用户身份
客户端操作hdfs时是有一个用户身份的,默认情况下,hdfs客户端api会从jvm中获取一个参数来作为自己的用户身份,-DHADOOP_USER_NAME=x, x为用户名称\
代码中也可以设置,代码优先级最高
列出文件
package com.hdfs;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.LocatedFileStatus;import org.apache.hadoop.fs.Path;import org.apache.hadoop.fs.RemoteIterator;import java.io.IOException;public class TestHDFS {public static void main(String[] args) throws IOException {Configuration conf = new Configuration();//设置默认的文件系统conf.set("fs.defaultFS","hdfs://master:9000");//首先需要一个hdfs的客户端对象FileSystem fs = FileSystem.get(conf);//第一个参数是路径,第二个参数是递归,false表示不需要//获取/下的文件RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), false);//通过这个迭代器可以遍历出我们hdfs文件系统根目录下的文件while (listFiles.hasNext()) {LocatedFileStatus fileStatus = listFiles.next();Path path = fileStatus.getPath();String filename = path.getName();//只显示文件,不显示文件夹System.out.println(filename);//块大小System.out.println(fileStatus.getBlockSize());//权限System.out.println(fileStatus.getPermission());//组System.out.println(fileStatus.getGroup());//长度System.out.println(fileStatus.getLen());BlockLocation[] blockLocations = fileStatus.getBlockLocations();for(BlockLocation bl : blockLocations) {//位置的角标System.out.println("block-offset: " + bl.getOffset());//块的位置String[] hosts = bl.getHosts();for(String host:hosts) {System.out.println(host);}}}}}
判断是否是文件
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME","root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//判断是否是文件还是文件夹
FileStatus[] listStatus = fs.listStatus(new Path("/"));
for(FileStatus fileStatus:listStatus) {
//如果是文件
if(fileStatus.isFile()) {
System.out.println(fileStatus.getPath().getName());
}
}
本地copy到hdfs
发生这个问题,是你代码执行的环境是一个用户名和其他组,但是hdfs有自己的用户名和组别,需要你这边伪造下,不然就取你电脑上的用户名和组别,就会发生权限问题
代码
package com.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME","root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//把本地文件copy到hdfs
fs.copyFromLocalFile(new Path("/Users/jdxia/Desktop/website/i.txt"), new Path("/"));
fs.close();
}
}
hdfscopy到本地
copy到本地的话,也涉及到本地的一些权限
代码
package com.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//把远程的文件copy到本地
//第一个参数是否删除原文件
//第四个参数表示需要不需要要用本地文件系统,开启文件校验
fs.copyToLocalFile(false, new Path("/i.txt"), new Path("/Users/jdxia/Desktop/website/hdfs"), true);
fs.close();
}
}
windows开发注意
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
- 用windows平台下编译的hadoop安装包解压一份到windows的任意一个目录下
- 在window系统中配置HADOOP_HOME指向你解压的安装包目录
- 在windows系统的path变量中加入HADOOP_HOME的bin目录
api流进行文件上传
package com.hdfs;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileInputStream;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//输入流
FileInputStream in = new FileInputStream("/Users/jdxia/Desktop/website/hdfs/hello.txt");
//输出流
Path path = new Path("/hello.txt");
FSDataOutputStream out = fs.create(path);
//commons包的工具
IOUtils.copy(in,out);
//或者这样
//IOUtils.copyBytes(in,out, conf);
//关闭资源
IOUtils.closeStream(in);
IOUtils.closeStream(out);
}
}
api流进行文件下载
package com.hdfs;
import org.apache.commons.io.IOUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置也可以这样
//FileSystem fs = FileSystem.get(new URI("hdfs://master:9000"), conf, "root");
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
FSDataInputStream in = fs.open(new Path("/hello.txt"));
FileOutputStream out = new FileOutputStream(new File("/Users/jdxia/Desktop/website/hdfs/hello.txt"));
IOUtils.copy(in,out);
fs.close();
}
}
目录操作
创建目录
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//目录操作
fs.mkdirs(new Path("/nihao/hello"));
fs.close();
}
}
删除夹
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//目录操作,如果是非空文件夹,第二个参数表示递归删除,要给true
//一直会把hello也删除
fs.delete(new Path("/nihao/hello"),true);
fs.close();
}
}
重命名
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//重命名文件或文件夹
fs.rename(new Path("/nihao"),new Path("/lihao"));
fs.close();
}
}
查看目录下的文件信息
显示文件不显示文件夹
package com.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//第一个参数是路径,第二个参数是递归,false表示不需要
//获取/下的文件
RemoteIterator<LocatedFileStatus> listFiles = fs.listFiles(new Path("/"), true);
//通过这个迭代器可以遍历出我们hdfs文件系统根目录下的文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println(fileStatus.getPath().getName());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getLen());
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
for (BlockLocation bl : blockLocations) {
System.out.println("block-length: "+bl.getLength()+"---"+"block-offset"+bl.getOffset());
String[] hosts = bl.getHosts();
for (String host:hosts) {
System.out.println(host);
}
}
System.out.println("------------");
}
fs.close();
}
}
查看文件及文件夹信息
package com.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.IOException;
public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
FileStatus[] listStatus = fs.listStatus(new Path("/"));
String flag = "";
for (FileStatus fstatus : listStatus) {
if (fstatus.isFile()) {
flag = "f-- ";
} else {
flag = "d-- ";
}
System.out.println(flag + fstatus.getPath().getName());
System.out.println(fstatus.getPermission());
}
fs.close();
}
}
精准读取
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//先获取一个文件的输入流----针对hdfs上的
FSDataInputStream in = fs.open(new Path("/iloveyou.txt"));
//可以将流的起始偏移量进行自定义
in.seek(22);
//再构造一个文件的输出流----针对本地的
FileOutputStream out = new FileOutputStream(new File("d:/iloveyou.line.2.txt"));
//第三个参数表示要读取多大,第四个参数表示要关闭这个流
IOUtils.copyBytes(in,out, 19L, true);
读取指定block
public void testCat() throws IllegalArgumentException, IOException{
FSDataInputStream in = fs.open(new Path("/weblog/input/access.log.10"));
//拿到文件信息
FileStatus[] listStatus = fs.listStatus(new Path("/weblog/input/access.log.10"));
//获取这个文件的所有block的信息
BlockLocation[] fileBlockLocations = fs.getFileBlockLocations(listStatus[0], 0L, listStatus[0].getLen());
//第一个block的长度
long length = fileBlockLocations[0].getLength();
//第一个block的起始偏移量
long offset = fileBlockLocations[0].getOffset();
System.out.println(length);
System.out.println(offset);
//获取第一个block写入输出流
// IOUtils.copyBytes(in, System.out, (int)length);
byte[] b = new byte[4096];
FileOutputStream os = new FileOutputStream(new File("d:/block0"));
while(in.read(offset, b, 0, 4096)!=-1){
os.write(b);
offset += 4096;
if(offset>length) return;
};
os.flush();
os.close();
in.close();
}
一致性模型
简介
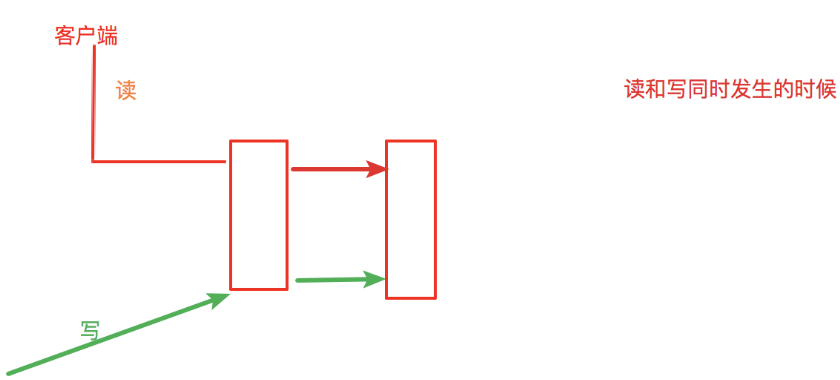
如果同时发生
写那边不刷新的话,会等读完了再写
可以设置写一个读一个
例子
刷新机制可以保证数据可靠性,影响性能
默认是关闭后才可靠
Configuration conf = new Configuration();
//设置默认的文件系统
conf.set("fs.defaultFS", "hdfs://master:9000");
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME","root");
//首先需要一个hdfs的客户端对象
FileSystem fs = FileSystem.get(conf);
//获取输出流,hdfs路径
FSDataOutputStream fos = fs.create(new Path("/hello.txt"));
//写数据
fos.write("x".getBytes);
//刷新,立即生效,没有的话,不是立即生效
//可把这行去掉断点调试看看
fos.hflush();
//关闭资源
IOUtils.closeStream(fos);
fs.close();
hadoop的RPC框架使用
协议
ClientNameNodeProtocal
package com.hadooprpc.protocal;
public interface ClientNameNodeProtocal {
//版本号
public static final long versionID = 1L;
public String getMetaData(String path);
}
server端
NameNode
package com.hadooprpc.server;
import com.hadooprpc.protocal.ClientNameNodeProtocal;
//服务被调用实现方
public class NameNode implements ClientNameNodeProtocal {
//返回元数据信息
@Override
public String getMetaData(String path) {
//path是文件路径,备份数是2,备份快blk_1,blk_2
//blk_1在master,slave节点上
//blk_2在master,slave节点上
return path + "2 {blk_1,blk_2} {blk_1:master,slave}{blk2:master.slave}";
}
}
ServerPublisher
package com.hadooprpc.server;
import com.hadooprpc.protocal.ClientNameNodeProtocal;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
//服务发布
public class ServerPublisher {
public static void main(String[] args) throws IOException {
//所有rpc的配置都是通过new Configuration()来的,我们这给个空的配置
RPC.Builder builder = new RPC.Builder(new Configuration());
//setProtocol是设置协议
//setInstance设置实现类
builder.setBindAddress("localhost").setPort(8787).setProtocol(ClientNameNodeProtocal.class).setInstance(new NameNode());
//然后我们把他发布
RPC.Server server = builder.build();
//把服务启动起来
server.start();
}
}
client端
HDFSClient
package com.hadooprpc.client;
import com.hadooprpc.protocal.ClientNameNodeProtocal;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.ipc.RPC;
import java.io.IOException;
import java.net.InetSocketAddress;
public class HDFSClient {
public static void main(String[] args) throws IOException {
//这边获取namenode
ClientNameNodeProtocal namenode = RPC.getProxy(ClientNameNodeProtocal.class, 1L, new InetSocketAddress("localhost", 8787), new Configuration());
//可以把远程的namenode当成本地使用,这就是rpc的使用
//获取这个path的元数据信息
String metaData = namenode.getMetaData("/a.txt");
System.out.println(metaData);
}
}
rpc通信源码
HDFS相关
ClientDatanodeProtocol : 一个客户端和datanode之间的协议接口,用于数据块恢复
ClientProtocol : client和Namenode交互的接口,所有控制流的请求均在这里,如创建文件,删除文件等
DatanodeProtocol : Datanode与Namenode交互的接口,如心跳,blockreport等
NamenodeProtocol : SecondaryNode与Namenode交互的接口
Mapreduce相关
InterDatanodeProtocol : Datanode内部交互的接口,用来更新block的元数据
InnerTrackerProtocol : TaskTracker与JobTracker交互的接口,功能与DatanodeProtocol相似
JobSubmissionProtocol : JobClient与JobTracker交互的接口,用来提交Job,获得Job等与Job相关的操作
TaskUmbilicalProtocol : Task中子进程与母进程交互的接口,子进程即map,reduce等操作,母进程即TaskTracker,该接口可以回报子进程的运行状态

若有收获,就点个赞吧
0 人点赞
