SQL基本教程
SQL SELECT 语句
SELECT 语句用于从数据库中选取数据。
SELECT column_name,column_nameFROM table_name;SELECT * FROM table_name;
SQL SELECT DISTINCT 语句
SELECT DISTINCT 语句用于返回唯一不同的值(去重查询)
select DISTINCT Receivename FROM SellerCube..ProfitReportBill where SendDate>='2022-10-1 00:00:00' and SendDate<'2022-10-02 00:00:00'AND warehouseTypeStr='国内仓'
SQL WHERE 子句
WHERE 子句用于过滤记录,提取那些满足指定条件的记录。
SELECT * FROM Websites WHERE country='CN';下面的运算符可以在 WHERE 子句中使用:运算符 描述= 等于<> 不等于。注释:在 SQL 的一些版本中,该操作符可被写成 !=> 大于< 小于>= 大于等于<= 小于等于BETWEEN 在某个范围内LIKE 搜索某种模式IN 指定针对某个列的多个可能值
SQL AND & OR 运算符
AND & OR 运算符用于基于一个以上的条件对记录进行过滤。
如果第一个条件和第二个条件都成立,则 AND 运算符显示一条记录。
如果第一个条件和第二个条件中只要有一个成立,则 OR 运算符显示一条记录。
SELECT * FROM WebsitesWHERE country='CN'AND alexa > 50;SELECT * FROM WebsitesWHERE country='USA'OR country='CN';
SQL ORDER BY 关键字
ORDER BY 关键字用于对结果集进行排序。
ORDER BY 关键字用于对结果集按照一个列或者多个列进行排序。
ORDER BY 关键字默认按照升序对记录进行排序。如果需要按照降序对记录进行排序,您可以使用 DESC 关键字。
SELECT column_nameFROM table_nameORDER BY column_name ASC|DESC;-- desc 是【 describe v.描述】 和【descend v.下降】 的缩写-- asc 是【ascend 升序意思】
SQL INSERT INTO 语句
INSERT INTO 语句用于向表中插入新记录。
-- 第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:INSERT INTO table_nameVALUES (value1,value2,value3,...);-- 第二种形式需要指定列名及被插入的值:INSERT INTO table_name (column1,column2,column3,...)VALUES (value1,value2,value3,...);
SQL UPDATE 语句
UPDATE 语句用于更新表中已存在的记录。
UPDATE table_nameSET column1=value1,column2=value2,...WHERE some_column=some_value;-- 更新XXX表-- 设置什么列什么值-- 确定哪一条件(那一列)
SQL DELETE 语句
DELETE 语句用于删除表中的记录。
DELETE FROM table_nameWHERE some_column=some_value;
SQL 高级教程
SQL SELECT TOP 子句
SELECT TOP 子句用于规定要返回的记录的数目。
SELECT TOP 子句对于拥有数千条记录的大型表来说,是非常有用的。
select TOP 10 * FROM SellerCube..ProfitReportBill where SendDate>='2022-10-1 00:00:00' and SendDate<'2022-10-02 00:00:00'AND warehouseTypeStr='国内仓'-- 得加*号,表示拉取所有字段,不然那就得制定字段-- 注意:并非所有的数据库系统都支持 SELECT TOP 语句。-- MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
SQL LIKE 操作符
LIKE 操作符用于在 WHERE 子句中搜索列中的指定模式。
SELECT * FROM WebsitesWHERE name LIKE '%k
SELECT * FROM WebsitesWHERE name NOT LIKE '%oo%';
SQL 通配符
SQL 通配符
在 SQL 中,通配符与 SQL LIKE 操作符一起使用。SQL 通配符用于搜索表中的数据。
在 SQL 中,可使用以下通配符:
| 通配符 | 描述 |
|---|---|
| % | 替代 0 个或多个字符 |
| _ | 替代一个字符 |
| [charlist] | 字符列中的任何单一字符 |
| [^charlist] 或 [!charlist] | 不在字 |
select * FROM SellerCube..ProfitReportBill where SendDate>='2022-10-1 00:00:00' and SendDate<'2022-10-02 00:00:00'AND warehouseTypeStr LIKE'国%'--%在前在后替代的位置不同
下面的 SQL 语句选取 name 以一个任意字符开始,然后是 “oogle” 的所有客户:
SELECT * FROM WebsitesWHERE name LIKE '_oogle';
MySQL 中使用 REGEXP 或 NOT REGEXP 运算符 (或 RLIKE 和 NOT RLIKE) 来操作正则表达式。
下面的 SQL 语句选取 name 以 “G”、”F” 或 “s” 开始的所有网站:
SELECT * FROM WebsitesWHERE name REGEXP '^[A-H]';
SQL IN 操作符
IN 操作符允许您在 WHERE 子句中规定多个值。
SELECT column_name(s)FROM table_nameWHERE column_name IN (value1,value2,...);
SQL BETWEEN 操作符
BETWEEN 操作符用于选取介于两个值之间的数据范围内的值。
SELECT * FROM WebsitesWHERE alexa BETWEEN 1 AND 20;
SQL 别名
通过使用 SQL,可以为表名称或列名称指定别名。
基本上,创建别名是为了让列名称的可读性更强。
--- 表别名SELECT w.name, w.url, a.count, a.dateFROM Websites AS w, access_log AS aWHERE a.site_id=w.id and w.name="菜鸟教程";--列别名SELECT name AS n, country AS cFROM Websites;SELECT w.platformName, w.country, a.*FROM SellerCube..ProfitReportBillExtend AS w, SellerCube..ProfitReportBill AS aWHERE a.billid=w.billid and a.billid='A00031220420004F';
SQL JOIN
在我们继续讲解实例之前,我们先列出您可以使用的不同的 SQL JOIN 类型:
- INNER JOIN:如果表中有至少一个匹配,则返回行()
- LEFT JOIN:即使右表中没有匹配,也从左表返回所有的行(join前面是哪个方向,就代表以哪边的数据为基准,也就是全获取过来)
- RIGHT JOIN:即使左表中没有匹配,也从右表返回所有的行 (join前面是哪个方向,就代表以哪边的数据为基准,也就是全获取过来)
- FULL JOIN:只要其中一个表中存在匹配,则返回行
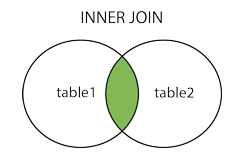
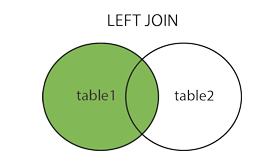
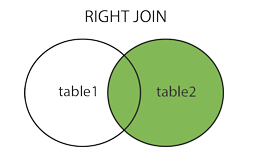
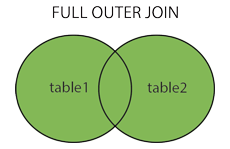
--"Websites" 表中的 "id" 列指向 "access_log" 表中的字段 "site_id"。--上面这两个表是通过 "site_id" 列联系起来的。SELECT Websites.id, Websites.name, access_log.count, access_log.dateFROM WebsitesINNER JOIN access_logON Websites.id=access_log.site_id;
SQL UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table1UNIONSELECT column_name(s) FROM table2;
SQL 通用数据类型
数据库表中的每个列都要求有名称和数据类型。Each column in a database table is required to have a name and a data type.
SQL 开发人员必须在创建 SQL 表时决定表中的每个列将要存储的数据的类型。数据类型是一个标签,是便于 SQL 了解每个列期望存储什么类型的数据的指南,它也标识了 SQL 如何与存储的数据进行交互。
下面的表格列出了 SQL 中通用的数据类型:
| 数据类型 | 描述 |
|---|---|
| CHARACTER(n) | 字符/字符串。固定长度 n。 |
| VARCHAR(n) 或 CHARACTER VARYING(n) |
字符/字符串。可变长度。最大长度 n。 |
| BINARY(n) | 二进制串。固定长度 n。 |
| BOOLEAN | 存储 TRUE 或 FALSE 值 |
| VARBINARY(n) 或 BINARY VARYING(n) |
二进制串。可变长度。最大长度 n。 |
| INTEGER(p) | 整数值(没有小数点)。精度 p。 |
| SMALLINT | 整数值(没有小数点)。精度 5。 |
| INTEGER | 整数值(没有小数点)。精度 10。 |
| BIGINT | 整数值(没有小数点)。精度 19。 |
| DECIMAL(p,s) | 精确数值,精度 p,小数点后位数 s。例如:decimal(5,2) 是一个小数点前有 3 位数,小数点后有 2 位数的数字。 |
| NUMERIC(p,s) | 精确数值,精度 p,小数点后位数 s。(与 DECIMAL 相同) |
| FLOAT(p) | 近似数值,尾数精度 p。一个采用以 10 为基数的指数计数法的浮点数。该类型的 size 参数由一个指定最小精度的单一数字组成。 |
| REAL | 近似数值,尾数精度 7。 |
| FLOAT | 近似数值,尾数精度 16。 |
| DOUBLE PRECISION | 近似数值,尾数精度 16。 |
| DATE | 存储年、月、日的值。 |
| TIME | 存储小时、分、秒的值。 |
| TIMESTAMP | 存储年、月、日、小时、分、秒的值。 |
| INTERVAL | 由一些整数字段组成,代表一段时间,取决于区间的类型。 |
| ARRAY | 元素的固定长度的有序集合 |
| MULTISET | 元素的可变长度的无序集合 |
| XML | 存储 XML 数据 |
SQL 函数
- AVG() - 返回平均值
- COUNT() - 返回行数
- FIRST() - 返回第一个记录的值
- LAST() - 返回最后一个记录的值
- MAX() - 返回最大值
- MIN() - 返回最小值
- SUM() - 返回总和
SQL SUM() 函数
SUM() 函数返回数值列的总数。 ```plsql SELECT SUM(column_name) FROM table_name; mysql> SELECT * FROM access_log; +——-+————-+———-+——————+ | aid | site_id | count | date | +——-+————-+———-+——————+ | 1 | 1 | 45 | 2016-05-10 | | 2 | 3 | 100 | 2016-05-13 | | 3 | 1 | 230 | 2016-05-14 | | 4 | 2 | 10 | 2016-05-14 | | 5 | 5 | 205 | 2016-05-14 | | 6 | 4 | 13 | 2016-05-15 | | 7 | 3 | 220 | 2016-05-15 | | 8 | 5 | 545 | 2016-05-16 | | 9 | 3 | 201 | 2016-05-17 | +——-+————-+———-+——————+ 9 rows in set (0.00 sec)
SELECT COUNT(*) FROM access_log; —计数
select
sum(CAST (OrderTotal as Decimal(10,2))) as ‘订单金额’,
sum(storagePrice) as ‘仓储费’,
sum(extendPriceField1) as ‘集成供应链成本’,
sum(operatingCosts) as ‘集团运营成本’ ,
sum(storagePrice)/sum(CAST (OrderTotal as Decimal(10,2))) as ‘仓储费/订单金额’,
sum(operatingCosts)/sum(CAST (OrderTotal as Decimal(10,2))) as ‘集团运营成本/订单金额’,
sum(extendPriceField1)/sum(CAST (OrderTotal as Decimal(10,2))) as ‘集成供应链成本/订单金额’
FROM SellerCube..ProfitReportBill
where SendDate>=’2022-10-1 00:00:00’ and SendDate<’2022-10-2 00:00:00’
AND warehouseTypeStr=’国内仓’
<a name="UgE3e"></a>#### SQL AVG() 函数AVG() 函数返回数值列的平均值。```plsqlSELECT AVG(column_name) FROM table_name
SQL COUNT() 函数
COUNT() 函数返回匹配指定条件的行数。
SELECT count(column_name) FROM table_nameSELECT COUNT(DISTINCT site_id) AS nums FROM access_log;--不同siteid
SQL MAX() 函数
MAX() 函数返回指定列的最大值。
SELECT MAX(column_name) FROM table_name;
SQL MIN() 函数
MAX() 函数返回指定列的最小值。
SELECT MIN(column_name) FROM table_name;
SQL GROUP BY 语句
GROUP BY 语句用于结合聚合函数,根据一个或多个列对结果集进行分组。
SELECT column_name, aggregate_function(column_name)FROM table_nameWHERE column_name operator valueGROUP BY column_name;
随堂小考
selectsp.processcenter_id as "处理中心ID",casesp.enablewhen 0 then '不可用'when 1 then '可用'end as "是否可用",sp.name as "中文名称",sp.en_name as "英文名称",sp.abbr_name as "中文简称",pr.cn_name as "大区",pri1.cn_name as "区域",pri2.cn_name as "库销比区域",sp.country_id,scs.cn_name as "国家",scs.ct_name,scs.en_shorting as "国家简码",CASEsp.operation_modewhen 0 THEN'自营'when 1 THEN'三方运营'WHEN 2 THEN'平台运营'WHEN 3 THEN'代销运营'END as "运营模式",CASEsp.wms_typewhen 0 then'EWMS'WHEN 1 THEN'三方系统'when 2 then'TWMS'WHEN 3 THEN'WMS'end AS "系统类型",CASEspe.is_openwhen 0 then'非社会化'when 1 then'社会化'end as "是否社会化",(select reserve from wsp.sys_dict_details where dict_type ='处理中心平台类型' and dict_key = cast(spe.platform as varchar)) as "处理中心运营方",CASEsp.is_chinawhen 0 then '海外仓'when 1 then '国内仓'end as "是否国内仓"from wsp.sys_processcenter spleft join wsp.pm_processcenter_management ppm on sp.processcenter_id=ppm.processcenter_idleft join wsp.pm_region pr on ppm.region_id=pr.idleft join wsp.pm_region_item pri1 on ppm.region_item_id=pri1.idleft join wsp.pm_region_item pri2 on ppm.ks_region_item_id=pri2.idleft join wsp.sys_countrys scs on scs.id=sp.country_idleft join wsp.sys_processcenter_expand spe on spe.sys_processcenter_id=sp.idwhere ppm.is_deleted=0
Matebase语法
selectsum(CAST (OrderTotal as Decimal(10,2))) as "订单金额",sum(storagePrice) as "仓储费",sum(extendPriceField1) as "集成供应链成本",sum(operatingCosts) as "集团运营成本" ,sum(storagePrice)/sum(CAST (OrderTotal as Decimal(10,2))) as "仓储费/订单金额",sum(operatingCosts)/sum(CAST (OrderTotal as Decimal(10,2))) as "集团运营成本/订单金额",sum(extendPriceField1)/sum(CAST (OrderTotal as Decimal(10,2))) as "集成供应链成本/订单金额"FROM SellerCube.ProfitReportBillwhere SendDate>='2022-10-1' and SendDate<'2022-10-22'AND warehouseTypeStr='国内仓'

若有收获,就点个赞吧
0 人点赞
