例子
接上面的单词统计
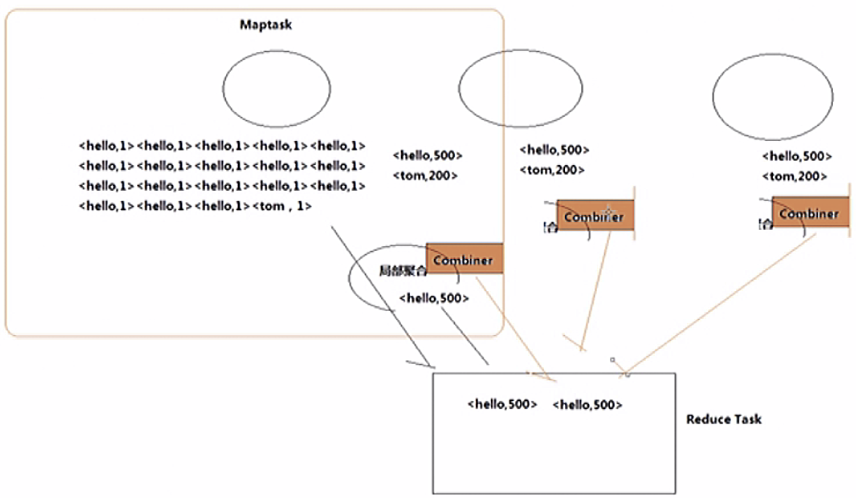
WorldCountCombiner类
package com.hadooprpc;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;public class WorldCountCombiner extends Reducer<Text, IntWritable,Text,IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int count = 0;for (IntWritable v : values) {count += v.get();}context.write(key,new IntWritable(count));}}
WorldCountDriver类
package com.hadooprpc;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.IntWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/*** 本类是客户端用来指定WorldCount job程序运行时所需要的很多参数* 比如:指定那个类作为map阶段的业务逻辑,那个类作为reduce阶段的业务逻辑类* 指定那个组件作为数据的读取组件,数据结果输出组件* ....* 以及其他各种所需要的参数*/public class WorldCountDriver {public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();//设置权限,也可以在vm那边伪造System.setProperty("HADOOP_USER_NAME", "root");conf.set("fs.defaultFS","hdfs://master:9000");conf.set("mapreduce.framework.name","yarn");conf.set("yarn.resourcemanager.hostname","master");Job job = Job.getInstance(conf);//告诉框架,我们程序的位置// job.setJar("/root/wordCount.jar");//上面这样写,不好,换了路径又要重新写,我们改为用他的类加载器加载他自己job.setJarByClass(WorldCountDriver.class);//告诉框架,我们程序所用的mapper类和reduce类是什么job.setMapperClass(WorldCountMapper.class);job.setReducerClass(WorldCountReducer.class);//告诉框架,我们程序所用的mapper类和reduce类是什么job.setMapperClass(WorldCountMapper.class);job.setReducerClass(WorldCountReducer.class);//告诉框架我们程序输出的类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//设置combainerjob.setCombinerClass(WorldCountCombiner.class);//告诉框架,我们程序使用的数据读取组件,结果输出所用的组件是什么//TextInputFormat是mapreduce程序中内置的一种读取数据组件,准备的叫做读取文本的输入组件job.setInputFormatClass(TextInputFormat.class);//告诉框架,我们要处理的数据文件在那个路径下FileInputFormat.setInputPaths(job,new Path("/worldCount/input/"));//告诉框架我们的处理结果要输出到什么地方FileOutputFormat.setOutputPath(job,new Path("/worldCount/output/"));//这边不用submit,因为一提交就和我这个没关系了,我这就断开了就看不见了// job.submit();//提交后,然后等待服务器端返回值,看是不是trueboolean res = job.waitForCompletion(true);//设置成功就退出码为0System.exit(res?0:1);}}
其他类和上面案列一样

若有收获,就点个赞吧
0 人点赞
