正则表达式,又称规则表达式。(英语:(regular /reɡjələ(r)/ expression) ,在代码中常简写为regex、regexp或RE)
正则的定义: 定义:是一种处理字符串的规则
- JS中的正则 是一种标准特殊类型值
一、正则基础
1.用来处理”字符串”的规则[匹配&捕获]
- 只能处理字符串类型的值
- 匹配:验证当前字符串是否符合我设定的规则(test)
- 捕获:把字符串中符合规则的部分捕获到(exec / match…/test)
初窥正则
let reg = /^\d+$/; //只能是数字{一到多位} ^caret符
console.log(reg.test('123')); //=>true
console.log(reg.test('123px')); //=>false
reg = /\d+/; //只要包含一到多位数字即可
console.log(reg.test('123px')); //=>true {test匹配}
console.log(reg.test('zhufengpeixun')); //=>false
console.log(reg.exec('width:123px')); //=>['123',index:6,input:原始字符串]
console.log(reg.exec('zhufengpeixun')); //=>null
2、创建正则的两种方式
字面量方式:
let reg1 = /\d+/g; //字面量:在两个斜杠之间,包含一堆“元字符”;g是修饰符;构造函数方式:当正则中的一些字符需要是变量的时候;才会选择这种方式
正则表达式中的部分内容是变量存储的值时 ```javascript //1字面量方式:不能把一个变量存储的值,作为正则的规则放进来 let aa = ‘zhufeng’; let reg = /aa/; //必须包含“aa”两个字符,和aa这个变量没关系 console.log(reg.test(aa));//false console.log(reg.test(‘aa’));//true reg = /“+aa+”/; //字面量方式中存放的不是字符串,所以本正则的意思是:”出现一到多次,跟着一个a,在跟着一个出现一到多次的a,最后跟着一个”… console.log(reg.test(aa));//false console.log(reg.test(‘“aa”‘));//true
//2.构造函数方式创建动态的把一个变量放进去 {因为它传递的规则是字符串,只有这样才能进行字符串拼接} reg = new RegExp(“@” + aa + “@”); //->”@zhufeng@” console.log(reg.test(‘haha@zhufeng@heihei’)); //=>true
<a name="82KeC"></a>
## 3.正则的用途
> 正则RegExp.prototype上的方法
> - 匹配 test
> - 编写一个正则(制定了一套规则):去测试某一个字符串是否符合这个规则;
> - 捕获 exec
> - 编写一个正则(制定了一套规则):去把某个字符串中符合这个规则的字符获取到
<a name="5LmTf"></a>
## 4.正则的组成
> 正则表达式由“元字符”&“修饰符”组成
> - 元字符
> - 量词元字符:设置出现的次数
> - 特殊元字符:单个或者组合在一起代表特殊的含义
> - 普通元字符:代表本身含义的
> - 修饰符
<a name="DoYGA"></a>
### 量词元字符如下{6个}:代表出现的次数
| 字符 | 含义 |
| --- | --- |
| * | 零到多次 |
| + | 一到多次 |
| ? | 零次或者一次 |
| {n} | 出现n次 |
| {n,} | 出现n到多次 |
| {n,m} | 出现n到m次 |
<a name="ggrJI"></a>
### 特殊元字符:有自己特殊含义的
| 字符 | 含义 |
| --- | --- |
| \\ | 转义字符(普通->特殊->普通) |
| . | 除\\n(换行符)以外的任意字符 |
| ^ | 以哪一个元字符作为开始{caret} |
| $ | 以哪一个元字符作为结束 |
| \\n | 换行符 |
| \\d | 0~9之间的一个数字 |
| \\D | 非0~9之间的字符 (大写和小写的意思是相反的) |
| \\w | 数字、字母、下划线中的任意一个字符 |
| \\W | 除了 数字、字母、下划线 的任意字符(大写W) |
| \\s | 一个空白字符(包含空格、制表符TAB、换页符Enter等) |
| \\t | 一个制表符(一个TAB键:四个空格) |
| \\b | 匹配一个单词的边界 |
| x|y | x或者y中的一个字符 |
| [xyz] | x或者y或者z中的一个字符 (与上一个的区别是:[]中前后只能写单个字符,而|前后可以是一组数) |
| [^xy] | 除了x/y以外的任意字符 |
| [a-z] | 指定a-z这个范围中的任意字符 |
| [^a-z] | 除了a-z 的任意字符 |
| [0-9a-zA-Z_]===\\w | |
| [^a-z] | 除了a-z 的任意字符 |
| () | 正则中的分组符号 和提升优先级 |
| (?:) | 只匹配不捕获 |
| (?=) | 正向预查 |
| (?!) | 负向预查 |
<a name="kabiN"></a>
### 修饰符
| i | ignoreCase 忽略单词大小写匹配 |
| --- | --- |
| m | multiline 可以进行多行匹配 |
| g | global 全局匹配 |
<a name="0DcLR"></a>
## 5. 元字符详细解读
<a name="9HyaM"></a>
### 开头^ 和 结尾$
```javascript
let reg=/\d+/;//"只要包含" 0-9连续出现的数字(-到多位)
let str='123px';
console.log(reg.test(str));//true
reg=/^\d+/;//必须以数字作为开始
let str2='新年2021快乐';
console.log(reg.test(str2));//false
reg=/\d+$/;//必须以数字作为结束
let str3='新年2021快乐';
let str4='迎来2021';
console.log(reg.test(str3));//false
console.log(reg.test(str4));//true
reg = /^\d+$/; //“只能是” 一到多位的数字 */
console.log(reg.test(str4));//false
console.log(reg.test('2020'));//true
转义\的相关练习
正则中的转义 就是把 正则中 有特殊含义的字符 转义字符本身
let reg = /^1.3$/;
console.log(reg.test('1.3')); //=>true
console.log(reg.test('1@3')); //=>true “点”在这里是除\n以外的任意字符
reg = /^1\.3$/; //把.进行转义
console.log(reg.test('1.3')); //=>true
console.log(reg.test('1@3')); //=>false 转义字符是把特殊性的“点”,转义成为本身点的意思
reg = /\\d+/; //包含 \ 和 d(可以出现一到多次) 一个\是把d变成特殊字符
console.log(reg.test('1')); //=>false
console.log(reg.test('\\d')); //=>true
console.log(reg.test('\\dddd'));//=>true
需求:验证一个字符串中是否是以 “http:// 或者 https://” 开始的
let reg = /^https?:\/\//,
url = location.href; //获取当前页面的地址
// if (reg.test(url)) {
// // 符合规则:我们发送请求
// }
console.log(reg.test('http://www.baidu.com')); //=>true
console.log(reg.test('https://www.baidu.com')); //=>true
console.log(reg.test('www.baidu.com')); //=>false
console.log(reg.test('file:///Users/Documents')); //=>false
竖|:X|Y 的相关练习
- 直接x|y会存在很乱的优先级问题,一般我们写的时候都伴随着小括号进行分组,因为小括号改变处理的优先级 =>小括号:分组
let reg = /^2|3$/;
console.log(reg.test('2')); //=>true
console.log(reg.test('3')); //=>true
console.log(reg.test('23')); //=>true ???
console.log(reg.test('4')); //=>false
reg = /^18|23$/;
//这个意思是 以18开始 或者 23结束 还可以以1开始 8或2其中的一个 3结尾
console.log(reg.test('18')); //=>true
console.log(reg.test('23')); //=>true
console.log(reg.test('1823')); //=>true ???
console.log(reg.test('123')); //=>true ???
console.log(reg.test('183')); //=>true ???
console.log(reg.test('823')); //=>true ???
console.log(reg.test('182')); //=>true ???
//解决=====分组第一个的作用:解决优先级(权重)问题 使用x|y基本上必加括号
let reg = /^(2|3)$/;
console.log(reg.test('2')); //=>true
console.log(reg.test('3')); //=>true
console.log(reg.test('23')); //=>false
console.log(reg.test('4')); //=>false
reg = /^(18|23)$/;
console.log(reg.test('18')); //=>true
console.log(reg.test('23')); //=>true
console.log(reg.test('1823')); //=>false
console.log(reg.test('123')); //=>false
console.log(reg.test('183')); //=>false
console.log(reg.test('823')); //=>false
console.log(reg.test('182')); //=>false
中括号[]的相关练习
- 中括号中出现的字符一般都代表本身的含义
- [] 中的:量词元字符 | . 不再具有特殊含义了;
- \d在中括号中还是0-9
- \w在中括号中还是数字字母下划线
let reg = /[0-9]/; //等价于 /\d/
reg = /[12]/; //等价于 /(1|2)/
reg = /[0-9a-zA-Z_]+/; //等价于 /\w+/
reg = /^[13-65]$/; //不是13到65之间的数字,而是 1或者3~6或者5 中括号中间出现的两位数,是谁或者谁
console.log(reg.test('13')); //false
console.log(reg.test('1')); //true
reg = /^[+-.]$/; //中括号中出现的所有字符,代表的都是本身的意思
console.log(reg.test('+')); //true
console.log(reg.test('-')); //true
console.log(reg.test('.')); //true
console.log(reg.test('z')); //false
// 需求:解决13~65之间的====
// + 13~19 /1[3-9]/
// + 20~59 /[2-5]\d/
// + 60~65 /6[0-5]/
let reg = /^((1[3-9])|([2-5]\d)|(6[0-5]))$/;
console.log(reg.test('13')); //true
console.log(reg.test('48')); //true
console.log(reg.test('65')); //true
console.log(reg.test('66')); //false
6.常规的正则表达式
①验证是否为有效数字
- 正负数 +10、-10、10 “可以出现可以不出现” [+-]?
- 整数 10、1、0… 一位数:0~9 两位数:不能以0开始 “必须有” (\d|([1-9]\d+))
- 小数 点后面必须有一位数字 “可以有可以没有” (.\d+)?
let reg = /^[+-]?(\d|([1-9]\d+))(\.\d+)?$/;
console.log(reg.test('-10.8'));//true
console.log(reg.test('10.8'));//true
console.log(reg.test('10'));//true
console.log(reg.test('10.0'));//true
console.log(reg.test('0'));//true
console.log(reg.test('01')); //false
②验证密码 “数字、字母、下划线 & 6~16位”
let reg = /^\w{6,16}$/
console.log(reg.test('Yaqian1228_'));//true
console.log(reg.test('1228_'));//false
③验证真实姓名 [\u4E00-\u9FA5]
- 中国姓名 汉字组成 2~4位
- 迪丽热巴·迪力木拉提
let reg = /^[\u4E00-\u9FA5]{2,}(·[\u4E00-\u9FA5]{2,})?$/;
console.log(reg.test('赵')); //false
console.log(reg.test('赵四'));//true
console.log(reg.test('尼古拉斯·赵四'));//true
console.log(reg.test('迪丽热巴·迪力木拉提'));//true
console.log(reg.test('刘伟'));//true
console.log(reg.test('王光明森'));//true
④验证邮箱
- 邮箱名字 \w+((-\w+)|(.\w+))*
- 数字、字母、下划线、中杠、点
- 不能以 中杠 和 点 做为开始
- 不能连续出现两个及以上的 点 和 中杠
- 邮箱后缀 [A-Za-z0-9]+((.|-)[A-Za-z0-9]+)*.[A-Za-z0-9]+
- 域名都是 数字、字母
- 可能出现 中杠 和 点
- .[A-Za-z0-9]+ 最后必须有 .com/.cn/.xx
- ((.|-)[A-Za-z0-9]+)* 应对 .xxx或者-xxx的情况,但是这种情况可能不出现
let reg = /^\w+((-\w+)|(\.\w+))*@[A-Za-z0-9]+((\.|-)[A-Za-z0-9]+)*\.[A-Za-z0-9]+$/;
⑤身份证号码
分组()的第二个作用:分组捕获,正则在捕获的时候,除了可以把大正则匹配的信息捕获到,而且还可以把正则中每一个小分组匹配的信息单独捕获到;如果写了分组,但是不想在捕获的时候捕获,需要加 ?:
//let reg = /^\d{17}(X|\d)$/ 简单来写
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(?:\d|X)$/;
let str = '130481199801291662';
console.log(reg.exec(str));
//返回一个数组
// ["130481199801291662", "130481", "1998", "01", "29", "6"]
// 前六位 省市县
// 中间八位 出生年月日
// 倒数第二位 奇数 男 偶数 女 */
二、正则的匹配(test)
编写一个正则(制定了一套规则):去测试某一个字符串是否符合这个规则;
1、语法
另外分享一个正则查找工具:菜鸟工具
三、正则的捕获
编写一个正则(制定了一套规则):去把某个字符串中符合这个规则的字符获取到
1.实现正则捕获的办法:
RegExp.prototype
- exec
-
String.prototype
replace
- match
- split
-
2.exec详解
-1)、语法
-
-2)、前提
实现正则捕获的前提是:当前正则要和字符串匹配,如果不匹配捕获的结果是null
let str = "xiaozhima2019xiaozhima2020xiaozhima2021";
let reg = /^\d+$/;
console.log(reg.test(str)); //=>false
console.log(reg.exec(str)); //=>null
-3)、返回值
- 找到了匹配的文本, 则返回一个数组
- 数组中第一项:本次捕获到的内容
- 其余项:对应小分组本次单独捕获的内容
- index:当前捕获内容在字符串中的起始索引
- input:原始字符串
- ……
- 找不到则否则返回
nulllet str = "欢度2021欢度2021"; let reg = /\d+/; console.log(reg.exec(str));-4).捕获的特点
① 正则捕获的“懒惰性”
- 正则捕获是具备“懒惰性”的:默认情况下,正则每一次捕获,只能把第一个匹配的信息捕获到,其余匹配的信息无法获取
- reg.lastIndex 存储的是下一次正则捕获的时候,从字符串的哪个索引开始查找,默认是0
- 懒惰性的原因就是因为:每一次捕获完,正则的lastIndex值是不变的,所以下一次捕获还是从零开始,找到的还是第一个匹配的结果…
let reg = /\d+/,
str = 'zhufeng2020peixun2021yangfan2022qihang2023';
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //['2020'...] //只捕获第一个匹配
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //['2020'...]
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //['2020'...]
console.log(reg.lastIndex); //0
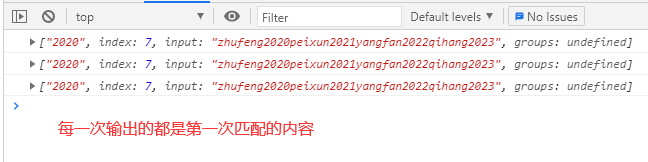
懒惰性的解决办法
给正则设置一个全局修饰符g, 让其全局匹配「可以改变lastIndex的值」,从而解决懒惰性问题
let reg = /\d+/g,
str = 'zhufeng2020peixun2021yangfan2022qihang2023';
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //['2020'...]
console.log(reg.lastIndex); //11 每次的lastIndex是上一次捕获完成的上一项
console.log(reg.exec(str)); //['2021'...]
console.log(reg.lastIndex); //21
console.log(reg.exec(str)); //['2022'...]
console.log(reg.lastIndex); //32
console.log(reg.exec(str)); //['2023'...]
console.log(reg.lastIndex); //42
//在所有内容捕获完后,在此捕获时:捕获不到内容,返回null
//lastIndex恢复初始值0 再次捕获时又从第一个开始了
console.log(reg.exec(str)); //null
console.log(reg.lastIndex); //0
console.log(reg.exec(str)); //['2020'...]
需求练习:编写一个方法execAll,执行一次可以把所有匹配的结果捕获到
this.global 判断该正则是否加入了g修饰符
- 加了 true
- 没加 false
RegExp.prototype.execAll = function execAll(str) {
// this -> 处理的正则reg str -> 匹配的字符串
// 没有加G我们就匹配一次
if (!this.global) return this.exec(str);
// 加G后,则循环匹配完
let results = [],
result = this.exec(str);
while (result) {
results.push(result[0]);
result = this.exec(str);
}
// 如果一次都没有匹配上,则直接返回null即可
return results.length === 0 ? null : results;
}
let reg = /\d+/g,
str = 'zhufeng2020peixun2021yangfan2022qihang2023';
console.log(reg.execAll(str));
Math
字符串中有一个方法,默认就具备了execAll的功能
let reg = /\d+/g,
str = 'zhufeng2020peixun2021yangfan2022qihang2023';
console.log(str.match(reg)); //["2020", "2021", "2022", "2023"]
console.log(str.match(/\d+/)); //['2020',...] 正则不加G也只捕获一次即可,结果和exec一样
console.log(("zhufeng").match(/\d+/g)); //null
②正则捕获的“贪婪性”
默认情况下,正则每一次捕获的结果都是按照其”最长“匹配的信息捕获
let reg = /\d+/,
str = 'zhufeng2020';
console.log(reg.exec(str)); //["2020"...]
?如果左边是一个非量词元字符,那么它本身代表量词,出现零到一次
如果左边是一个量词元字符,则是取消正则捕获的贪婪性
let reg = /\d+?/g,
str = 'zhufeng2020';
console.log(reg.exec(str)); //["2"...]
console.log(reg.exec(str)); //["0"...]
3.字符串中 match 方法 捕获
如果没有捕获则是null
let time = "{0}:{1}:{2}",
reg = /\{(\d+)\}/g;
console.log(reg.exec(time)); //["{0}","0"...]
console.log(reg.exec(time)); //["{1}","1"...]
console.log(reg.exec(time)); //["{2}","2"...]
// match虽然好用,但是也有自己的局限性:在正则设置了g的情况下,执行一次match,虽然可以把大正则匹配的信息都捕获到,但是无法捕获到小分组中的信息... 而exec方法,虽然要执行多次,但是每一次,不仅大正则匹配的信息捕获到了,而且每一个小分组匹配的信息也拿到了...
console.log(time.match(reg)); //["{0}", "{1}", "{2}"]
match和esec的区别
- 1、设置全局修饰符 g 的情况下:
- exec 每次执行只能捕获一个匹配的结果
- 当前结果中包含大正则和小分组匹配的结果
- 如果想要捕获全,需要执行多次
- match 执行一次就能把所有正则匹配的信息捕获到
- 只有大正则匹配的,并不包含小分组匹配的信息
- exec 每次执行只能捕获一个匹配的结果
- 2、如果不设置 g 的情况下:
let reg = /\d+/g,
str = 'zhufeng2020';
console.log(reg.lastIndex); //0
if (reg.test(str)) {
console.log(reg.lastIndex); //11
console.log(reg.exec(str)); //null
}
需求:获取身份证信息
let reg = /^(\d{6})(\d{4})(\d{2})(\d{2})\d{2}(\d)(?:X|\d)$/,
str = '130481199801291662';
// 符合格式:获取对应的信息
if (reg.test(str)) {
// 符合格式:获取对应的信息
// console.log(reg.exec(str));
// console.log(str.match(reg));
// ** test匹配后,我们可以基于 RegExp.$1~$9 拿到当前这次匹配,第一个分组~第九个分组捕获的信息
//console.dir(RegExp);
console.log(`曹小怂的生日:${RegExp.$2}年${RegExp.$3}月${RegExp.$4}日`);
}
5.split
var arr = time.split(/(?:\/|:| )/g); //在全局中 arr以/或者:或者空格进行分割

四、正则的其他常用知识点
1、分组()的三大作用
-1)、分组的第一个作用:改变优先级
分组第一个的作用:解决优先级(权重)问题 使用x|y基本上必加括号
-2)、分组的第二个作用:分组捕获
let time = "{0}:{1}:{2}",
reg = /\{(\d+)\}/g;
console.log(reg.exec(time)); //["{0}","0"...]
-3)、 分组的第三个作用:分组引用
分组引用就是通过“\数字”让其代表和对应分组出现一模一样的内容
// \1出现和第一个分组一模一样的内容 ... \n出现和第N个分组一模一样的内容
//abbc类型
let reg = /^[a-z]([a-z])\1[a-z]$/;
// book food zoom feed week ...
//abba类型
console.log(reg.test("book")); //=>true
console.log(reg.test("zoom")); //=>true
reg = /^([a-z])([a-z])\2\1$/; //=>第一位要和最后一位一样 第二位要和第三位一样
// noon mvvm oppo ... */
console.log(reg.test("noon")); //=>true
2、问号?在正则中的五大作用:
- ?本身是量词元字符,代表出现0~1次 =问号左边是非量词元字符:本身代表量词元字符,出现零到一次
- 取消正则捕获的贪婪性 =>问号左边是量词元字符:取消捕获时候的贪婪性
- (?:) 只匹配不捕获
- (?=) 正向预查 (必须得包含什么)
- (?!) 负向预查 (必须不能有什么)
3、字符串中和正则搭配的捕获方法之—— replace
- 语法:str = str.replace(reg,function)
- 特点:
- 1、首先拿正则和字符串去匹配,每匹配一次,都会把“回调函数”执行一次
- 2、并且会把每次正则和字符串捕获的结果(基于EXEC 数组),分别传递给回调函数
- 回调函数的参数 第一个是大正则匹配 信息 第二个参数是第一个分组匹配的信息 以此类推
- 3、每一次回调函数中返回啥,都相当于把当前大正则匹配的结果替换成啥
1)单词首字母大写
let str = "good good study,day day up!",
reg = /\b([a-zA-Z])([a-zA-Z]*)\b/g;
str = str.replace(reg, function (val, $1, $2) {
// 回调函数执行6次
// val是大正则匹配的信息 $1 第一个分组匹配的信息 $2 第二个分组匹配的信息
// val 第一次 good
// $1 第一次 g
// $2 第一次 ood
return $1.toUpperCase() + $2;
});
console.log(str);
2)验证一个字符串中那个字母出现的次数最多,多少次?
思路一:
循环字符串中的每一项,把每一项作为一个对象的键值对存储起来「每一个字符作为属性名,属性值是它出现的次数,最开始是1」;在从对象中找出最多出现的次数;按照出现的次数,找到对应的字母…
let str = "zhufengpeixunzhoulaoshi";
let obj={},
max=1;
for(let i=0;i<str.length-1;i++){
if(!obj[str[i]]){
obj[str[i]]=1;
continue;
}
obj[str[i]]++;
};
// 按照最大次数找到对应的字母
for (let key in obj) {
if (!obj.hasOwnProperty(key)) break;
if (obj[key]>max) {
max=obj[key];
}
};
for(let key in obj){
if (!obj.hasOwnProperty(key)) break;
if (obj[key]===max) {
console.log(`当前字母:${key},出现了:${max}次!!`);
}
};
思路二:首先把字母排序
let str = "zhufengpeixunzhoulaoshi";
str = str.split('').sort((a, b) => a.localeCompare(b)).join(''); //"aeefghhhiilnnoopsuuuxzz"
let reg = /([a-zA-Z])\1+/g,
max = 2, //记录最大出现的次数
obj = {}; //记录每个字母出现的次数
str.replace(reg, (val, $1) => {
// val 大正则匹配的 例如:“ee” val.length:字母出现的次数
// $1 第一个分组匹配的 例如:“e”
let n = val.length;
if (n > max) max = n;
obj[$1] = n;
});
// 从obj中找出所有出现max次的字母
for (let key in obj) {
if (!obj.hasOwnProperty(key)) break;
if (obj[key] === max) {
console.log(`当前字母:${key},出现了:${max}次!!`);
}
}
五、正则的实际应用
案例1:把时间字符串进行处理
formatTime:时间字符串的格式化处理 @params templete:[string] 我们最后期望获取日期格式的模板 模板规则:{0}->年 {1~5}->月日时分秒 @return [string]格式化后的时间字符串
String.prototype.formatTime = function formatTime(template) {
// this -> str 要处理的时间字符串
//@1如果不传递参数 则默认给一个模板
if (typeof template === "undefined") template = "{0}年{1}月{2}日 {3}时{4}分{5}秒";
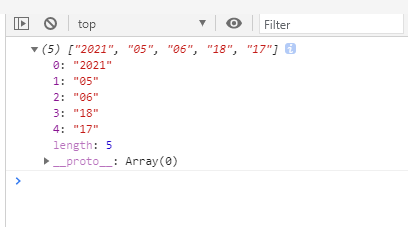
// 1.先获取到时间字符串中的“年月日时分秒”信息
let arr = this.match(/\d+/g); //["2021", "5", "5", "17", "25", "3"]
// 2.把template模板中的“{数字}”替换成为arr数组中的某一项,而且{}中的数字就是我们从arr中取值的索引
return template.replace(/\{(\d+)\}/g, (val, $1) => {
let item = arr[$1] || "00"; //假设str='2021/5/5' 的时候
if (item.length < 2) item = '0' + item;//当捕获的长度小于2 则补0
return item;
});
};
/* let str = '2021/5/5 17:25:3'; //变为 “05月05日 17:25” “2021年05月05日” “05-05 17:25” ...
console.log(str.formatTime());
console.log(str.formatTime('{1}月{2}日 {3}:{4}'));
console.log(str.formatTime('{0}年{1}月{2}日'));
console.log(str.formatTime('{1}-{2} {3}:{4}'));
案例2:处理URL参数
queryURLParams:获取URL地址问号和面的参数信息(可能也包含HASH值) @params @return [object]把所有问号参数信息以键值对的方式存储起来并且返回
String.prototype.queryURLParams = function queryURLParams() {
// this->url
let obj = {};
this.replace(/#([^?&#=]+)/g, (_, $1) => obj['HASH'] = $1);
this.replace(/([^?&#=]+)=([^?&#=]+)/g, (_, $1, $2) => obj[$1] = $2);
//([^?&#=]+)=>name{左边} = ([^?&#=]+)=>xxx{右边}
return obj;
};
let url = 'http://www.zhufengpeixun.cn/index.html?name=xxx&age=12#teacher';
console.log(url.queryURLParams());
// {name:'xxx',age:'12',HASH:'teacher'}
案例3:实现千分符处理
millimeter:实现数字的千分符处理 @params @return [string]千分符后的字符串
String.prototype.millimeter = function millimeter() {
//\d{1,3} 出现1到3次
//(?=(\d{3})*$)0-9之间的数据{末尾只能是三位}
let result = this.replace(/\d{1,3}(?=(\d{3})*$)/g, val => val + ',');
return result.substring(0, result.length - 1);
};
let str = '12343424567';
console.log(str.millimeter());

若有收获,就点个赞吧
0 人点赞
