先说一下这篇文章主要讲什么:
- 关于二进制安全的一点点想法
- 学习汇编的一些前置知识
如何去读汇编代码
关于二进制安全的一点点想法
个人感觉学逆向主要包括四类人1. 安全研发人员 安全研发人员通常与产品直接挂钩,作为一款安全产品要成功抵御攻击,就不得不深入地了解攻击者是如何发起攻击的。而攻击者为什么能够这样发起攻击,则需要去了解系统底层的实现,所以说一个优秀的安全研发工程师,一定是一个优秀的逆向工程师。
2. 安全分析人员
与安全分析人员对应的更多是威胁情报这一块。
初级的分析人员主要是对拿到的恶意样本进行一个分析,分析攻击者的思路,分析攻击的流程以及提取样本中iocs和规则,而这些信息又可以输出到产品中,使得产品愈发完善。
高级的分析人员可能重心更多的会放在关联和溯源上。拿到一个样本可以很快的与已有的攻击事件或者已有的组织关联起来,能够很快的找到同源到样本 提取出共有特征 批量的拦截该类攻击。当然 各位前辈们所做的工作肯定远远不止于此,我在尽量了解,也在努力学习。
还有一些大神级别的….
3. 安全研究人员
有时候安全研究人员也会担任起一些研发的工作,但可能更多的是专注于漏洞方面。简单来说,挖洞的都是大佬。红队研究人员
以前经常看到有人问学二进制能做什么,就会听到有人说 分析病毒或者挖洞。听起来两个都是困难且枯燥的内容。但是感觉 在红蓝对抗中,要成为一个出色的红队人员,逆向的技能是必须掌握的,至于为什么 可能我一篇文章也讲不清楚,大家可以参照极光无限之前发的一篇文章。
由于学习方向的不同,那么后面点的技能栈可能或多或少会有一些出入。但最开始应该都是从汇编入手。其实网上的汇编教程很多 汇编的资料也很多 但由于这些资料都是大佬整理的,所以难免会让很多初学者很懵 ,饱汉不知饿汉饥,大佬和自己刚开始学习的时候,思维也已经发生了天翻地覆的改变,所以很多时候大佬的文章比较适合有一定水平和经验的人看。
我刚开始学习的时候也很痛苦,照着书上 先学底层原理 然后学寄存器 等到真正讲汇编的时候热情都消散的差不多了。所以后来我换了个思路 直接写c代码然后去参照着读汇编。在这个过程中就遇到了很多问题 然后又去查资料去想办法解决了很多问题 渐渐的发现很多以前理解起来困难的东西,在解决问题的过程中就能理解了。当然我并不是要鼓励大家成为半壶水响叮当的人,人的成长是有个过渡期的,现在看着不懂的东西 随着知识方面的积累 可能过一段时间就能有更好的理解。底层原理 编译原理这些东西 并不是说初学者一定要掌握才能往后走,但是在安全这条路上,或早或晚,这些东西是必须掌握的。
学习汇编的一些前置知识
所以还是回来谈谈汇编。虽然说现在主流已经是x64的汇编了,x86可能会慢慢的退出历史的大舞台(虽然还有很长一段时间),但从学习的角度来看,x86更让人好理解,也更适合学习一些。等到积累到一定程度了,再学x64也就是水到渠成的事情。
虽然说我在尽量避免以太过复杂的方式介绍,但有一些基础的概念还是必须在学习汇编之前就要掌握。
寄存器相关
什么是寄存器
简单来说,寄存器是CPU内部用于存放数据的小型存储区域,寄存器是内存与CPU能够交互的一个关键。
常用的寄存器有哪些
以x86为例,常见的有8个通用寄存器。
EAX eax是累加器,在做加法和乘法运算的时候,eax是默认寄存器 EBX ebx是基地址寄存器,通常被用于寻址 EXC ecx是计数器,通常用于循环计数 EDX edx通常用于存放除法运算产生的余数 ESI esi是源寄存器,通常在字符串操作中使用
EDI edi与esi对应,edi表示目标寄存器 EBP ebp是基址指针,通常用于指向栈底 ESP esp才是专用的堆栈指针,与ebp对应,通常指向栈顶。
还有一些特殊的寄存器,刚开始的时候不用掌握那么多,后面遇到再去学习就行。
寄存器可以怎样用
eax ebx exc edx 这四个寄存器,除了本身自带的一些功能,他们还常常被用于一些运算。开发人员可以直接使用一些汇编指令去操作这几个寄存器实现一些简单的功能,需要注意的是,eax寄存器还有一个存放函数返回值的功能。在大多数情况下,一个函数调用完成之后,返回值都会保存在EAX寄存器中。
后面的esi和edi通常会配合数据段寄存器DS来使用,通常情况下,我们不会动esi和edi的值。
esp和ebp分别用于指向栈顶和栈底,是两个特别关键的寄存器。esp和ebp涉及到操作系统中一个最基础的概念”堆栈”。
说是堆栈,其实是指栈,当我们描述堆的时候都会直接说堆。
栈的原理其实很简单,从C语言的角度来看,栈是一种数据结构,先入后出。从计算机系统来看,栈是一个具有先入后出属性的动态内存区域。程序可以将数据压入栈中,也可以将数据从栈顶弹出。可以说我们所见到的函数调用,基本上都是跟栈挂钩的。
在一个函数开头,经常可以看到如下的语句来开辟新的堆栈:
push ebpmov ebp,espsub esp 40h
这里首先保存当前的ebp,然后通过mov将ebp和esp指向同一个位置,再通过sub指令更改esp的指向,这样就为当前函数开辟出了一个新的栈空间。
sub esp 40h里面的40h,是编译器预留给当前函数存放临时变量的空间。
然后在函数结尾,通常会使用
mov esp,ebppop ebpret
作为返回,退出当前函数。
在汇编代码中,ebp常见的有两种使用方式,分别是:
ebp + xx
ebp - xx
根据windows内存空间的生长方向我们可以知道,ebp + xx 是取参数的值,ebp -xx 是取局部变量的值。
有时候也会使用esp的加减来定位变量,但是这种情况比较少见。
举个🌰
我们在对一个函数调用的时候,就会将一些关键信息入栈。
最开始入栈的是函数的参数,在C语言中,函数的参数入栈顺序是自右向左依次入栈。
最后入栈的是函数的返回地址,这个地址很重要,关系着函数执行完成之后该回到哪里继续执行。
比如我有个函数fun1(int a, char b, int c )
我在main函数中调用了fun1函数,
那么参数入栈的时候
最先入栈的是变量c
其次入栈的是变量b
接着入栈的是变量a
最后入栈的是main函数调用这个fun1函数之后的地址。
汇编指令相关
先介绍几个常见的指令:
mov
add
sub
push
pop
call
rete
最常见的汇编指令是mov,mov指令有两个操作数,格式如下:
mov 操作数1,操作数2
mov指令的功能是将操作数2的内容移动到操作数1,这里的操作数1必须是寄存器,操作数2可以是地址、常量、寄存器。例如:
mov eax,31 是把0x31赋值给eaxmov eax,ebx 是把ebx的值赋值给eax
那么可不可以用 mov 0x00401000,31 来表示将0x31放入到0x00401000这个地址呢,答案是不行的。
因为如果第一个操作数变成了地址,编译器并不能保证这个地址一定存在,而数据是从内存中读入到CPU中的,要让CPU能够正常操作,所以其中一个操作数必须为寄存器。
add和sub是一组运算指令,分别对应加减运算。
这两个指令和mov类似,使用方法都是
add 操作数1,操作数2sub 操作数1,操作数2功能是将操作数1和操作数2进行add或者sub操作,然后结果保存在操作数1的位置所以很明显,操作数1也必须是一个寄存器。比如
add eax,0x10是将eax中的值和0x10相加,然后结果保存在eax中add eax,ebx 是将eax中的值和exb相加然后保存在eax中。sub指令也是同理。比如我要利用eax进行运算可以这样写:
mov eax,0x10add eax,0xAmov ebx,0x05add eax,ebx
还有一组常用的汇编指令是push和pop
和之前的汇编指令不同,push和pop只有一个操作数。
比如
push eax
push ebx
push 0x10
pop edi
pop ebx
pop bex
……
push指令的功能是将跟在push指令后的操作数入栈。
当一条push指令执行之后,ebp的值不变,esp的值会减去入栈类型的长度。
比如假设当前的栈如下:
栈底ebp指向的地址是0x0012FF80
栈顶esp指向的地址是0x0012FF70
现在执行push 0x10,那么堆栈的变化如下:
与之对应的,pop指令执行之后,ebp还是不变,esp的值加上pop出的类型的长度。
如何去读汇编代码
就不自己写汇编代码然后读了,我们直接看编译器为我们做了什么。
先写一段简单的c语言代码:
这个代码的功能很简单,编译之后直接在IDA中看一下Main函数的反汇编代码: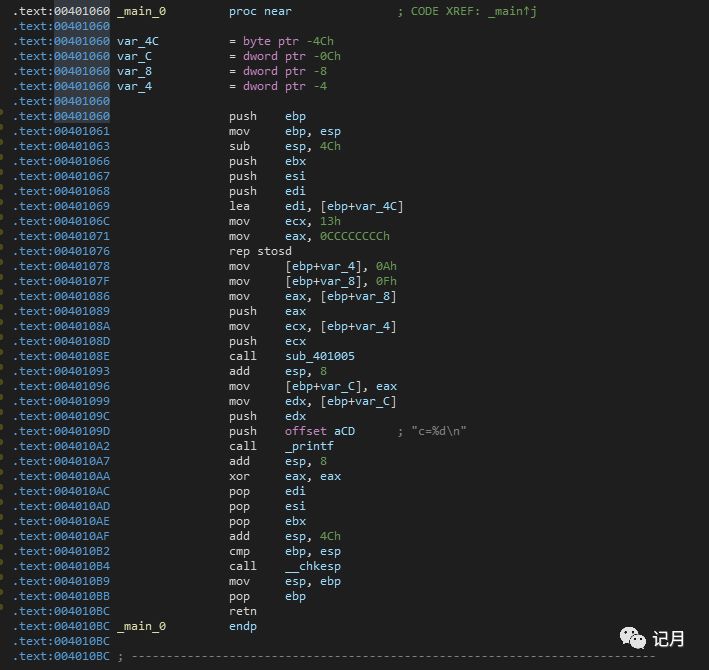
和之前分析的符合,程序最开始的地方还是通过三行代码开辟当前函数的栈空间。
push ebp mov ebp,esp这里push ebp,然后mov ebp,esp就会使得ebp和esp指向同一个地方。
比如在这个代码中,push ebp之前,函数的堆栈如下: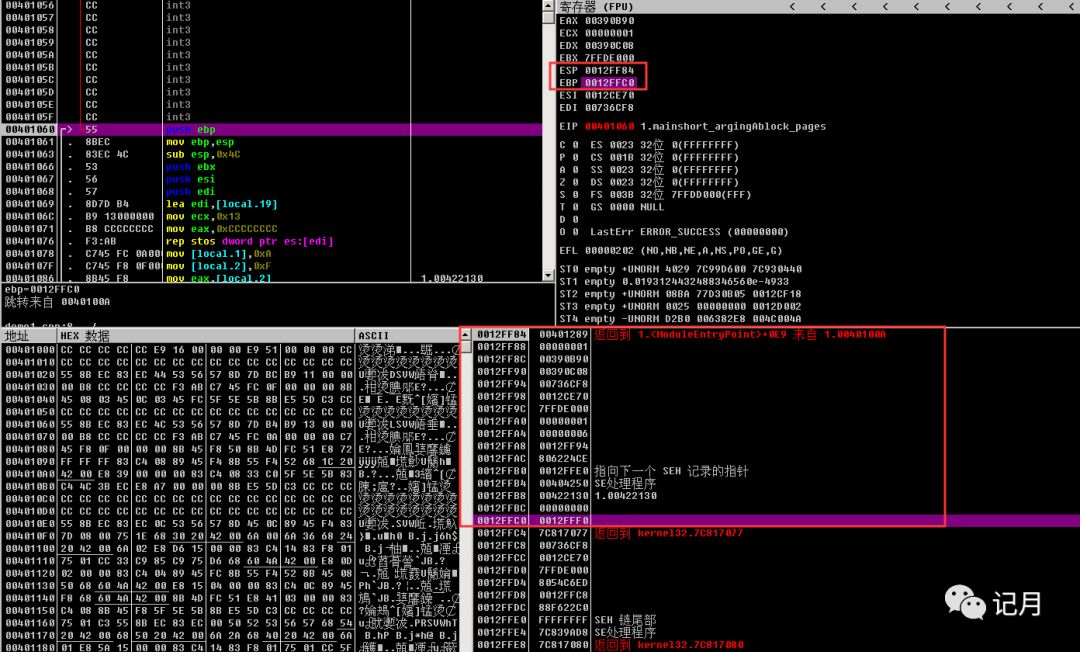
push之后,由于ebp是一个32位的寄存器,占四个字节,所以会让esp的值-4,栈空间+4。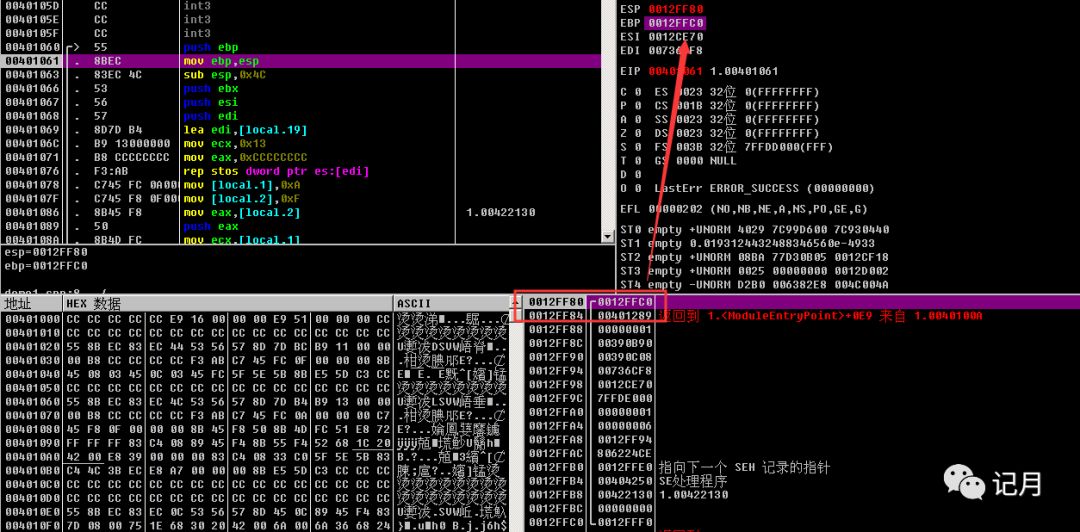
然后现在mov ebp,esp,两个寄存器就指向了同一个地址,现在堆栈就清空了。
下面的一条语句 sub esp,4Ch是开辟一个0x4C大小的的栈空间。
接下来的几行语句是一些初始化的操作,暂时可以先不用管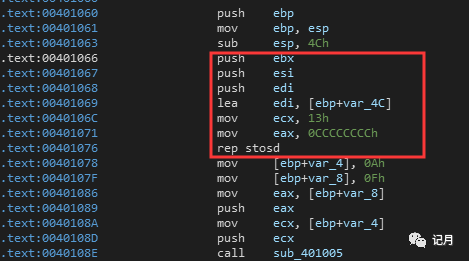
再往下走,是通过mov的赋值语句
这里给ebp + var_4 的地址赋值了0x0A给ebp+var_8的地址赋值了0x0F
刚好对应了我们c语言中的
int a =10;int b = 15;而var_4 在IDA窗口中我们一开始就看到,是 -4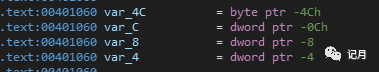 所以mov[ebp + var_4],0Ah实际是mov[ebp - 4] ,0Ah
所以mov[ebp + var_4],0Ah实际是mov[ebp - 4] ,0Ah
我们在调试器中可以看到写法是mov[local.1],0xA双击可以看到实际上也是mov dword ptr ss:[ebp-0x4],0xA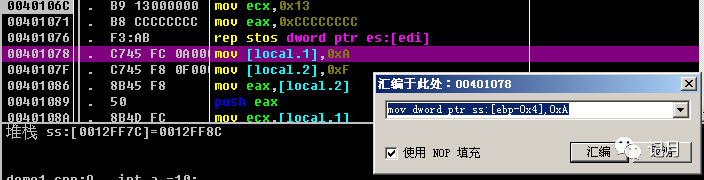
运行之后可以看到的确,在ebp-4 和ebp -8的地方已经被成功赋值。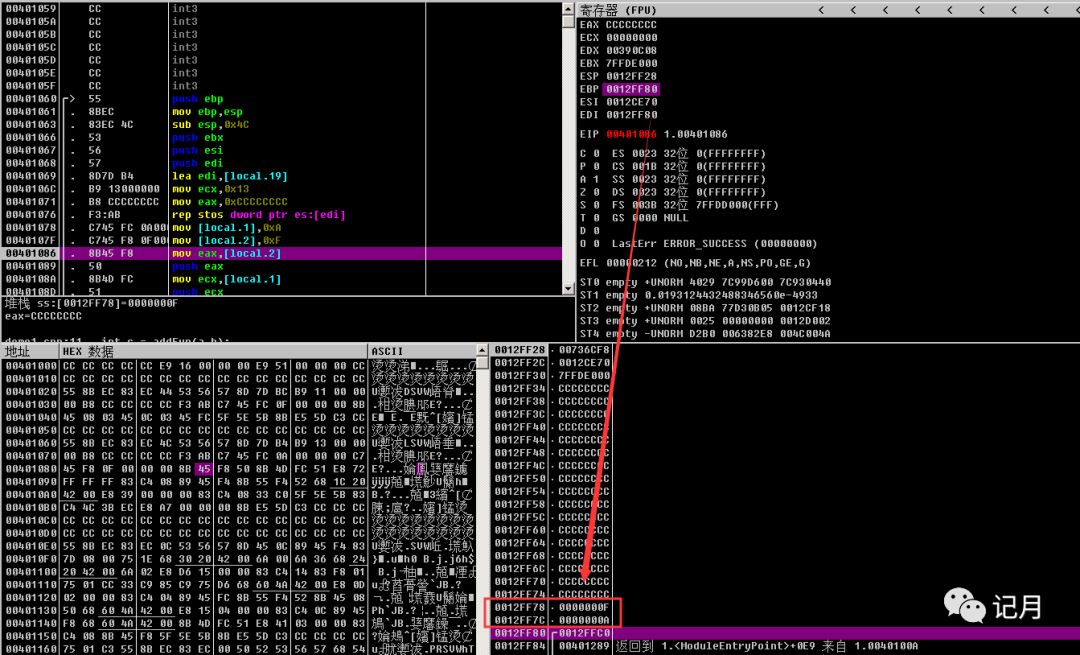
接着通过
mov eax, [ebp+var_8]push eax两条指令将参数2入栈mov ecx, [ebp+var_4]push ecx两条指令将参数1入栈这个时候这两个值就会放在栈顶,也就是esp所指向的位置: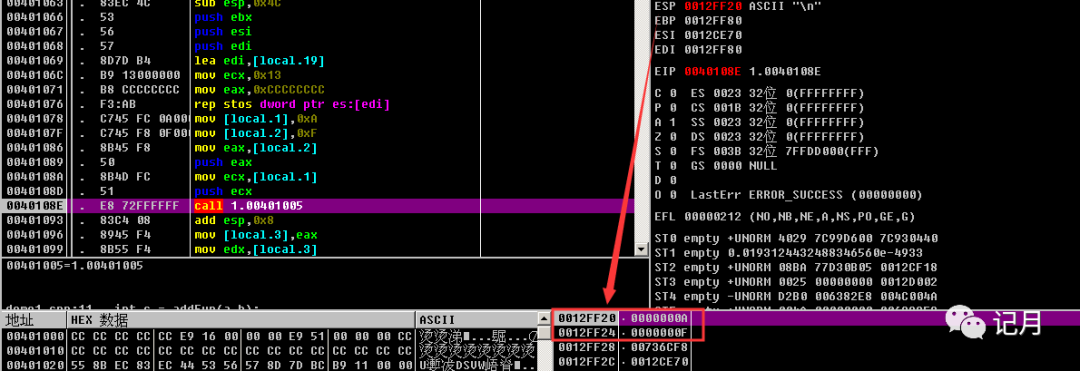
参数入栈之后会通过call 指令调用函数,在大多数情况下,我们都可以把call 指令当成函数调用指令。F7单步进入到函数,可以看到自动入栈了一个新的值,该值就是函数的返回地址,而这个返回地址,通常就是执行call指令的下一行。这里是00401093,回到上面的图可以看到,call指令之后的第一条指令,的确是在00401093。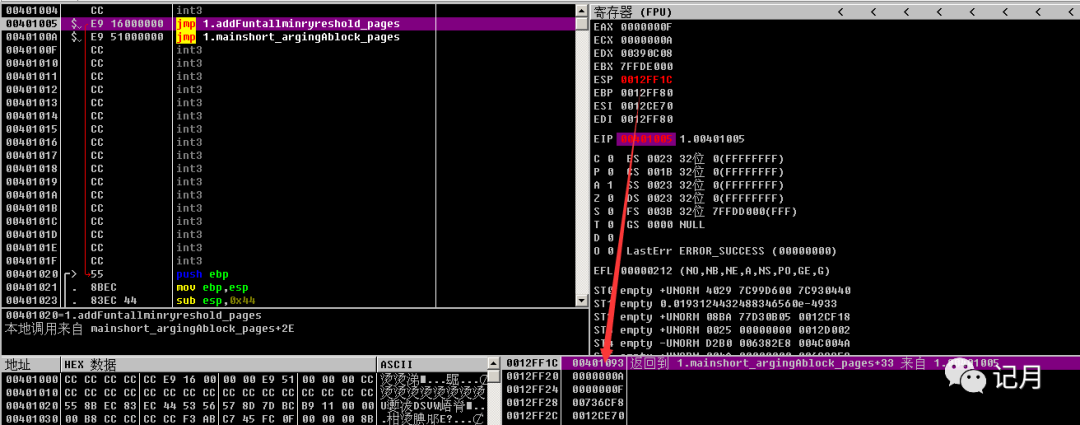
F7跟过来之后,现在程序就运行到addFun函数了,IDA中addFun函数反汇编如下: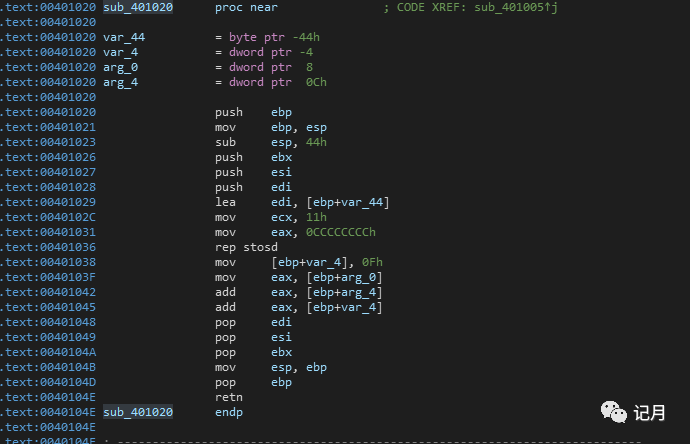
有了之前的分析经验,我们现在可以直接读这段汇编代码了
首先还是平衡当前的堆栈给当前函数开辟了一个0x44大小的栈空间
然后一段初始化
然后mov [ebp+var_4], 0Fh 给当前ebp偏移4的地址赋值为0x0F,也就是我们在C语言中定义的int temp = 15; 所以addFun函数中的局部变量temp存储在了ebp-0x4的地方
继续往下看mov eax, [ebp+arg_0]将ebp + arg_0的值赋值给eax,arg_0是8,所以这条语句是:mov eax, [ebp+0x8]在调试器中可以看到ebp +0x8 就是A这里ebp = 0012FF18 加上0x8 就是0012FF20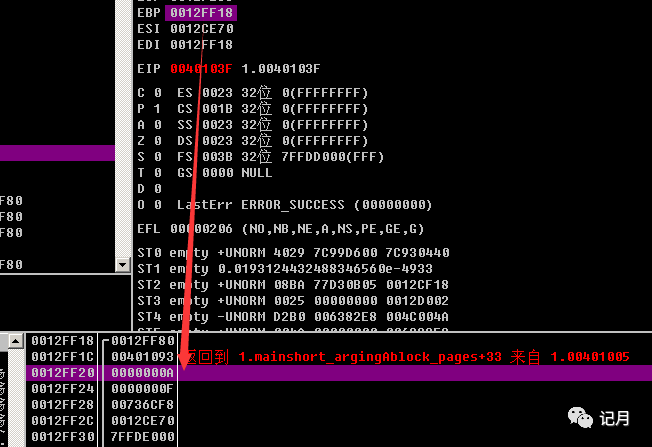
add eax, [ebp+arg_4] 这里arg_4等于0Ch所以这里是add eax, [ebp+0x0c] 直接看上面那个图就知道ebp+0x0c处是0012FF24
刚才已经通过mov eax, [ebp+arg_0] 将参数1赋值给了eax
现在又通过add eax, [ebp+0x0c] 就可以实现参数2与参数1相加,结果保存在eax。
再往后是add eax, [ebp+var_4]指令,var_4 = -4所以这里是add eax, [ebp-0x4]我们上面已经分析过,ebp-0x4的地方存储的是局部变量temp
所以这里是将参数1和参数2的结果再加上temp,结果保存在eax寄存器。至此,这个简单的代码功能部分就执行完成了,接下来就是事后处理。
先把栈里面的数据pop出去取到最后的返回地址,通过retn返回回去,这里是返回到00401093
00401093就回到了main函数的地址部分,后面的代码就和上面分析的一样,push参数,call调用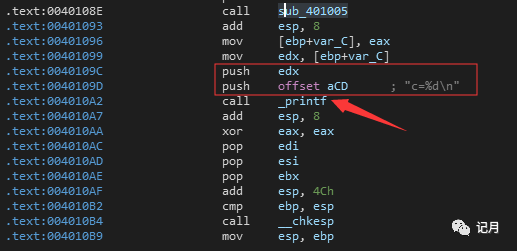

若有收获,就点个赞吧
0 人点赞
