三大发行版本
Hadoop三大发行版本:Apache、Cloudera、Hortonworks。
- Apache版本最原始(最基础)的版本,对于入门学习最好。2006
- Cloudera内部集成了很多大数据框架,对应产品CDH。2008
- Hortonworks文档较好,对应产品HDP。2011
Hortonworks现在已经被Cloudera公司收购,推出新的品牌CDP
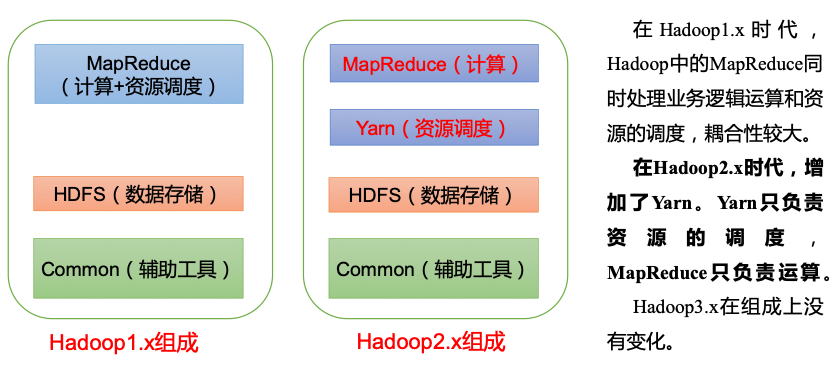
1.x,2.x,3.x区别
hdfs架构
- namenode(nn): 存储文件的元数据, 比如文件名, 目录结构, 文件属性(生成时间, 副本数, 文件权限),以及每个文件的块列表和块所在的DataNode等
- DataNode(dn): 在本地文件系统中存储文件块数据, 以及块数据的校验和
- Secondary NameNode(2nn): 每隔一段时间对namenode进行备份
Yarn架构

MapReduce架构
MapReduce将计算过程分为两个阶段:Map和Reduce
1)Map阶段并行处理输入数据
2)Reduce阶段对Map结果进行汇总hdfs, yarn, mapreduce关系
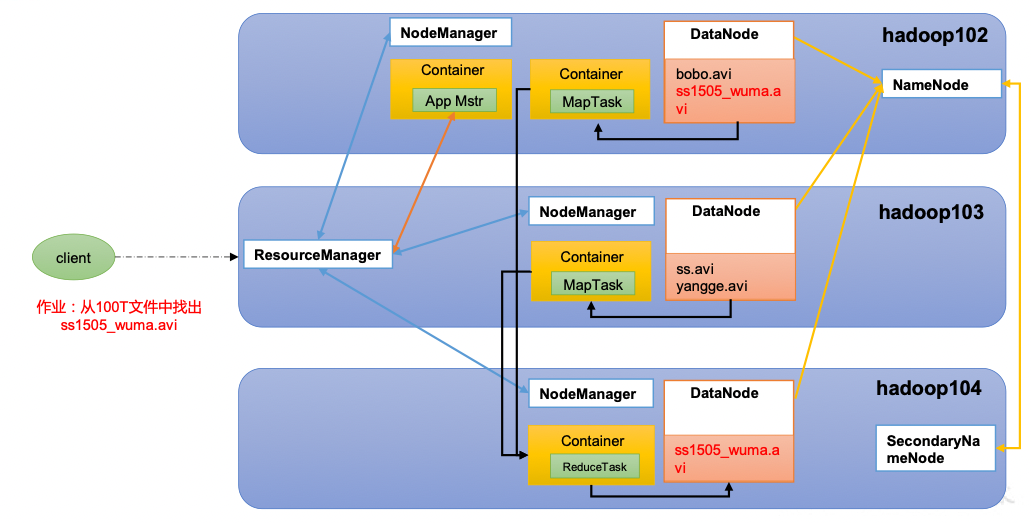
HDFS模拟实现
yarn模拟实现思路
三大组件
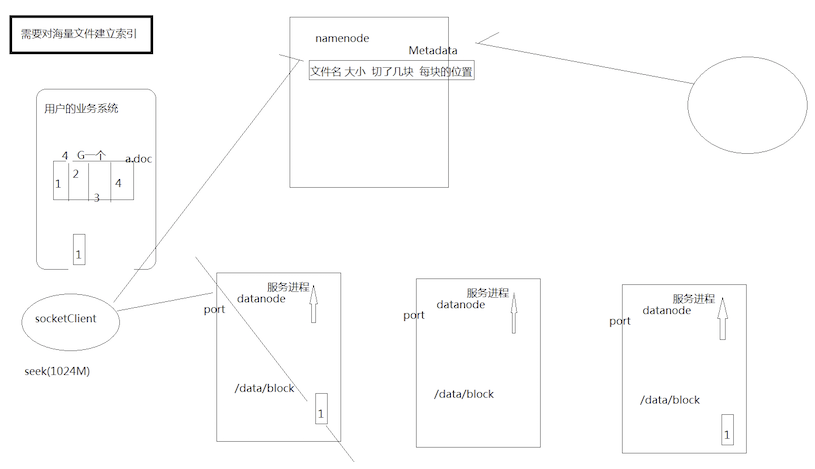
解决海量数据的存储问题
分布式文件系统(HDFS)
- 具有分布式的集群结构 我们把这样实际存储数据的节点叫做 datanode
- 具有一个统一对外提供查询 存储 搜索 机器节点
对外跟客户端统一打交道
对内跟实际存储数据的节点打交道 - 具有备份的机制 解决了机器挂掉时候数据丢失的问题
- 具有统一的API 对客户端来说不用操心你集群内部的事情 只要我调用你的API,
我就可以进行文件的读取 存储 甚至是搜索
甚至我们希望可以提供一个分布式文件系统的引用 fs= new FileSystem()
fs.add .copy .rm
与其他文件系统不同的是,HDFS一个典型的数据块大小是128M(HDFS在2.7版本默认的64M升到128M),HDFS中的每个文件都会按照128MB切分成不同的数据块,每个数据块会按照设置的副本策略分布到不同的Datanode.
HDFS数据块远大于其他文件系统,这主要针对大规模的流式数据访问而做的优化.更大的数据块意味着更多文件顺序读写和更小的数据块管理开销
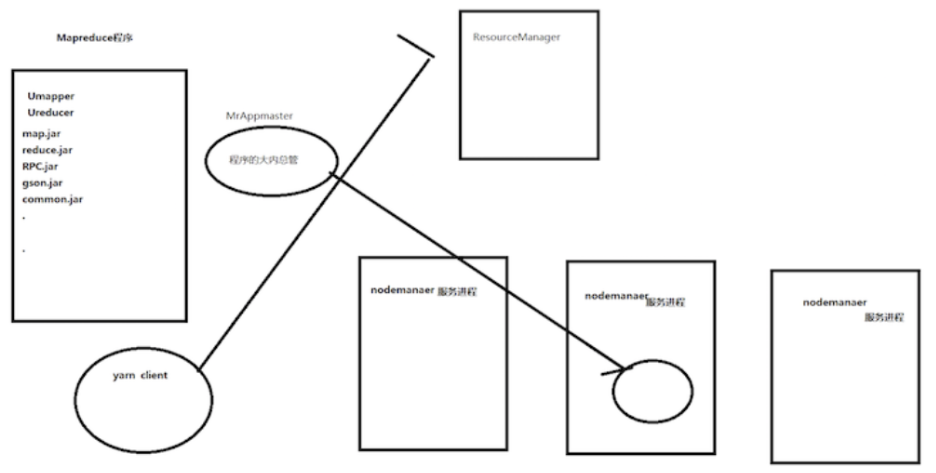
解决分布式数据计算(处理)问题
分布式的编程模型 (MapReduce)
思想 分而治之:先局部 再总体
map(映射) reduce(聚合)
整天上作为一个编程模型:需要给用户提供一个友好 便捷的使用规范
比如:你要继承什么东西 配置什么 怎么去调用 怎么去执行
- 继承我们的一个mapper 实现自己的业务逻辑
- 继承我们的一个reduce 实现自己的业务逻辑
- 最好可以提供可供用户进行相关配置的类 或者配置文件
作为一个分布式计算框架 最好我们还提供一个程序的总管(MrAppmater) 用来管理这种分布式计算框架的内部问题:启动 衔接 等等
解决了分布式系统的资源管理问题
分布式资源管理(yarn)
为了更好的管理我们集群的资源 最好设计成分布式的架构
- 需要一个统一对外提供服务的节点(某一机器 或者机器上的一个进程 一个服务)
叫做资源管理者 ResourceManager - 需要在集群中的每台机器上有一个角色 用来进行每台机器资源的管理 汇报
叫做节点管理者 nodemanagerhadoop生态圈以及各组成部分的简介
各组件简介
重点组件:
- HDFS:分布式文件系统
- MAPREDUCE:分布式运算程序开发框架
- HIVE:基于大数据技术(文件系统+运算框架)的SQL数据仓库工具
- HBASE:基于HADOOP的分布式海量数据库
- ZOOKEEPER:分布式协调服务基础组件
- Mahout:基于mapreduce/spark/flink等分布式运算框架的机器学习算法库
- Oozie:工作流调度框架
- Sqoop:数据导入导出工具
- Flume:日志数据采集框架
项目架构
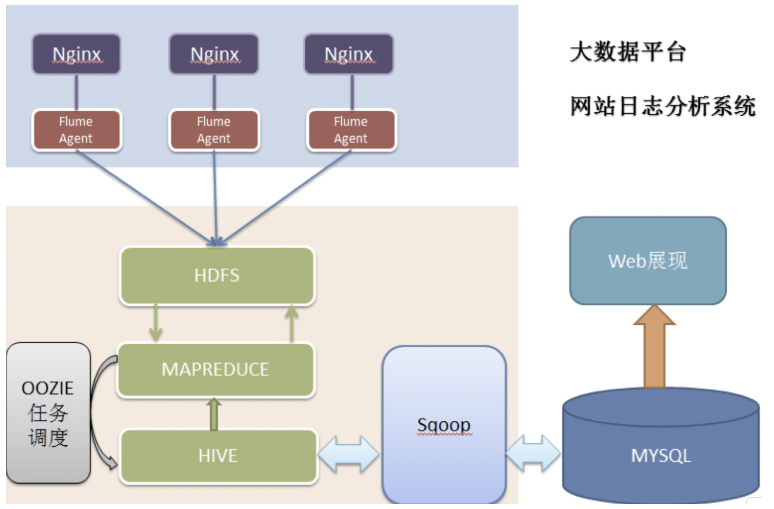
目录介绍
- bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
- etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
- lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
- sbin目录:存放启动或停止Hadoop相关服务的脚本
- share目录:存放Hadoop的依赖jar包、文档、和官方案例

若有收获,就点个赞吧
0 人点赞
