案例一
分析
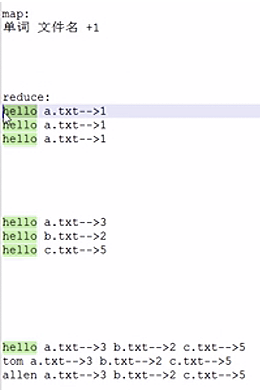
准备数据
hello--a.txt 1hello--b.txt 2hello--c.txt 1allen--b.txt 2jerry--a.txt 2allen--a.txt 1jerry--c.txt 2
代码
package com.index;import com.folwsum.FlowSumSort;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.mapreduce.Mapper;import org.apache.hadoop.mapreduce.Reducer;import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;import java.io.IOException;public class IndexStepTwo {public static class IndexStepTwoMapper extends Mapper<LongWritable, Text, Text, Text> {Text k = new Text();Text v = new Text();@Overrideprotected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {String line = value.toString();String[] fields = line.split(" ");String word_file = fields[0];String count = fields[1];String[] split = word_file.split("--");String word = split[0];String file = split[1];k.set(word);v.set(file+"--"+count);context.write(k, v); // k hello v a.txt--1}}public static class IndexStepTwoReduce extends Reducer<Text, Text, Text, Text> {Text v = new Text();@Overrideprotected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {StringBuffer sBuffer = new StringBuffer();for (Text value : values) {//拼接下格式sBuffer.append(value.toString()).append(" ");}v.set(sBuffer.toString());context.write(key, v);}}public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {Configuration conf = new Configuration();Job job = Job.getInstance();job.setJarByClass(IndexStepTwo.class);//告诉程序,我们的程序所用的mapper类和reducer类是什么job.setMapperClass(IndexStepTwoMapper.class);job.setReducerClass(IndexStepTwoReduce.class);//告诉框架,我们程序输出的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(Text.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(Text.class);//这里可以进行combiner组件的设置job.setCombinerClass(IndexStepTwoReduce.class);//告诉框架,我们程序使用的数据读取组件 结果输出所用的组件是什么//TextInputFormat是mapreduce程序中内置的一种读取数据组件 准确的说 叫做 读取文本文件的输入组件job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);//告诉框架,我们要处理的数据文件在那个路劲下FileInputFormat.setInputPaths(job, new Path("/Users/jdxia/Desktop/website/hdfs/index/input/"));//如果有这个文件夹就删除Path out = new Path("/Users/jdxia/Desktop/website/hdfs/index/output/");FileSystem fileSystem = FileSystem.get(conf);if (fileSystem.exists(out)) {fileSystem.delete(out, true);}//告诉框架,我们的处理结果要输出到什么地方FileOutputFormat.setOutputPath(job, out);boolean res = job.waitForCompletion(true);System.exit(res ? 0 : 1);}}
结果展示
里面的crc是个校验文件
allen a.txt--1 b.txt--2hello c.txt--1 b.txt--2 a.txt--1jerry c.txt--2 a.txt--2
案例二
代码前提
如果准备的数据是这样
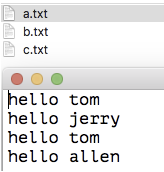
那就要把他先变成这样
hello--a.txt 1hello--b.txt 2hello--c.txt 1allen--b.txt 2jerry--a.txt 2allen--a.txt 1jerry--c.txt 2
代码
public class IndexStepOne {public static class IndexStepOneMapper extends Mapper<LongWritable, Text, Text, IntWritable>{Text k = new Text();IntWritable v = new IntWritable(1);@Overrideprotected void map(LongWritable key, Text value,Context context) throws IOException, InterruptedException {String line = value.toString();String[] words = line.split(" ");FileSplit Split = (FileSplit)context.getInputSplit();String filename = Split.getPath().getName();//输出key :单词--文件名 value:1for(String word : words){k.set(word +"--"+ filename);context.write(k, v);}}}public static class IndexStepOneReducer extends Reducer<Text, IntWritable, Text, IntWritable>{IntWritable v = new IntWritable();@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {int count = 0;for(IntWritable value : values){count += value.get();}v.set(count);context.write(key, v);}}public static void main(String[] args) throws Exception {Configuration conf = new Configuration();Job job = Job.getInstance(conf);job.setJarByClass(IndexStepOne.class);//告诉程序,我们的程序所用的mapper类和reducer类是什么job.setMapperClass(IndexStepOneMapper.class);job.setReducerClass(IndexStepOneReducer.class);//告诉框架,我们程序输出的数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//这里可以进行combiner组件的设置job.setCombinerClass(IndexStepOneReducer.class);//告诉框架,我们程序使用的数据读取组件 结果输出所用的组件是什么//TextInputFormat是mapreduce程序中内置的一种读取数据组件 准确的说 叫做 读取文本文件的输入组件job.setInputFormatClass(TextInputFormat.class);job.setOutputFormatClass(TextOutputFormat.class);//告诉框架,我们要处理的数据文件在那个路劲下FileInputFormat.setInputPaths(job, new Path("D:/index/input"));//告诉框架,我们的处理结果要输出到什么地方FileOutputFormat.setOutputPath(job, new Path("D:/index/output-1"));boolean res = job.waitForCompletion(true);System.exit(res?0:1);}}

若有收获,就点个赞吧
0 人点赞
