mapreduce和yarn交互流程
ResourceManager资源管理(有任务调度方式)
MrAppMaster是mapreduce程序的老大,向ResourceManager资源管理请求运算节点,监控启动 mapTask和reduceTask
这些mapTask和reduceTask用jps查看是yarnchild
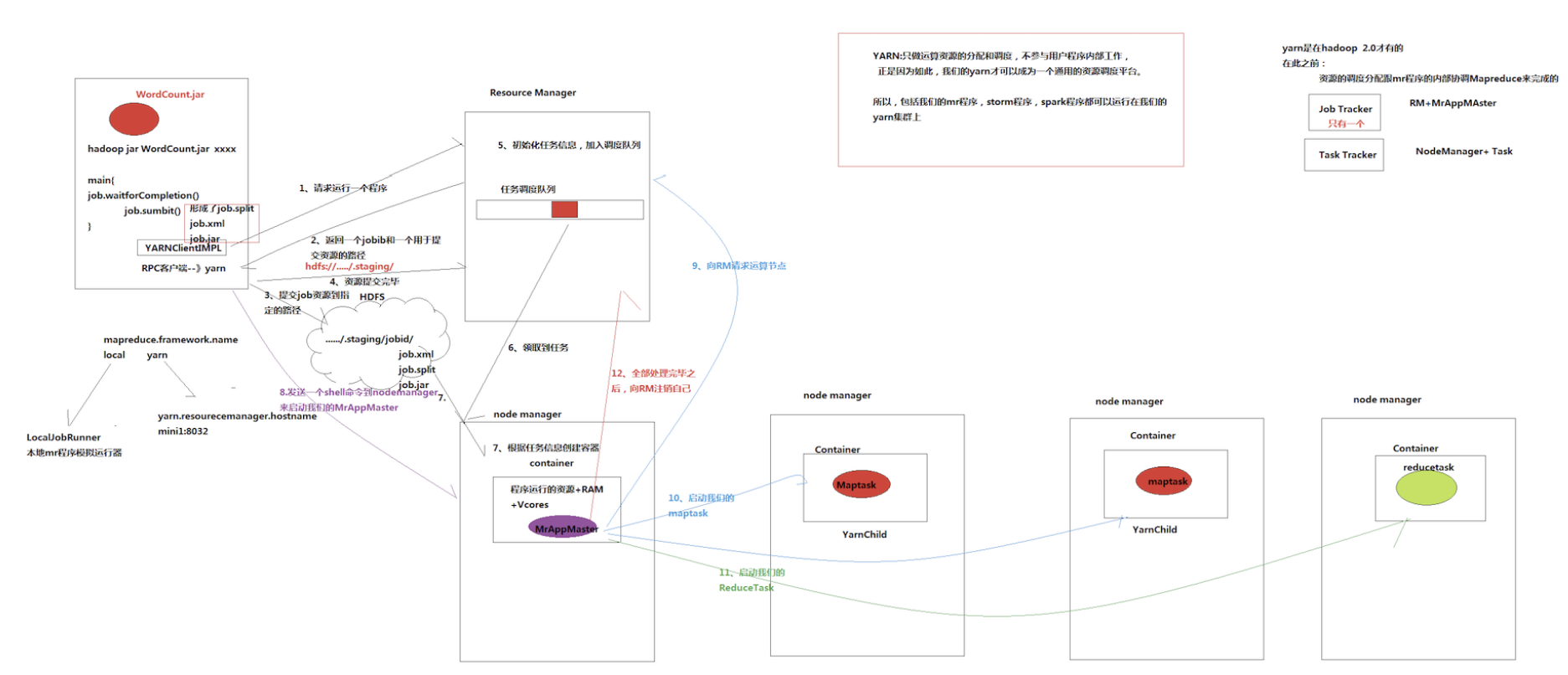
job提交流程
- 客户端调用job.submit()后会在客户端启动一个叫做yarnRunner的跟ResourceManager进行通信的RPC客户端
- yarnRunner会向resourceManager请求程序
- resourceManager返回给yarnRunner一个提交路径和一个jobID
- YarnRunner提交程序所需要的资源到HDFS
- YarnRunner向resourceManager发送提交成功的报告
- resourceManager会在内部创建任务,然后把任务放入任务队列
- NodeManager向resourceManager领取任务
- NodeManager会在内部创建运行的容器container
- YarnRunner发送mrAppmaster的启动脚本,然后在container中启动mrappmaster
- mrAppmaster启动之后会向resourceManager申请资源,需要多少个task
- 这些task所在的nodeManager会向resourceManager领取任务
- mrAppmaster会发送启动脚本,启动其他nodemanager中的container中的maptask任务
- 当maptask任务执行完毕之后,mrAppMaster会再次向resourceManager申请资源,启动相应数量的reducetask
运算的时候哪些可以自定义
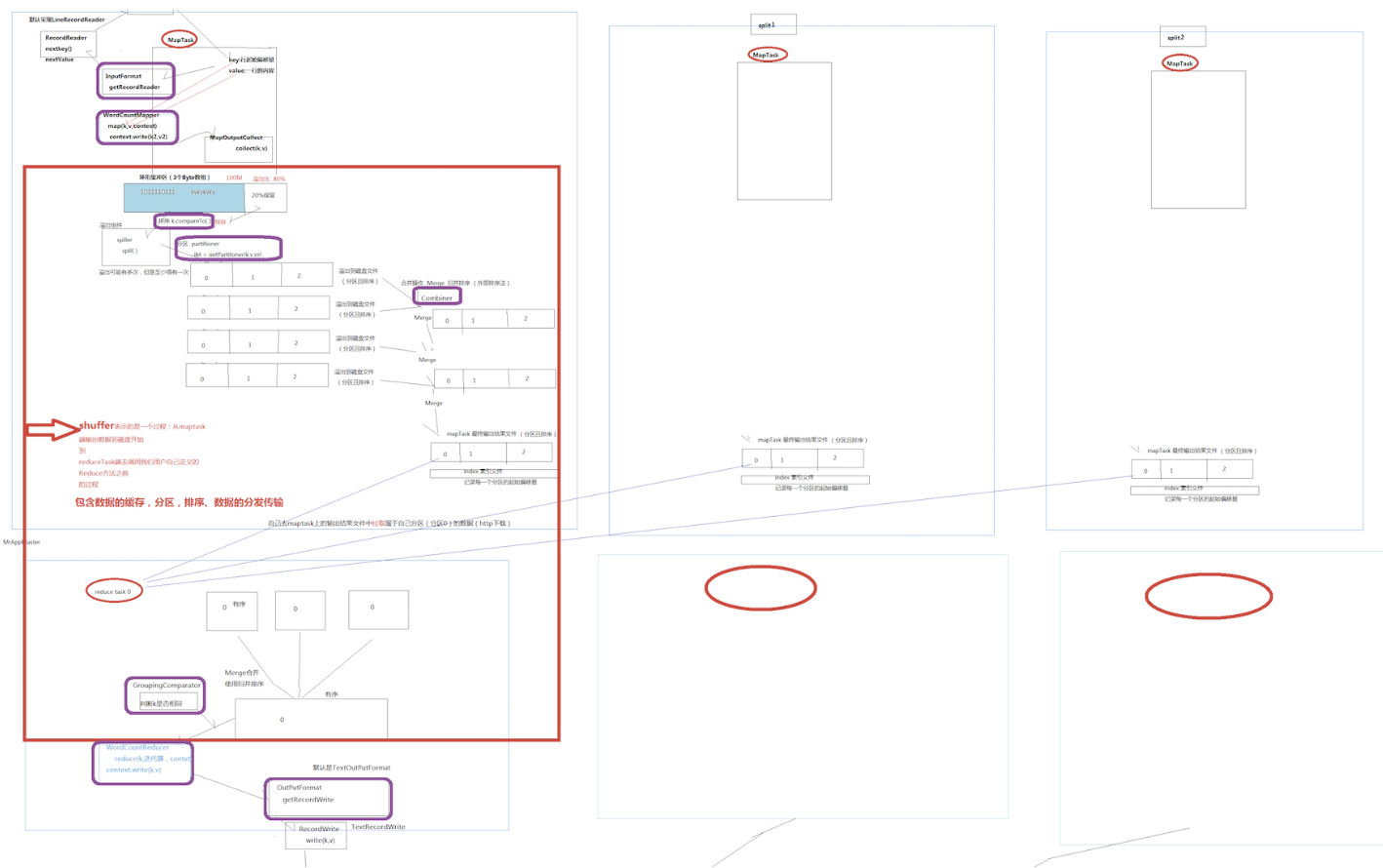

MapReduce运算主体工作流程
map
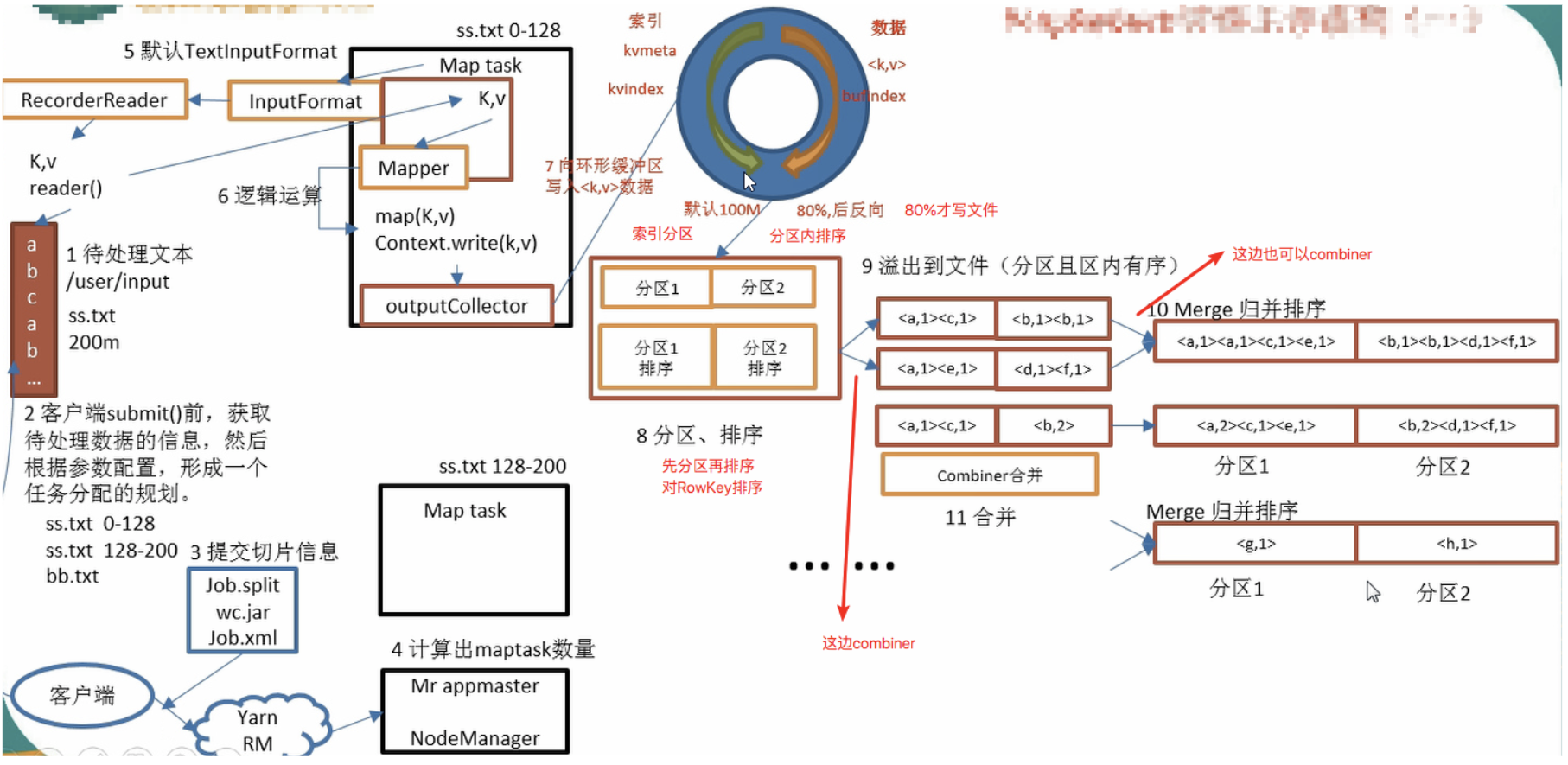
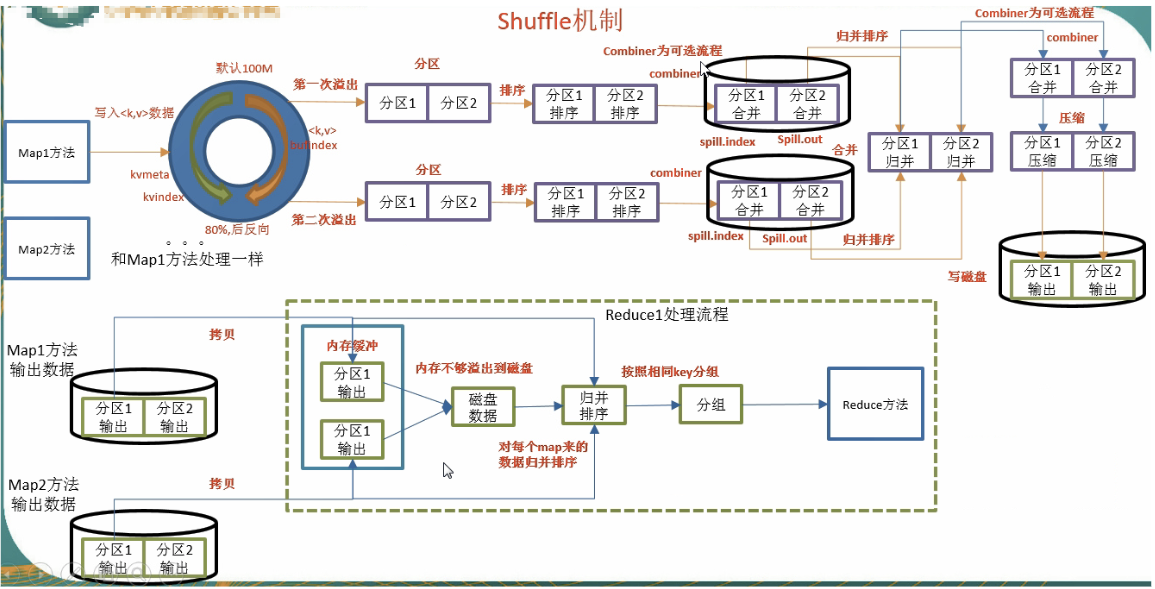
环形缓冲区大小可以通过io.sort.mb改变
环形缓冲区有一个阈值,默认0.8,可以通过io.sort.spill.percent设置,通常设置为0.6
reduce
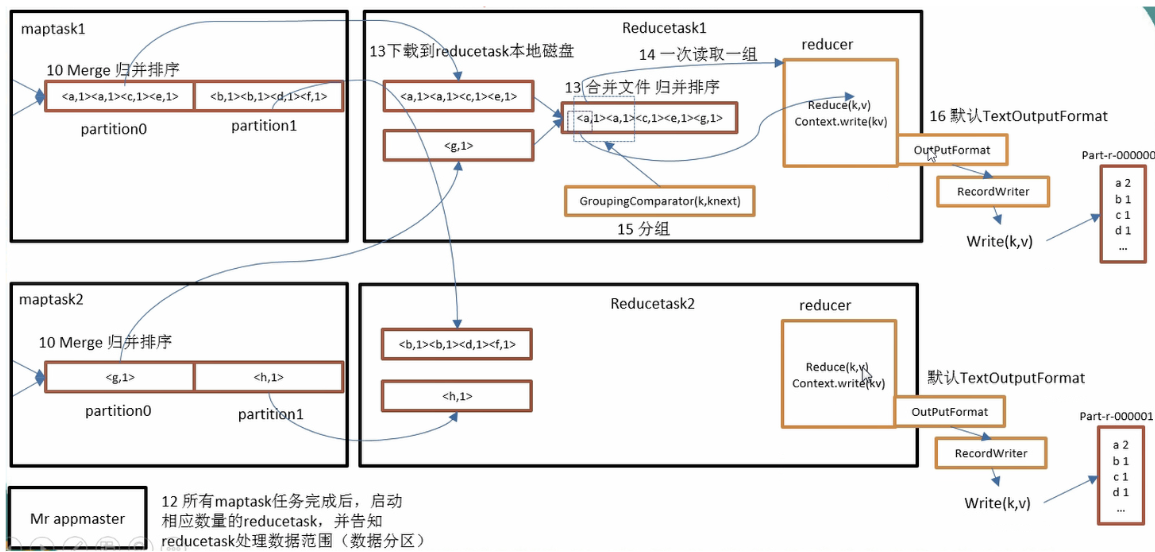
reduceTask分区数据中,有一个mapTask处理完成之后,就开始从mapTask本地磁盘拉取输出数据.拉取任务是多线程,默认是5.可根据mpred.reduce.parallel.copys设置
reduceTask复制的数据,首先保存在内存(输入缓冲区)中.由mpred.job.shuffe.input.buffer.percent属性控制,指定可用做输入缓冲区的堆内存的百分比
shuffle机制
mapreduce确保每个reduce的输入都是按键排序的,系统执行排序的过程(即将map输出作为输入传给reducer)称为shuffle
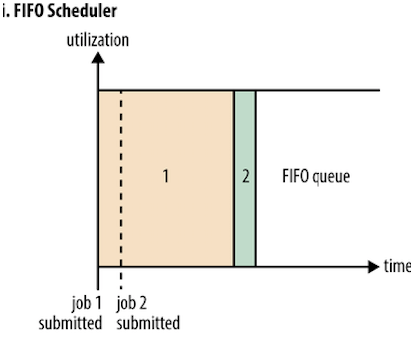
yarn调度器的方式
先进先出调度
如果第一个时间很长会阻塞后面小的,如果storm和mapreduce在一起,那么其他程序就可能被阻塞了
容量调度
默认是这种
会预留个空间给小任务执行
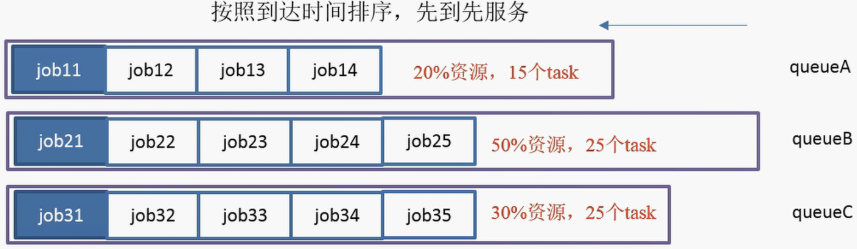
就是分成不同的空间队列,看任务大小,然后这些不同的队列不断的去拉取合适的任务来执行
单个队列内部是FIFO
- 支持多个队列,每个队列可配置一定的资源量,每个队列采用FIFO调度策略
- 为了防止同一个用户的作业独占队列中的资源,该调度器会对同一用户提交的作业所占资源量进行限定
- 首先,计算每个队列中正在运行的任务数与其应该分得的计算资源之间的比值,选择一个该比值最小的队列
- 其次,按照作业优先级和提交时间顺序,同时考虑用户资源量限制和内存限制对队列内任务排序
公平调度
大家公平的使用机器,但是会使得大任务的时候变得不确定可能会变长
动态调整

配置
hadoop作业调度器主要有三种: FIFO, Capacity Scheduler和Fair Scheduler
hadoop2.7.2默认的资源调度器是Capacity Scheduler
具体设置可见: yarn-default.xml
<property><description>The class to use as the resource scheduler</description><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value></property>

若有收获,就点个赞吧
0 人点赞
