集群简介
HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起
HDFS集群:
负责海量数据的存储,集群中的角色主要有 NameNode / DataNode
YARN集群:
负责海量数据运算时的资源调度,集群中的角色主要有 ResourceManager /NodeManager
(那mapreduce是什么呢?它其实是一个应用程序开发包)
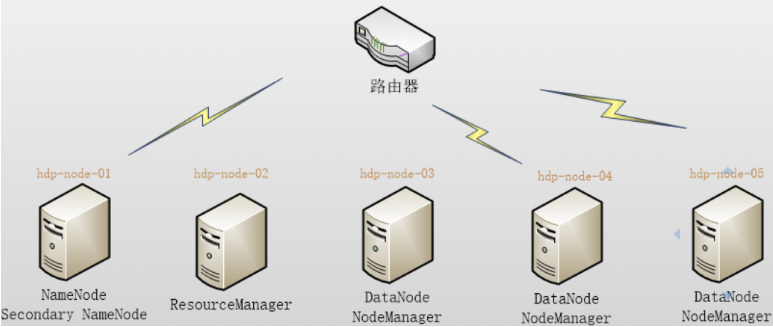
本集群搭建案例,以5节点为例进行搭建,角色分配如下
hdp-node-01 NameNode SecondaryNameNodehdp-node-02 ResourceManagerhdp-node-03 DataNode NodeManagerhdp-node-04 DataNode NodeManagerhdp-node-05 DataNode NodeManager
万万注意,hosts中不要127.0.0.1指定自己主机的别名
安装hadoop
安装jdk,1.8或者1.7
archive.apache.org/dist
这个下面有apache各个项目
下载hadoop
wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.2/hadoop-3.3.2.tar.gz或者wget https://archive.apache.org/dist/hadoop/common/hadoop-2.6.4/hadoop-2.6.4.tar.gz
注意
把下面的有关ip配置成/etc/hosts下面的别名对应ip,不然会报错
还有hostname不能搞错
时间同步
配置文件
hadoop-env.sh
hadoop下的/etc/hadoop/
里面有个hadoop-env.sh
把export JAVA_HOME=/usr/local/jdk8这个改下,原来是没有值的
core-site.xml
<configuration>
<!-- 指定hadoop所使用的文件系统schema(URI),HDFS老大(NameNode)的地址,指定的默认的文件系统,可以是别的,比如file:/ 还有TFS -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.33.12:9000</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop3/tmp/hadoop</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<!-- 指定namenode的数据存放在哪里 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hadoop3/tmp/namenode</value>
</property>
<!-- 指定datanode数据存放在哪里,路径可以配置多个,用,号隔开,不是容灾的,是负载的-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hadoop3/tmp/datanode</value>
</property>
<!--指定hdfs副本数量,默认是5个,这边设置为1个,保证数据备份和管理机制-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<!--web端口-->
<property>
<name>dfs.secondary.http.address</name>
<value>192.168.33.12:50090</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
冗余数据块自动删除
可配置删除的速度
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds</description>
</property>
通信超时设置
通信超时时间默认是10分30秒timeout = 2*heartbeat.recheck.interval+10*dfs.heartbeat.interval
2次5分钟的重试时间,10次心跳时间,还连不上就认为datanode已经挂了
需要注意的是hdfs-site.xml配置文件中的heartbeat.recheck.interval的单位为毫秒,
dfs.heartbeat.interval的单位为秒
mapred-site.xml
如果没有这个文件cp mapred-site.xml.template mapred-site.xml
<configuration>
<!--指定mr运行在yarn上,用yarn去管理mapreduce,也可以写local,那就是jvm的线程去模拟 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
配置历史服务器
<property>
<name>mapreduce.jobhistory.address</name>
<value>host:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>host:19888</value>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/history/done</value>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/history/done_intermediate</value>
</property>
yarn-site.xml
<configuration>
<!-- Site specific YARN configuration properties -->
<!--指定yarn的老大(ResourceManager)的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.33.12</value>
</property>
<!--reducer获取数据的方式-->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
开启日期聚集和保留设置
<!-- 日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
环境变量/etc/profile
# hadoop
export HADOOP_HOME=/root/hadoop3
export PATH=$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$PATH
source下
注意这些文件夹要提前创建
如果报一些错误
file:///data
试下加file:///这种的
root@box1:/opt # hadoop version
Hadoop 3.3.2
启动
首先要namenode格式下,前面是1版本,后面是2版本
namenode的初始化
hdfs namenode -format
或者
hadoop namenode -format
把hadoop文件夹分发到各个节点
然后显示
Storage directory /path/tmp/namenode has been successfully formatted.
表示目录已经被成功初始化了
[root@12 current]# pwd
/root/hadoop3/tmp/namenode/current
[root@12 current]# ls -lah
total 16K
drwxr-xr-x 2 root root 112 Apr 7 12:31 .
drwxr-xr-x 3 root root 21 Apr 7 12:31 ..
-rw-r--r-- 1 root root 389 Apr 7 12:31 fsimage_0000000000000000000
-rw-r--r-- 1 root root 62 Apr 7 12:31 fsimage_0000000000000000000.md5
-rw-r--r-- 1 root root 2 Apr 7 12:31 seen_txid
-rw-r--r-- 1 root root 212 Apr 7 12:31 VERSION
里面fsi什么的是镜像文件
seen_txid是迭代的版本号
然后我们查看下版本号
[root@12 current]# cat VERSION
#Sat Apr 07 12:31:09 UTC 2018
namespaceID=1413563114
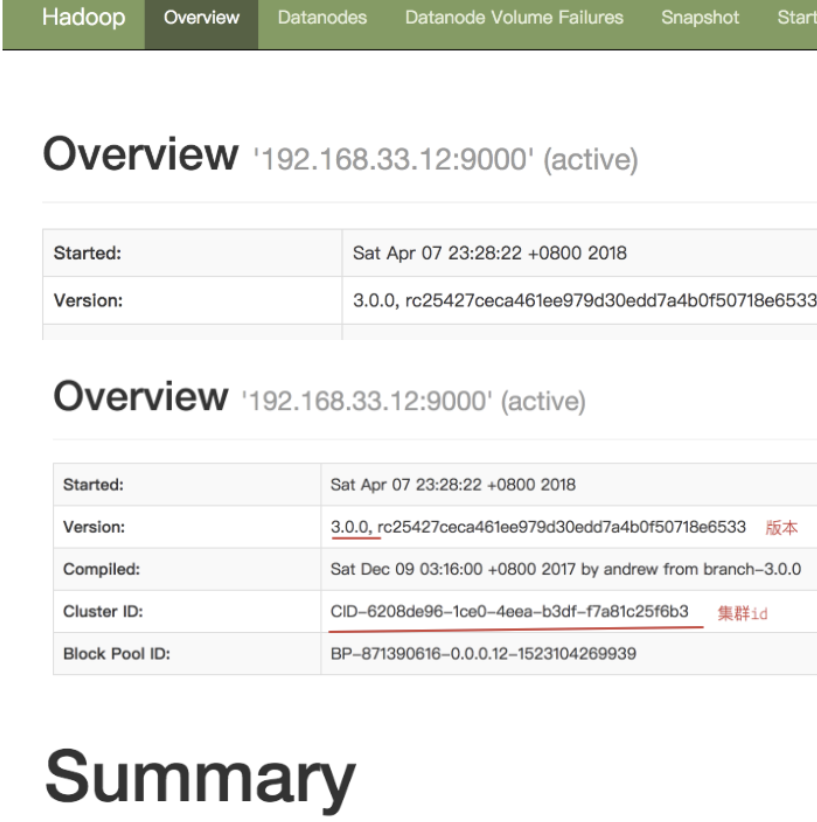
clusterID=CID-6208de96-1ce0-4eea-b3df-f7a81c25f6b3
cTime=1523104269939
storageType=NAME_NODE
blockpoolID=BP-871390616-0.0.0.12-1523104269939
layoutVersion=-64
比如我namenode的clusterID是这个,其他的datanode的clusterID也是这个值表示是一个集群
方式一:每个守护线程逐一启动
启动顺序如下:
NameNode,DateNode,SecondaryNameNode,JobTracker,TaskTracker
Hadoop-daemon.sh:用于启动当前节点的进程
例如Hadoop-daemon.sh start namenode 用于启动当前的名称节点
Hadoop-daemons.sh:用于启动所有节点的进程
例如:Hadoop-daemons.sh start datanode 用于启动所有节点的数据节点
[root@12 sbin]# hadoop-daemon.sh start namenode
这个命令在各个datanode都要执行
[root@12 sbin]# hadoop-daemon.sh start datanode
WARNING: Use of this script to start HDFS daemons is deprecated.
WARNING: Attempting to execute replacement "hdfs --daemon start" instead.
这种警告意思就是hadoop这个命令被hdfs替代了
[root@12 sbin]# hadoop-daemon.sh start secondarynamenode
查看下进程
[root@12 sbin]# jps
3856 DataNode
4019 Jps
3988 SecondaryNameNode
3515 NameNode
注意最大文件数打开,不然一启动就可能等会就退出了
yarn-daemon.sh start resourcemanager
yarn-daemon.sh start nodemanager
前提
文件最大打开数限制
ssh免密登录
注意authorized_keys这个文件里面的东西不要写错,前面ssh不要写成sh,后面也不要少
还有.ssh权限问题
# mkdir /root/.ssh
# chown -R root:root /home/ansible
# chmod 700 /root
# chmod 700 /root/.ssh
# chmod 644 /root/.ssh/authorized_keys //公钥文件的所有权限
# chmod 600 /root/.ssh/id_rsa //私钥文件的所有权限
其中这两项PubkeyAuthentication yes 和PasswordAuthentication no的值都要为yes,即公钥认证和密码认证都要为yes,因为我连接的方式是通过这两种方式来连接的,
重启sshd服务systemctl restart sshd.service
mac要注意共享设置,允许远程登录
方法二:全部启动或者全部停止
启动
start-all.sh
启动顺序:NameNode,DateNode,SecondaryNameNode,JobTracker,TaskTracker
停止
stop-all.sh
关闭顺序性:JobTracker,TaskTracker,NameNode,DateNode,SecondaryNameNode
方法三:分别启动
首先创建slaves这个文件,在hadoop的配置文件
192.168.33.12
192.169.33.22
192.168.33.3
如果你是指定master,slave1这样的话,那么这就写别名
注意即使master和192.169.0.10一样,你这边也要写对,否则ssh那边known_hosts没有的话会报错
把这个slaves这个文件放到其他机器上,写完最好检查下
如果是hadoop3的话,这边是workers,不是slaves
启动:分别启动HDFS和yarn
start-dfs.sh
start-yarn.sh
这个需要
问题
问题1
Starting namenodes on [localhost]
ERROR: Attempting to launch hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting launch.
解决:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vim sbin/start-dfs.sh
$ vim sbin/stop-dfs.sh
在空白处添加内容:
HDFS_DATANODE_USER=root
HDFS_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
问题2
Starting resourcemanager
ERROR: Attempting to launch yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting launch.
Starting nodemanagers
ERROR: Attempting to launch yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting launch.
解决:
是因为缺少用户定义造成的,所以分别编辑开始和关闭脚本
$ vim sbin/start-yarn.sh
$ vim sbin/stop-yarn.sh
在空白处添加内容:
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
启动history
启动history-server
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh start historyserver
停止history-server
$HADOOP_HOME/sbin/mr-jobhistory-daemon.sh stop historyserver
history-server启动之后,可以通过浏览器访问WEBUI: host:19888
在hdfs上会生成两个目录
hadoop fs -ls /history
drwxrwx--- - spark supergroup 0 2014-10-11 15:11 /history/done
drwxrwxrwt - spark supergroup 0 2014-10-11 15:16 /history/done_intermediate
这个目录是在mapred-site.xml中配置的
mapreduce.jobhistory.done-dir(/history/done): Directory where history files are managed by the MR JobHistory Server(已完成作业信息)
mapreduce.jobhistory.intermediate-done-dir(/history/done_intermediate): Directory where history files are written by MapReduce jobs.(正在运行作业信息)
测试:
通过hive查询city表观察hdfs文件目录和hadoop000:19888
hive> select id, name from city;
观察hdfs文件目录:
- 历史作业记录是按照年/月/日的形式分别存放在相应的目录(/history/done/2014/10/11/000000);
- 每个作业有2个不同的后缀名的记录:jhist和xml
hadoop fs -ls /history/done/2014/10/11/000000
-rwxrwx--- 1 spark supergroup 22572 2014-10-11 15:23 /history/done/2014/10/11/000000/job_1413011730351_0002-1413012208648-spark-select+id%2C+name+from+city%28Stage%2D1%29-1413012224777-1-0-SUCCEEDED-root.spark-1413012216261.jhist
-rwxrwx--- 1 spark supergroup 160149 2014-10-11 15:23 /history/done/2014/10/11/000000/job_1413011730351_0002_conf.xml
web端查看
访问 http://192.168.33.12:8088/
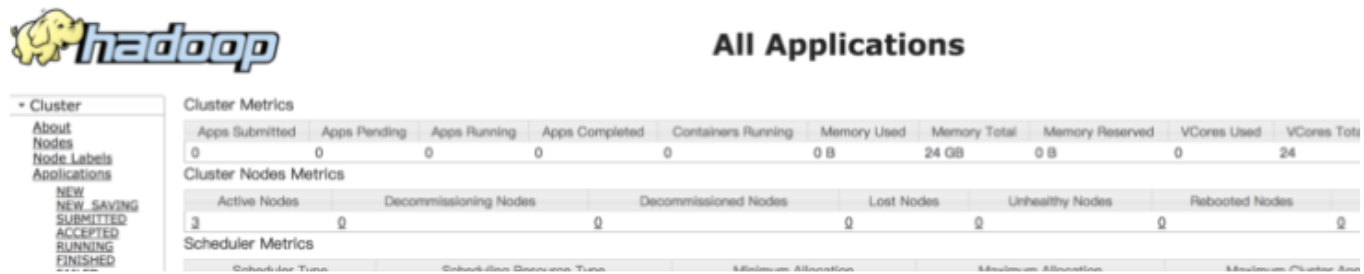
访问 http://192.168.33.12:9870,注意,这里是9870,不是50070了:

试用
把这个文件放到文件系统的/下
hdfs dfs -put anaconda-ks.cfg /
从本地上传一个文本文件到hdfs的/wordcount/input目录下
[HADOOP@hdp-node-01 ~]$ HADOOP fs -mkdir -p /wordcount/input
[HADOOP@hdp-node-01 ~]$ HADOOP fs -put /home/HADOOP/somewords.txt /wordcount/input
查看集群状态
hdfs dfsadmin –report
查看HDFS中的目录信息
hadoop fs -ls /
从HDFS下载文件
hadoop fs -get /yarn-site.xml
本地库
lib/native/
文件夹下,是和平台相关的
本地编译的话,要注意这里
例子
cd /root/hadoop2/share/hadoop/mapreduce
然后我们计算下圆周率
hadoop jar hadoop-mapreduce-examples-2.6.4.jar pi 4 8
任务

若有收获,就点个赞吧
0 人点赞
