我可能还没有透彻理解 python 对正则表达式的实现,其中的“match”的边界条件是什么。所以这几天(2021.06.11)的实践中,遇到一些困惑。
TL; DR
当显性定义一个捕获组时,python 似乎默认将其余内容自动视为非捕获组处理,从而如果想要整体捕获的话,需要调整 pattern 的写法:1)显性表达捕获组、2)小括号不能再用于表示“分组”,必须改写为非捕获组。
问题发现
对于字符串(123.45678, 987,65432) 5,想要将其中的数字(含小数点)都提取出来。
- 括号中是经纬度坐标,对于南半球、西半球,会是负数。
- 最后一个数字是距离,都是非负数。
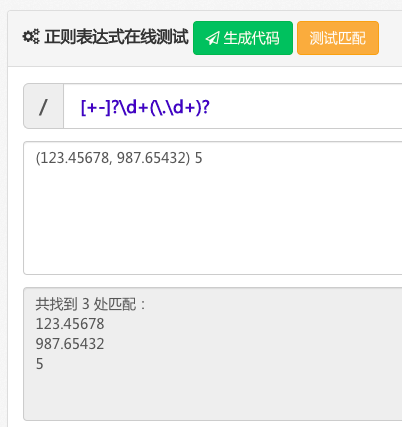
我写的 pattern 是r'[+-]?\d+(\.\d+)?',在 python 中使用 raw string 避免\的转义。
import retext = '(123.45678, 987.65432) 5'pattern = r'[+-]?\d+(\.\d+)?'matches = re.findall(pattern, text)print(len(matches))for match in matches:print('[%s]' % match)
期待结果:
3[123.45678][987.65422][5]
实际结果:
3[.45678][.65432][]
What did I do wrong?
在 Sublime Text 以及 https://c.runoob.com/front-end/854 测试中都可以正常检索。
 |
 |
|---|---|
Thus, why?
查询资料
参考 Stack Overflow 对另一个问题的描述:Issues with Python re.findall when matching variables
Question:

Best Answer:
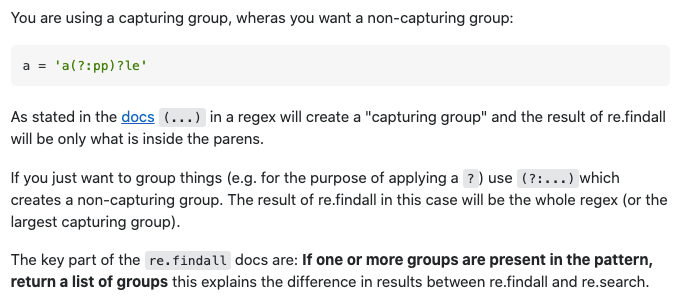
根据这项解释,无法取到完整的小数点前的数字,是因为在 pattern r'[+-]?\d+(\.\d+)?'中,只有红色部分被作为捕获组(Capturing Group),其余表达式被匹配但没有被捕获。
所以将 pattern 改为r'[+-]?\d+(?:\.\d+)'之后,可以正确匹配两个经纬度坐标123.45678、987.65432,但很显然5被抛弃了。
我当然用别的办法绕开了这个问题,但还想深入研究一下。
一些研究
做了一些实验。
text = (123.45678, 987.65432) 5
| pattern | match result | note |
|---|---|---|
r'[+-]?\\d+(?:\\.\\d+)' |
2 [123.45678] [987.65432] |
|
r'[+-]?\\d+(?:\\.\\d+)|\\d+' |
3 [123.45678] [987.65432] [5] |
|
r'([+-]?)(\\d+)(\\.\\d+)?' |
3 [(‘’, ‘123’, ‘.45678’)] [(‘’, ‘987’, ‘.65432’)] [(‘’, ‘5’, ‘’)] |
|
r'([+-]?\\d+(\\.\\d+)?)' |
3 [(‘123.45678’, ‘.45678’)] [(‘987.65432’, ‘.65432’)] [(‘5’, ‘’)] |
|
r'(\\d+)\\.(\\d+)' |
2 [(‘123’, ‘45678’)] [(‘987’, ‘65432’)] |
A |
r'(\\d+)(\\.)(\\d+)' |
2 [(‘123’, ‘.’, ‘45678’)] [(‘987’, ‘.’, ‘65432’)] |
B |
r'(\\d+)((\\.)(\\d+))' |
2 [(‘123’, ‘.45678’, ‘.’, ‘45678’)] [(‘987’, ‘.65432’, ‘.’, ‘65432’)] |
C |
r'(\\d+)((\\.)(\\d+))?' |
3 [(‘123’, ‘.45678’, ‘.’, ‘45678’)] [(‘987’, ‘.65432’, ‘.’, ‘65432’)] [(‘5’, ‘’, ‘’, ‘’)] |
D |
特别注意对比 A、B、C、D 四种情况。
总结规律可以发现,match 是对于整个字符串而言,完整的 pattern,所有不相互重叠的匹配结果。其中每一个匹配上的捕获组,都作为一个 group 被捕获(capture)和返回,尤其是 group 可以是符合匹配关系的空字符串。所以当存在多个捕获结果时,一个 match 的内容会以元组(tuple)的方式返回多个值。
从结果上来看值得注意的是,当显性定义一个捕获组时,python 似乎默认将其余内容自动视为非捕获组处理。从而引发了本文开头中令人困惑的情况。习惯使用 C# 和 Sublime Text 的我,一时间没注意到。
所以,本文开头想要的效果,可以通过这个 pattern 来实现r'([+-]?\d+(?:\.\d+)?)',在这个规则中,令可出现可不出现的部分为非捕获组,显性地令整体作为捕获组,从而实现整个 match 作为一个 group 返回,其中“小数点及其后的数字”可有可无。
输出结果:
3[123.45678][987.65432][5]
补充说明
补充一些官方文档(3.9.5)对主要用法的说明:https://docs.python.org/3/library/re.html
re.match() 匹配方法

(…) 捕获组

(?:…) 非捕获组

To sum up, humm, interesting yet disturbing.

若有收获,就点个赞吧
0 人点赞
