地和渲染即可…
- HTML资源不能做强缓存,但是可以做协商缓存;其它资源既可做强缓存,也可做协商缓存「很多项目中是两者都做的」
协商缓存就是强制缓存失效后,浏览器携带缓存标识向服务器发起请求,由服务器根据缓存标识决定是否使用缓存的过程
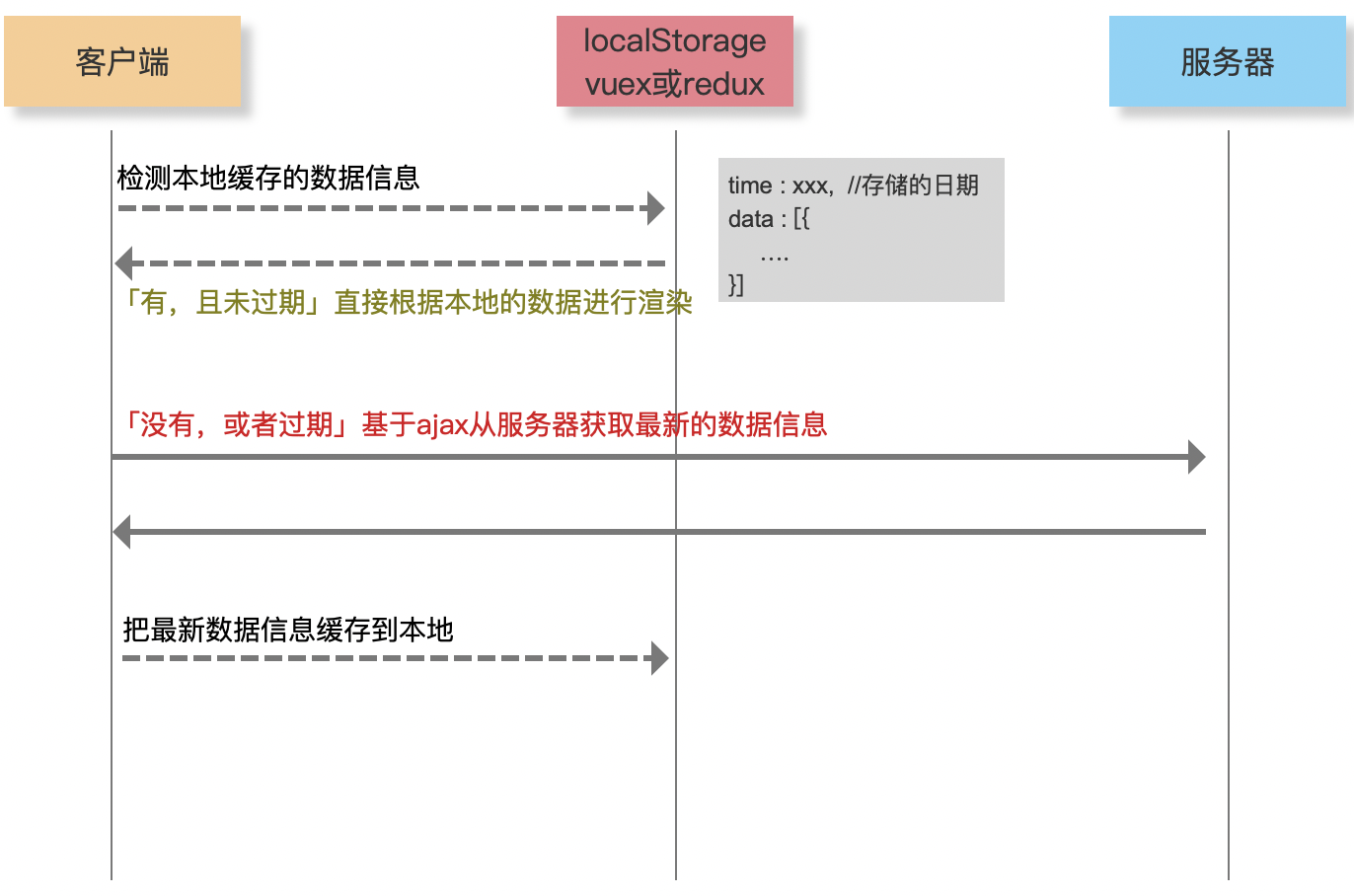
数据缓存
本地存储的解决方案
- cookie
- webstorage H5新增的
- localStorage
- sessionStorage
- IndexedDB 本地数据库存储
- WebSQL
- …
第三步:DNS解析
如果想找到服务器,则需要基于服务器的外网IP;但外网IP太难记,所以买个域名让他好记一些,所以我们需要根据域名找到服务器的外网IP【去DNS服务器上找】…这个操作就是DNS解析
DNS解析是有缓存的
- 当前如果我们解析过这个域名,则会把解析记录缓存到本地,所以每一次DNS解析一定要经历两个步骤:
- 本地DNS解析缓存查找「递归查询」
- 本地没有缓存记录,则再去公网DNS服务器上去查找「迭代查询」
- DNS阶段优化
- 减少DNS解析次数「资源都放在一个服务器/一个域名下,这样解析一次就够了」
- 但是真实项目中我们确不这样做,我们会把资源分散到不同的服务器上,这样带来的问题是,需要解析很多域名
- @1 服务器资源的合理利用
- @2 提高HTTP同时并发的数量「同源下,同时允许最多的HTTP并发数是5~7个」
- @3 提高服务器抗压能力
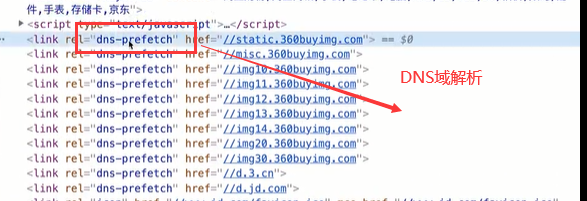
- 在DNS解析次数增加的情况下,我们可以基于 “DNS预获取(DNS Prefetch)” 进行优化
域名:万网买 万网阿里云
项目流程-》买域名 -> 域名解析「域名备案」{把域名和对应的外网IP放在DNS服务器上}
dns服务器:不属于个人,属于万维网组织的
域名解析:把域名和外网IP登记到DNS服务器
DNS解析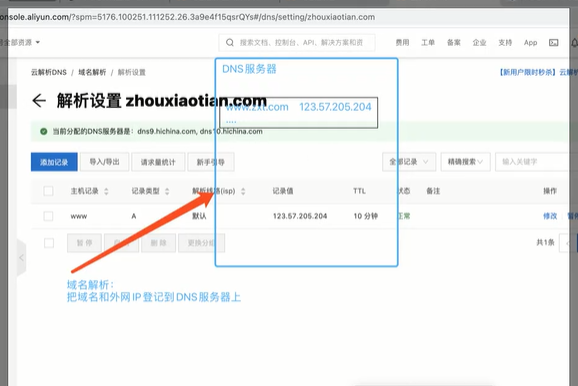
- 递归查询
- 迭代查询
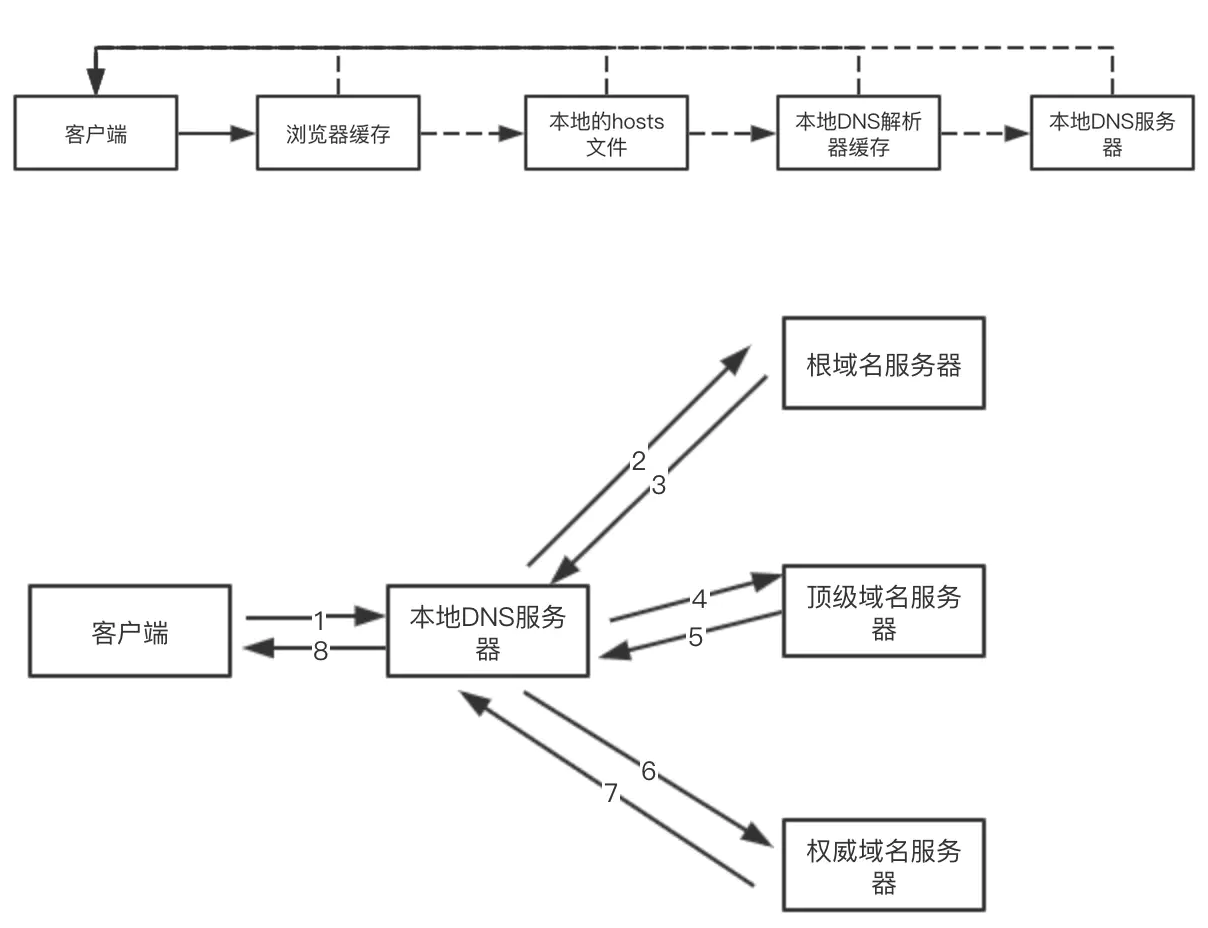
每一次DNS解析时间预计在20~120毫秒
- 减少DNS请求次数
- DNS预获取(DNS Prefetch)
<meta http-equiv="x-dns-prefetch-control" content="on"><link rel="dns-prefetch" href="//static.360buyimg.com"/><link rel="dns-prefetch" href="//misc.360buyimg.com"/><link rel="dns-prefetch" href="//img10.360buyimg.com"/><link rel="dns-prefetch" href="//d.3.cn"/><link rel="dns-prefetch" href="//d.jd.com"/>
服务器拆分的优势
- 资源的合理利用
- 抗压能力加强
- 提高HTTP并发、
- ……
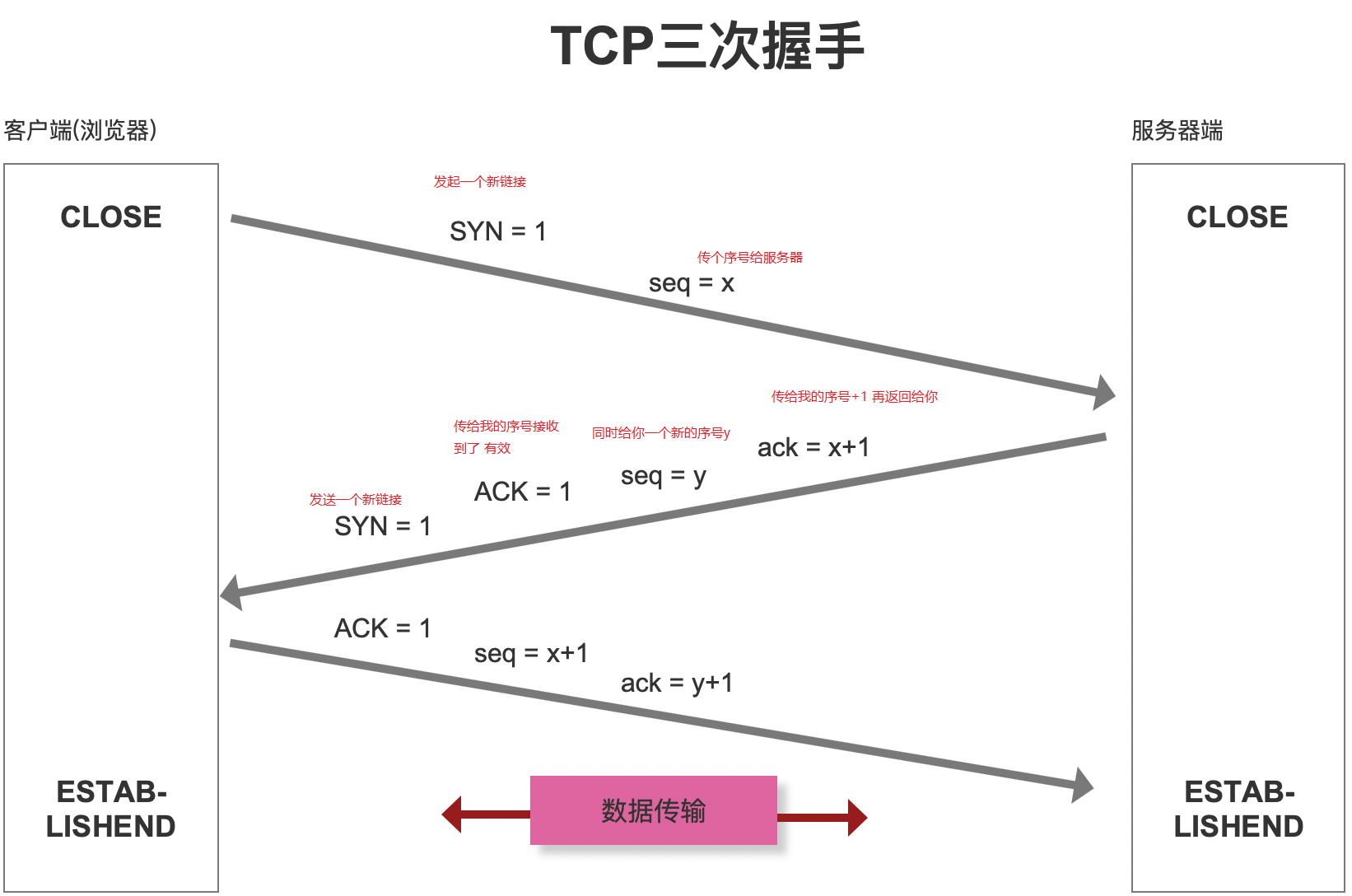
第四步:TCP三次握手
当我们获取到服务器外网IP,通过外网IP找到服务器,让客户端和服务器之间建立连接通道,
而三次握手的目的:是建立一套稳定的传输通道
传输控制协议:TCP、UDP…
- TCP:安全可靠的,但是消耗时间
- UDP:不稳定的传输通道,但是比较快「不需要经过三次握手」
- seq序号,用来标识从TCP源端向目的端发送的字节流,发起方发送数据时对此进行标记
- ack确认序号,只有ACK标志位为1时,确认序号字段才有效,ack=seq+1
- 标志位
- ACK:确认序号有效
- RST:重置连接
- SYN:发起一个新连接
- FIN:释放一个连接
- ……
三次握手为什么不用两次,或者四次?
TCP作为一种可靠传输控制协议,其核心思想:既要保证数据可靠传输,又要提高传输的效率!
第五步:数据传输
客户端想把信息传递给服务器?
- 设置请求头[含cookie信息]
- 设置请求主体
设置URL地址的问号传参
服务器如果想把嘻嘻返回给客户端
设置响应头[含服务器时间Date]
- 设置响应主体
请求方式:
- GET系列:GET、HEAD、DELETE、OPTIONS
POST系列:POST、PUT、PATCH
从服务器获取静态资源文件(HTML/CSS/JS/图片…)都是GET请求,一般只有在ajax/fetch数据请求中才会遇到其余的请求方式!
不论哪一种请求方式,客户端肯定可以把信息传递给服务器,服务器也可以把信息返回给客户端GET:从服务器获取信息「一般是给服务器的少,从服务器拿的多」
- POST:向服务器推送信息「一般是给服务器的多,服务器返回的少」
HEAD:只获取响应头信息,服务器不会返回任何响应主体信息
xhr状态 xhr.readyState
- 0 UNSENT 初始状态
1 OPENED 已打开(执行了xhr.open)
—-发送请求后
2 HEADERS_RECEIVED 响应头信息已经返回
- 3 LOADING 响应主体信息正在准备或者在返回的路上
- 4 DONE 响应主体信息返回
- DELETE:删除服务器端的文件
- PUT:向服务器端存放文件
- OPTIONS:试探性请求,在CORS跨域资源共享中,发送真正的请求之前,先发送一个试探请求,验证客户端和服务器端是否可以实现通信,可以通信,再去发送真正的请求
- GET系列请求 VS POST系列请求
- 约定规范:GET系利请求,需要基于URL问号传参,把信息传递给服务器「/api/list?xxx=xxx&xxx=xxx」;POST系列请求,是基于请求主体,把信息传递给服务器的「格式:application/json、application/x-www-form-urlencoded、multipart/form-data…」;
- GET系列传递给服务器的信息有大小限制「原因:浏览器对于URL长度有限制,IE下一般是2KB,谷歌一般是8KB」; POST系列理论上是没有的「现实开发中,为了保证传输效率,我们自己会限制大小」!
- GET相对于POST来讲不安全「都不安全,互联网面前,人人都在裸奔;对于重要信息的传输,一定要加密」
- GET会产生缓存「两次请求,地址&参数等信息都一样,则第二次请求,很可能拿到的是上一次缓存的结果」,解决办法:在每次请求的末尾加一个随机数或者时间戳,保证每次请求不完全一致!
/api/list?xxx=xxx&_=${Math.random()}- HTTP报文
- 请求报文
- 响应报文
响应状态码
- 200 OK
- 202 Accepted :服务器已接受请求,但尚未处理(异步)
- 204 No Content:服务器成功处理了请求,但不需要返回任何实体内容
- 206 Partial Content:服务器已经成功处理了部分 GET 请求(断点续传 Range/If-Range/Content-Range/Content-Type:”multipart/byteranges”/Content-Length….)
- 301 Moved Permanently
- 302 Move Temporarily
- 304 Not Modified
- 305 Use Proxy
- 400 Bad Request : 请求参数有误
- 401 Unauthorized:权限(Authorization)
- 404 Not Found
- 405 Method Not Allowed
- 408 Request Timeout
- 500 Internal Server Error
- 503 Service Unavailable
- 505 HTTP Version Not Supported
- ……
第六步:TCP四次挥手
断开客户端和服务器之间的连接通道
客户端把信息给服务器,告诉服务器,我把东西给你了,你注意查收,我要断开连接了
服务器收到信息后,立即告诉客户端,你的东西我收到了,你等会,我给你准备你想要的东西
——准备内容,返回内容
服务器把信息返回给客户端,告诉客户端,我把东西给你了,你准备接收吧,我要断开连接了
- 客户端拿到东西,告诉服务器,你的东西我收到了,咱们拜拜了
如果每次前后端通信,都需要握手和挥手,则性能消耗比较大;我们期望建立连接后,先别着急断开,后续再有请求,则还是基于这个通道传输即可 -> 机制:长链接 Connection: keep-alive 「如果是HTTP1.0版本,需要自己设置,但是如果是HTTP1.1版本{目前最常用的},则默认就设置为长链接」

为什么连接的时候是三次握手,关闭的时候却是四次握手?
- 服务器端收到客户端的SYN连接请求报文后,可以直接发送SYN+ACK报文
- 但关闭连接时,当服务器端收到FIN报文时,很可能并不会立即关闭链接,所以只能先回复一个ACK报文,告诉客户端:”你发的FIN报文我收到了”,只有等到服务器端所有的报文都发送完了,我才能发送FIN报文,因此不能一起发送,故需要四步握手。
第七步:页面渲染
性能优化汇总
/** 1.利用缓存* + 对于静态资源文件实现强缓存和协商缓存(扩展:文件有更新,如何保证及时刷新?)* + 对于不经常更新的接口数据采用本地存储做数据缓存(扩展:cookie / localStorage / vuex|redux 区别?)* 2.DNS优化* + 分服务器部署,增加HTTP并发性(导致DNS解析变慢)* + DNS Prefetch* 3.TCP的三次握手和四次挥手* + Connection:keep-alive* 4.数据传输* + 减少数据传输的大小* + 内容或者数据压缩(webpack等)* + 服务器端一定要开启GZIP压缩(一般能压缩60%左右)* + 大批量数据分批次请求(例如:下拉刷新或者分页,保证首次加载请求数据少)* + 减少HTTP请求的次数* + 资源文件合并处理* + 字体图标* + 雪碧图 CSS-Sprit* + 图片的BASE64* + ......* 5.CDN服务器“地域分布式”* 6.采用HTTP2.0* ==============* 网络优化是前端性能优化的中的重点内容,因为大部分的消耗都发生在网络层,尤其是第一次页面加载,如何减少等待时间很重要“减少白屏的效果和时间”* + LOADDING 人性化体验* + 骨架屏:客户端骨屏 + 服务器骨架屏* + 图片延迟加载* + ....*/
HTTP1.0 VS HTTP1.1 VS HTTP2.0
HTTP1.0和HTTP1.1的一些区别
缓存处理,HTTP1.0中主要使用 Last-Modified,Expires 来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略:ETag,Cache-Control…带宽优化及网络连接的使用,HTTP1.1支持断点续传,即返回码是206(Partial Content)错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除…Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)长连接,HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点
HTTP2.0和HTTP1.X相比的新特性
新的二进制格式(Binary Format),HTTP1.x的解析是基于文本,基于文本协议的格式解析存在天然缺陷,文本的表现形式有多样性,要做到健壮性考虑的场景必然很多,二进制则不同,只认0和1的组合,基于这种考虑HTTP2.0的协议解析决定采用二进制格式,实现方便且健壮header压缩,HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小服务端推送(server push),例如我的网页有一个sytle.css的请求,在客户端收到sytle.css数据的同时,服务端会将sytle.js的文件推送给客户端,当客户端再次尝试获取sytle.js时就可以直接从缓存中获取到,不用再发请求了// 通过在应用生成HTTP响应头信息中设置Link命令 Link: </styles.css>; rel=preload; as=style, </example.png>; rel=preload; as=image多路复用(MultiPlexing)```- HTTP/1.0 每次请求响应,建立一个TCP连接,用完关闭
- HTTP/1.1 「长连接」 若干个请求排队串行化单线程处理,后面的请求等待前面请求的返回才能获得执行机会,一旦有某请求超时等,后续请求只能被阻塞,毫无办法,也就是人们常说的线头阻塞;
- HTTP/2.0 「多路复用」多个请求可同时在一个连接上并行执行,某个请求任务耗时严重,不会影响到其它连接的正常执行; ```

若有收获,就点个赞吧
0 人点赞
