对不同的手机号码分成不同文件
接着上面的例子
默认的分区规则
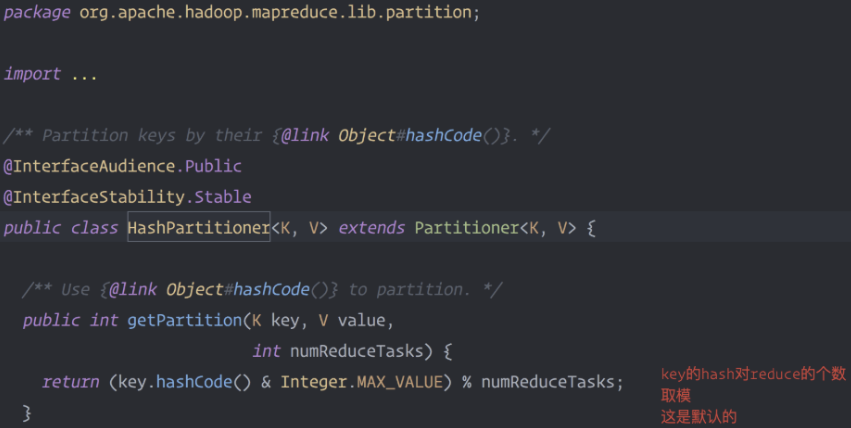
分区类
package com.folwsum;import org.apache.hadoop.mapreduce.Partitioner;import java.util.HashMap;public class ProvivcePartitioner extends Partitioner {private static HashMap<String, Integer> provinceMap = new HashMap<String, Integer>();static{//我们这边就提前设置手机号码对应的分区provinceMap.put("135", 0);provinceMap.put("136", 1);provinceMap.put("137", 2);provinceMap.put("138", 3);provinceMap.put("139", 4);}@Overridepublic int getPartition(Object o, Object o2, int numPartitions) {//根据手机的前3位,进行取他的值,就是上面定义的Integer code = provinceMap.get(o.toString().substring(0, 3));if(code != null){return code;}//没有取到就分到5去return 5;}}
任务类
主要是main方法里面的
package com.folwsum;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import org.apache.hadoop.util.StringUtils;import java.io.IOException;public class FlowSumProvince {public static class ProvinceFlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean> {Text k = new Text();FlowBean v = new FlowBean();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//将读取到的每一行数据进行字段的切分String line = value.toString();String[] fields = StringUtils.split(line, ' ');//抽取我们业务所需要的字段String phoneNum = fields[1];long upFlow = Long.parseLong(fields[fields.length - 3]);long downFlow = Long.parseLong(fields[fields.length - 2]);k.set(phoneNum);v.set(upFlow, downFlow);context.write(k, v);}}public static class ProvinceFlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean> {@Overrideprotected void reduce(Text key, Iterable<FlowBean> values, Context context) throws IOException, InterruptedException {long upFlowCount = 0;long downFlowCount = 0;for(FlowBean bean : values){upFlowCount += bean.getUpFlow();downFlowCount += bean.getDownFlow();}FlowBean sumbean = new FlowBean();sumbean.set(upFlowCount, downFlowCount);context.write(key, sumbean);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(FlowSumProvince.class);//告诉程序,我们的程序所用的mapper类和reducer类是什么job.setMapperClass(ProvinceFlowSumMapper.class);job.setReducerClass(ProvinceFlowSumReducer.class);//告诉框架,我们程序输出的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(FlowBean.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(FlowBean.class);//设置我们的shuffer的分区组件使用我们自定义的组件job.setPartitionerClass(ProvivcePartitioner.class);//这里设置我们的reduce task个数 默认是一个partition分区对应一个reduce task 输出文件也是一对一//如果我们的Reduce task个数 < partition分区数 就会报错Illegal partition//如果我们的Reduce task个数 > partition分区数 不会报错,会有空文件产生//如果我们的Reduce task个数 = 1 partitoner组件就无效了 不存在分区的结果//这边设置为6,因为没有匹配到的就到第5个job.setNumReduceTasks(6);//告诉框架,我们程序使用的数据读取组件 结果输出所用的组件是什么//TextInputFormat是mapreduce程序中内置的一种读取数据组件 准确的说 叫做 读取文本文件的输入组件job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);//告诉框架,我们要处理的数据文件在那个路劲下FileInputFormat.setInputPaths(job, new Path("/Users/jdxia/Desktop/website/hdfs/flowsum/input"));//如果有这个文件夹就删除Path out = new Path("/Users/jdxia/Desktop/website/hdfs/flowsum/output");FileSystem fileSystem = FileSystem.get(conf);if (fileSystem.exists(out)) {fileSystem.delete(out, true);}//告诉框架,我们的处理结果要输出到什么地方FileOutputFormat.setOutputPath(job, out);boolean res = job.waitForCompletion(true);System.exit(res?0:1);}}

若有收获,就点个赞吧
0 人点赞
