堆的定义:n个元素的序列{k1, k2, ki, … , kn},当且仅当满足一下关系时,称为堆。
关系:
即堆需要满足:堆中某个节点的值总是不大于或不小于其父节点的值。
- 最大堆/大根堆:根节点最大的堆
- 最小堆/小根堆:根节点最小的堆
常见的堆有二叉堆、斐波那契堆。
为了便于索引,常用完全二叉树来构建堆。
- 满二叉树:一个二叉树,如果每一个层的结点数都达到最大值,则这个二叉树就是满二叉树。也就是说,如果一个二叉树的层数为K,且结点总数是(2^k) -1 ,则它就是满二叉树。
- 完全二叉树:一棵深度为k的有n个结点的二叉树,对树中的结点按从上至下、从左到右的顺序进行编号,如果编号为i(1≤i≤n)的结点与满二叉树中编号为i的结点在二叉树中的位置相同,则这棵二叉树称为完全二叉树。
(在完全二叉树中个,除了最底层,其他每一层的节点都是满的。在最底层,我们从左往右填充节点。)
根据堆的索引关系,可以利用一个一维数组来建立堆。
二叉堆的实现
实现二叉堆时,可以使用完全二叉树的结构来实现。这样有两个好处:
- 完全二叉树是一颗平衡的数,能够保证对数性能 ;
- 完全二叉树可以使用list实现。
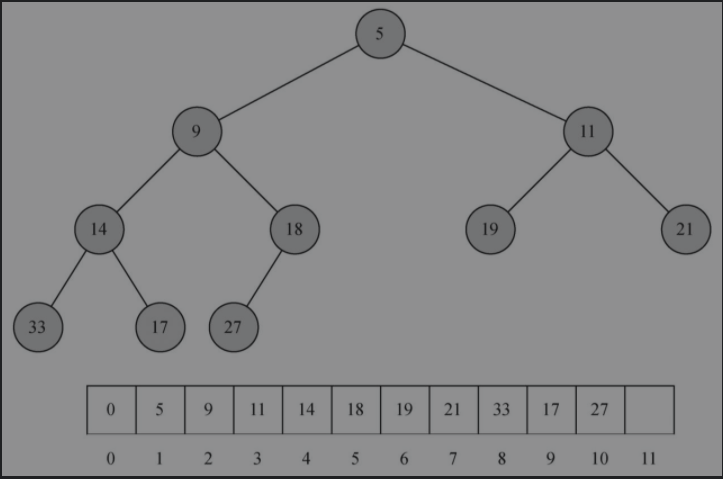
父节点的index为i,那么左子节点index为2i,右子节点index为2i+1。
堆有两个重要操作,时间复杂度O(logk)。以小根堆为例:
- 上浮sift_up:向堆尾新加入一个元素,堆规模+1,依次向上与父节点比较,如小于父节点就交换;
- 下沉sift_down:从堆顶取出一个元素,堆规模-1,依次向下与子节点比较,如大于子节点就交换。
对于top k问题:最大堆求topk小,最小值求topk大。
- topk小:构建一个k个数的最大堆,当读取的数小于根节点时,替换根节点,重新塑造最大堆
- topk大:构建一个k个数的最小堆,当读取的数大于根节时,替换根节点,重新塑造最小堆。
上浮操作sift up
含义:新元素加入堆尾,上浮维护堆使其有序
def sift_up(heap, k):val = heap[k]# k // 2 为当前索引k的父节点# 小根堆,要求根节点小于子节点。如果根节点大于子节点,则需要调整顺序while k // 2 > 0 and val < heap[k // 2]:# 交换节点heap[k], heap[k // 2] = heap[k // 2], heap[k]k //= 2
下沉操作sift down
含义:新元素从索引root处(可以理解为根位置)插入元素,不断下沉调整,使堆保持有序
k为堆大小
def sift_down(heap, index, k):val = heap[index]while index * 2 < k:left = index * 2 # root节点的左节点索引right = index * 2 + 1 # root右节点索引if left < k and right < k:if heap[left] <= heap[right] and heap[left] <= heap[index]:# 交换left, indexheap[left], heap[index] = heap[index], heap[left]

若有收获,就点个赞吧
0 人点赞
