常用数据序列化类型
常用的数据类型对应的hadoop数据序列化类型
| java类型 | Hadoop Writable类型 |
|---|---|
| boolean | BooleanWritable |
| byte | ByteWritable |
| int | IntWritable |
| float | FloatWritable |
| long | LongWritable |
| double | DoubleWritable |
| string | Text |
| map | MapWritable |
| array | ArrayWritable |
思路
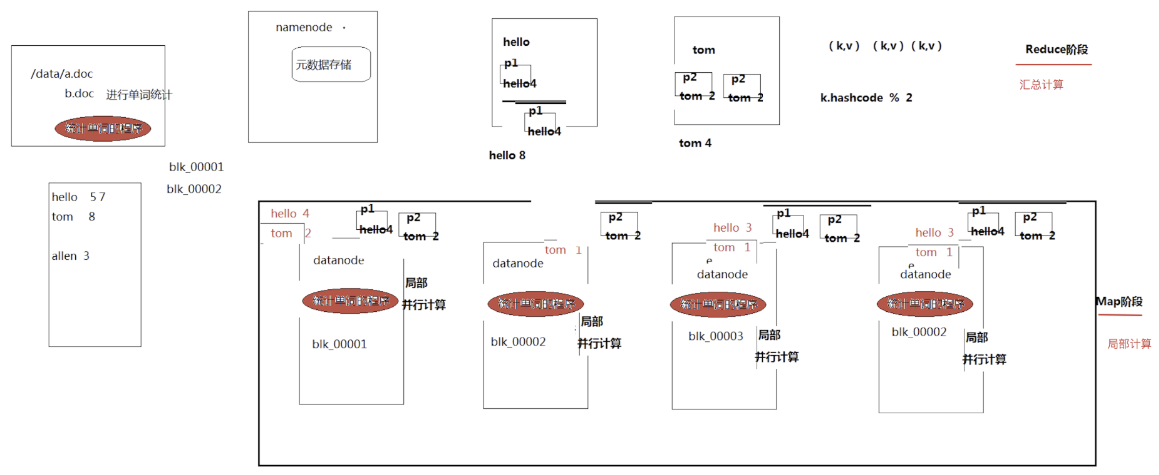
准备数据
1.txt
hello tom hello jdxia hello allentom allen jdxia hello
2.txt
hello allen hello tom allenhello jack hello
然后在hdfs上创建目录
hadoop fs -mkdir -p /worldCount/input
然后把这2个文件传到hdfs上
hadoop fs -put 1.txt 2.txt /worldCount/input
代码
map代码
import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Mapper;import java.io.IOException;/*** mapper继承mapreduce的mapper* Mapper<KEYIN,VALUEIN,KEYOUT,VALUEOUT>* KEYIN:是值框架读取到的数据的key类型* 在默认的读取数据组件InputFormat下,读取的key是一行文本的偏移量,所以key的类型是long类型的* <p>* VALUEIN是指框架读取到的数据的value类型* 在默认的读取数据组件InputFormat下,读到的value就是一行文本的内容,所以value的类型就是String类型的* <p>* KEYOUT是指用户自定义的逻辑方法返回的数据中的key的类型,* 这个是由用户业务逻辑决定的,在我们单词统计中,我们输出的是单词作为key,所以类型是String* <p>* VALUEOUT是指用户自定义逻辑方法返回的数据中value类型,这个是由用户业务逻辑决定的* 在我们的单词统计业务中,我们输出的是单词数量作为value,所以类型是Integer* <p>* 但是,String,Long都是jdk自带的数据类型,在序列化的时候,效率比较低,hadoop为了提高效率,他就自定义了一套数据结构* 所以说我们的hadoop程序中,如果该数据需要进行序列化(写磁盘,或者网络传输),就一定要用实现了hadoop虚拟化框架的数据类型* <p>* Long -----> LongWritable* String ---> Text* Integer ----> IntWritable* null -----> nullWritable*/public class WorldCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {Text k = new Text();IntWritable v = new IntWritable(1);/*** 这个map方法就是mapreduce主体程序,MapTask所调用的用户业务逻辑方法* Maptask会驱动我们读取数据组件InputFormat去读取数据(KEYIN,VALUEIN),每读取一个(K,V),他就会传入这个用户写的map方法中调用一次* 在默认的inputFormat实现中,此处的key就是一行的起始偏移量,value就是一行的内容* 这个方法会被调用一次,当他key/value传进来的时候,传一次调用一次*/@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {//获取每一行的文本内容,首先要把他转为jdk的类型String lines = value.toString();//按照空格切割,成为一个string数组String[] words = lines.split(" ");for (String world : words) {//如果每行中都出现个相同单词呢//单词是遍历的world,标记为1,只要出现一次就标记一次//单词是string类型,但是hadoop有自己的类型Textk.set(world);//context.write(new Text(world),new IntWritable(1));context.write(k, v);}}}
reduce代码
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* reduce类
* reducetask在调用我们的reduce方法
* reducetask应该接收到map阶段(第一阶段)中所有的maptask输出的数据中的一部分,比如(hello world先统计hello)
* 如何进行数据分发
* (key.hashcode%numReduceTask==本ReduceTask编号)numReduceTask是机器的个数,这个表示数据要分为几份
* <p>
* reducetask将接收到的kv数量拿来处理时,是这样调用我们的reduce方法的
* 先将自己接收到的所有的kv对接k分组(根据k是否相同)
* 然后将一组kv中的k传给我们的reduce方法的key变量,把这一组kv中的所有v用一个迭代器传给reduce方法的变量values
* <p>
* map的输出就是这里的输入
* <p>
* Reducer<Text, IntWritable, Text, IntWritable>
* 这个和map那边对应
*/
public class WorldCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int count = 0;
for (IntWritable v : values) {
//把v进行叠加,就是单词的数量
count += v.get();
}
context.write(key,new IntWritable(count));
}
}
运行的jar包类
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
/**
* 本类是客户端用来指定WorldCount job程序运行时所需要的很多参数
* 比如:指定那个类作为map阶段的业务逻辑,那个类作为reduce阶段的业务逻辑类
* 指定那个组件作为数据的读取组件,数据结果输出组件
* ....
* 以及其他各种所需要的参数
*/
public class WorldCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//在哪里运行就在哪里拿配置
//机器上和hadoop相关的配置文件读取过来
//这是在hadoop服务器上运行
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//告诉框架,我们程序的位置
job.setJar("/root/wordCount.jar");
//告诉框架,我们程序所用的mapper类和reduce类是什么
job.setMapperClass(WorldCountMapper.class);
job.setReducerClass(WorldCountReducer.class);
//告诉框架我们程序输出的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//告诉框架,我们程序使用的数据读取组件,结果输出所用的组件是什么
//TextInputFormat是mapreduce程序中内置的一种读取数据组件,准备的叫做读取文本的输入组件
job.setInputFormatClass(TextInputFormat.class);
//job.setOutputFormatClass(TextOutputFormat.class);
//告诉框架,我们要处理的数据文件在那个路径下
FileInputFormat.setInputPaths(job,new Path("/worldCount/input"));
//告诉框架我们的处理结果要输出到什么地方
FileOutputFormat.setOutputPath(job,new Path("/worldCount/output"));
//这边不用submit,因为一提交就和我这个没关系了,我这就断开了就看不见了
// job.submit();
//提交后,然后等待服务器端返回值,看是不是true
boolean res = job.waitForCompletion(true);
//设置成功就退出码为0
System.exit(res?0:1);
}
}
集群服务器上运行
maven把运行的jar类,WorldCountDriver这个类打成一个jar包
然后上传到服务器上
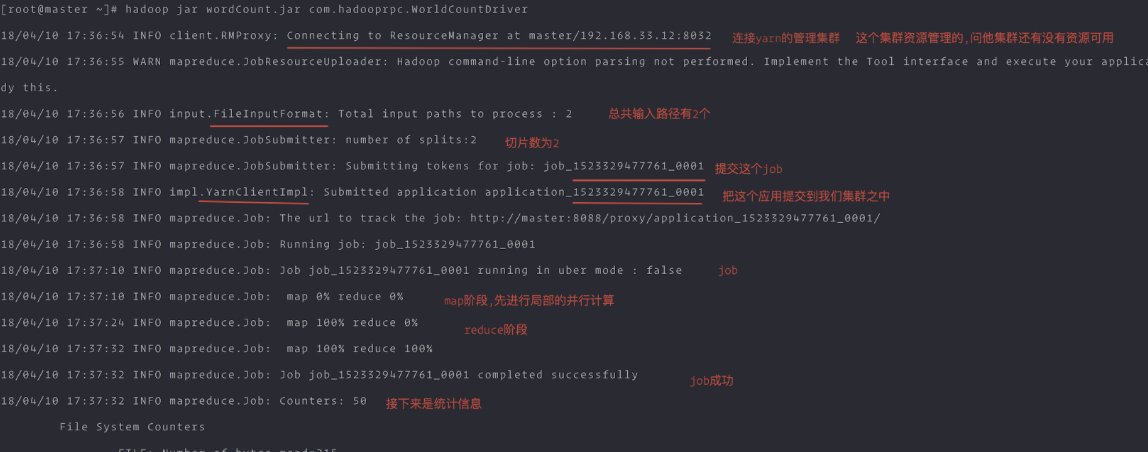
执行
hadoop jar wordCount.jar com.hadooprpc.WorldCountDriver
网页
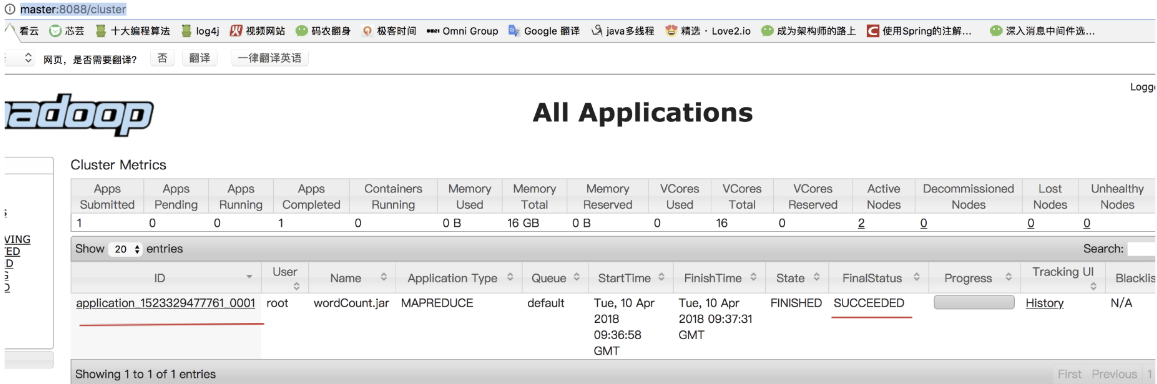
命令行
然后我们看下结果
在hdfs/worldCount/output会有结果
可以先在网页中看这个结果的文件名字叫什么
[root@master ~]# hadoop fs -cat /worldCount/output/part-r-00000
allen 4
hello 8
jack 1
jdxia 2
tom 3
本地运行(一般是本地开发,方便debug调试)
不提交到yarn上
我们先在本地创建文件夹worldCount/input
output文件夹不要创建
input文件夹里面还是写1.txt,2.txt
然后我们要在WorldCountDriver类中把jar运行的路径改下,还有input,output
package com.hadooprpc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import java.io.IOException;
/**
* 本类是客户端用来指定WorldCount job程序运行时所需要的很多参数
* 比如:指定那个类作为map阶段的业务逻辑,那个类作为reduce阶段的业务逻辑类
* 指定那个组件作为数据的读取组件,数据结果输出组件
* ....
* 以及其他各种所需要的参数
*/
public class WorldCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
//告诉框架,我们程序的位置
// job.setJar("/root/wordCount.jar");
//上面这样写,不好,换了路径又要重新写,我们改为用他的类加载器加载他自己
job.setJarByClass(WorldCountDriver.class);
//告诉框架,我们程序所用的mapper类和reduce类是什么
job.setMapperClass(WorldCountMapper.class);
job.setReducerClass(WorldCountReducer.class);
//告诉框架我们程序输出的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//告诉框架,我们程序使用的数据读取组件,结果输出所用的组件是什么
//TextInputFormat是mapreduce程序中内置的一种读取数据组件,准备的叫做读取文本的输入组件
job.setInputFormatClass(TextInputFormat.class);
//job.setOutputFormatClass(TextOutputFormat.class);
//告诉框架,我们要处理的数据文件在那个路径下
FileInputFormat.setInputPaths(job,new Path("/Users/jdxia/Desktop/website/hdfs/worldCount/input/"));
//告诉框架我们的处理结果要输出到什么地方
FileOutputFormat.setOutputPath(job,new Path("/Users/jdxia/Desktop/website/hdfs/worldCount/output/"));
//这边不用submit,因为一提交就和我这个没关系了,我这就断开了就看不见了
// job.submit();
//提交后,然后等待服务器端返回值,看是不是true
boolean res = job.waitForCompletion(true);
//设置成功就退出码为0
System.exit(res?0:1);
}
}
然后我们运行下main方法就行
由于在本地运行

他这边找不到运行的配置会找包下的默认配置,发现这边的framework是local是本地,他就不会提交到yarn上
还有这个默认配置
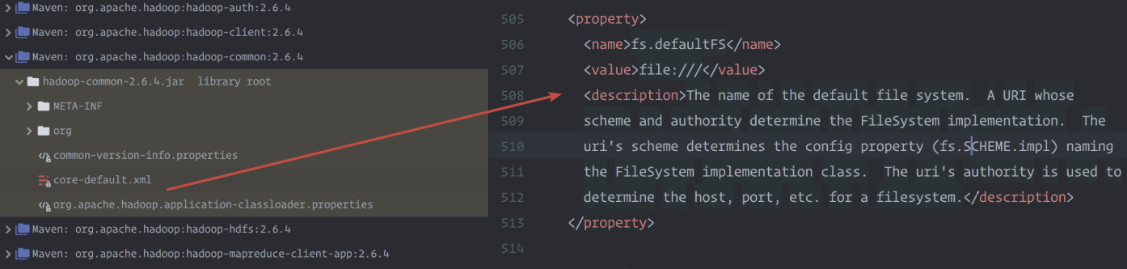
没有配置他会找这个,这是本地的文件系统
提交到yarn上
注意配置些环境变量,不然会报一些类找不到
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
Configuration conf = new Configuration();
//设置权限,也可以在vm那边伪造
System.setProperty("HADOOP_USER_NAME", "root");
conf.set("fs.defaultFS","hdfs://master:9000");
conf.set("mapreduce.framework.name","yarn");
conf.set("yarn.resourcemanager.hostname","master");
Job job = Job.getInstance(conf);
//告诉框架,我们程序的位置
// job.setJar("/root/wordCount.jar");
//上面这样写,不好,换了路径又要重新写,我们改为用他的类加载器加载他自己
job.setJarByClass(WorldCountDriver.class);
//告诉框架,我们程序所用的mapper类和reduce类是什么
job.setMapperClass(WorldCountMapper.class);
job.setReducerClass(WorldCountReducer.class);
//告诉框架,我们程序所用的mapper类和reduce类是什么
job.setMapperClass(WorldCountMapper.class);
job.setReducerClass(WorldCountReducer.class);
//告诉框架我们程序输出的类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//告诉框架,我们程序使用的数据读取组件,结果输出所用的组件是什么
//TextInputFormat是mapreduce程序中内置的一种读取数据组件,准备的叫做读取文本的输入组件
job.setInputFormatClass(TextInputFormat.class);
//告诉框架,我们要处理的数据文件在那个路径下
FileInputFormat.setInputPaths(job,new Path("/worldCount/input/"));
//告诉框架我们的处理结果要输出到什么地方
FileOutputFormat.setOutputPath(job,new Path("/worldCount/output/"));
//这边不用submit,因为一提交就和我这个没关系了,我这就断开了就看不见了
// job.submit();
//提交后,然后等待服务器端返回值,看是不是true
boolean res = job.waitForCompletion(true);
//设置成功就退出码为0
System.exit(res?0:1);
}

若有收获,就点个赞吧
0 人点赞
