绪论
编译:把高级语言翻译成汇编语言或者直接翻译成机器语言的过程就叫编译

编译器在语言处理系统中的位置
在预处理器和汇编器之间。
预处理器:源程序分布在很多个文件里。预处理器就是把他们组合起来。
可重定位:把翻译后问程序加载到内存里,那么加到内存的哪一块都可以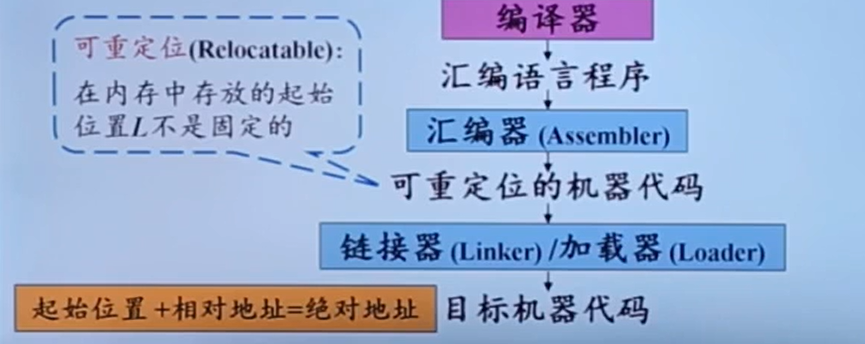
多个重定位的机器代码放内存之后,链接器负责把他们连成一个整体
外部内存地址:一个文件中的代码可能会引用另一个文件中的数据对象或过程。这些数据对象或过程就被称为外部内存地址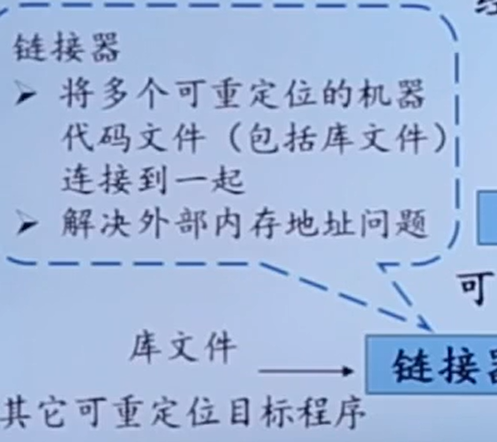

编译系统的结构
要解决什么问题?
把高级语言翻译成汇编/机器语言。
怎么解决?
分析(词法、语法、语义分析。产生分析后的中间代码)、把中间代码翻译成机器码。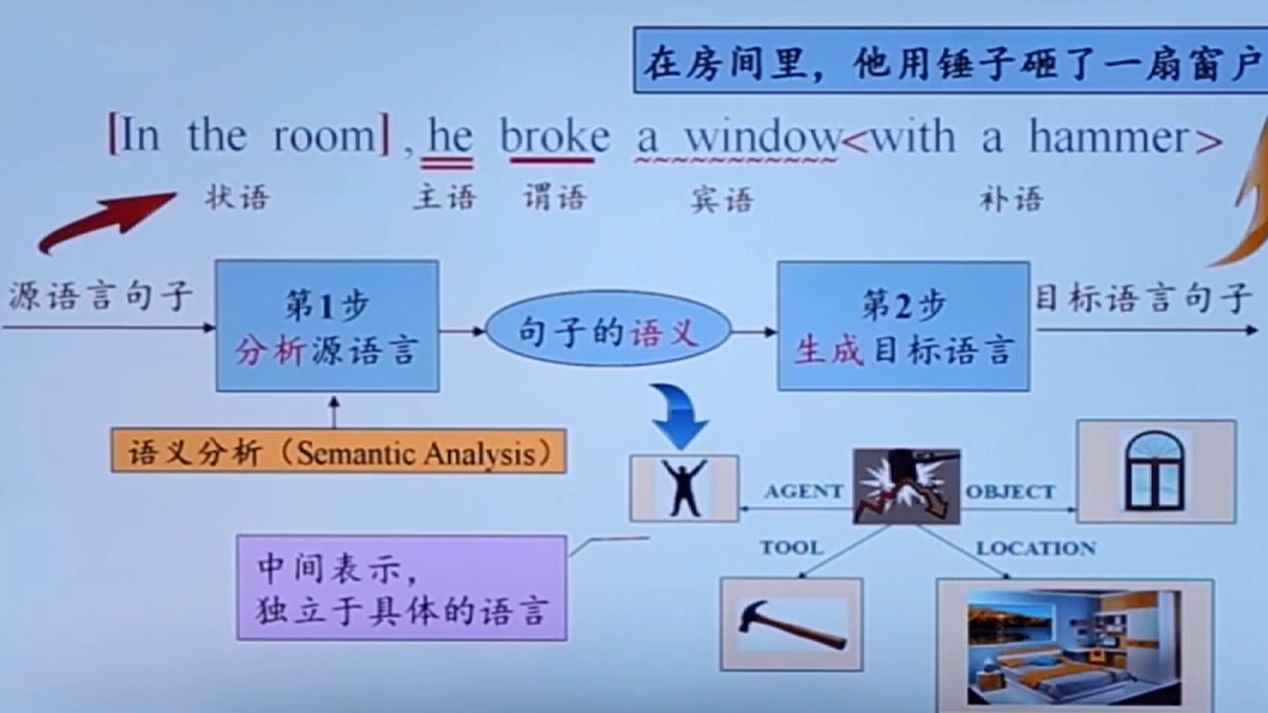
中间表示:
中间表示很重要,起到桥梁的作用
先分析词性,然后分析短语、最后分析语义
最终产生的结果就是 中间表示

词法分析:
要解决什么问题?
识别出单词,确定单词类型,把单词转成 词法单元(token)形式
怎么解决?
从左到右扫描。获取单词信息,具体怎么把这些信息转成token的过程,不清楚。
种别码
作用:用来标识各个单词的。可以看成是单词的类型。就像英语里单词的词性一样。
实例:变量名,数组名,记录名,这些都是标识符。标识符就是种别码,叫做IDN
还有没有其他解决办法?
种别码是用来组成token的,但是token是用来干嘛的?不知道。
是啥?token尖括号里左边的东西。
实例见下。
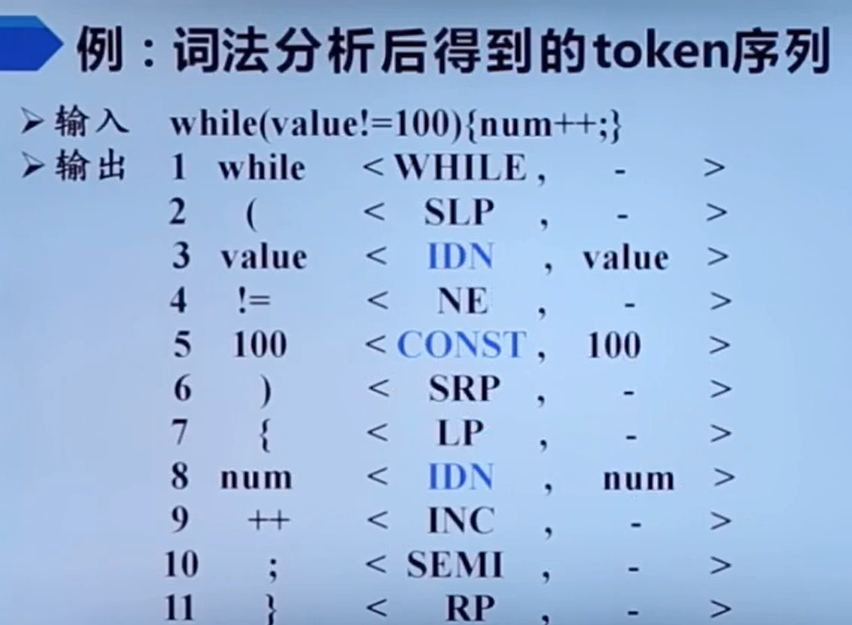
IDN(标识符)是多词一码,所以属性值有值。常量是一型一码,所以也有属性值。一词一码的没有
语法分析
作用是啥?
从token序列中找到几个token组成短语(比如变量声明语句、赋值语句)。并且这个过程形成的树叫做语法分析树。
怎么解决的?不知。
是啥?
构造短语的。
实例见下。


D:declaration,表示声明的语句
T:type,表示类型
IDS:identify sequence,表示标识符序列
语义分析
作用是啥?
高级语言程序中的语句一般可以分成两部分:声明语句、可执行语句
在声明语句中,会对声明一些对象或过程,并且给他们起个名字,这名字就是标识符。
对声明语句来说,语义分析的主要任务就是
任务一:收集标识符信息。
任务二:进行语义检查
怎么解决的?
收集标识符信息的时候,是用了一种数据结构:符号表。
还有一个字符串表,用来存放标识符的名字。
对符号表:一个记录是就是一个标识符。一个字段就是标识符的一个属性。
其中符号表的name字段分两部分:第一部分存放标识符在字符串表里的其实位置,第二部分是标识符长度
他是啥?
是编译的第3阶段。
标识符信息如下(具体自己查书):
种属:简单变量、复合变量(数组、记录、…)、过程、…
类型:整形、实型、字符型、布尔型、指针型

符号表表示如下:

中间代码生成
是啥?
前面通过编译器前端的各种操作,最终是为了生成中间代码。那么中间代码到底长什么样子?他其实有多种表示形式。(类似于收小麦。 前端就是不管用收割机还是镰刀,反正要实现“收”这个功能。 中间形式就是收完后的小麦模样,可以是带皮、脱皮、甚至粉状的。 后端就是把小麦做成馒头(这里馒头就是目标代码))
中间代码形式有多种:可以是三地址码、也可以是语法结构树/语法树。所以可以说中间代码就是三地址码,或者语法结构树/语法树

x:运算结果的存放地址。 y、z:两个运算分量的地址。 op:一个二元运算符
源程序中的名字,就是标识符。每个标识符对应的地址都在符号表里。
语法结构树/语法树 和 语法分析树不是一回事
if x relop y goto n:如果x和y满足 关系relop,就跳转到n
call p,n p是过程的名字,n是变量个数
三地址指令的表示有四种:四元式、三元式、间接三元式

(=[],y,i,x):表示=右边的是数组元素,y是数组基地址,i是偏移地址,x是要赋值的变量。
三地址指令序列唯一确定了运算完成的顺序
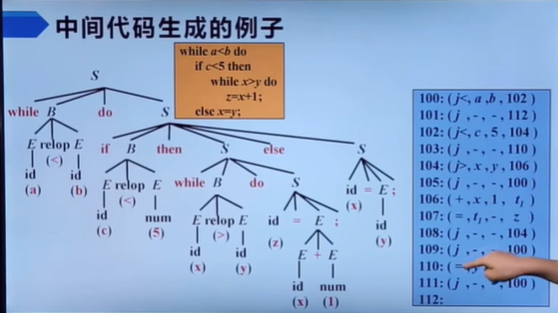
目标代码生成
作用是啥:给我输入中间代码,给你生成目标代码
怎么解决的?
一个重要的任务就是为程序中使用的变量合理分配寄存器
是啥?是一个代码编成的程序。给我输入,给你输出。


若有收获,就点个赞吧
0 人点赞
