导包
尤其是Text和CombineTextInputFormat
Mapper中第一个输入的参数必须是LongWritable或者NullWritable,不可以是IntWritable,报的错误是类型转换异常
reduce个数
java.lang.Exception:java.io.IOException:Illegal partition for 13926435656(4)
说明partition和reducetask个数没对上,调整reducetask个数
如果分区数不是1,但是reducetask为1,是否执行分区过程.答案是:不执行分区过程.因为maptask源码中,执行分区的前提先判断reduceNum个数是否大于1.不大于1肯定不执行
jvm版本
在windows环境编译的jar包导入到linux环境中运行
报如下错误
Exception in thread "main" java.lang.UnsupportedClassVersionError: com/wordcount/WordCountDriver:Unsupported major.minor version 52.0
原因是windows环境用的是jdk1.7,linux环境用的是jdk1.8,统一版本
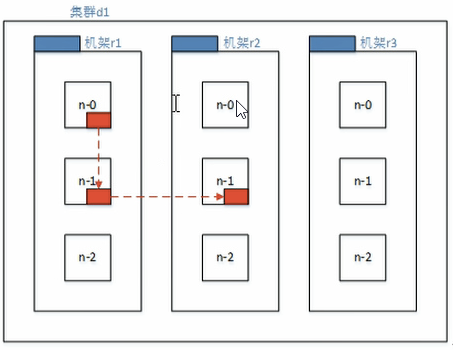
副本节点选择
低版本Hadoop副本节点选择
第一个副本在client所处的节点上.如果客户端在集群外,随机选一个
第二个副本和第一个副本位于不相同机架的随机节点上
第三个副本和第二个副本位于相同机架,节点随机
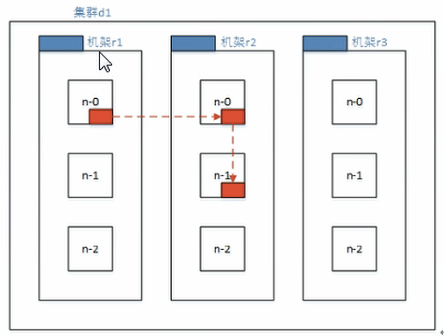
Hadoop2.7.2副本节点选择
第一个副本在client所处的节点上.如果客户端再集群外,随机选一个
第二个副本和第一个副本位于相同机架,随机节点
第三副本位于不同机架,随机节点
HDFS满足客户端访问副本数据的最近原则.客户端距离那个副本数据最近,HDFS就让哪个节点把数据给客户端
NameNode故障处理方法
方法一
将SecondaryNameNode中数据拷贝到namenode存储数据的目录
方法二
使用-importCheckpoint选项启动namenode守护进程,从而将SecondaryNameNode中数据拷贝到namenode目录中
手动拷贝SecondaryNameNode数据
模拟namenode故障,并采用方法一,恢复namenode数据
- kill -9 namenode进程
- 删除namenode存储的数据(/path/data/tmp/dfs/name/*)
- 拷贝SecondaryNameNode中数据到原namenode存储数据目录(/path/data/tmp/dfs/namesecondary/*)
- 重新启动namenode(hadoop-daemon.sh start namenode)
采用importCheckpoint命令拷贝SecondaryNameNode数据
模拟namenode故障,采用方法二,恢复namenode数据
修改hdfs-site.xml
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>120</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/path/data/tmp/dfs/name</value>
</property>
- kill -9 namenode进程
- 删除namenode存储的数据(/path/data/tmp/dfs/name/*)
- 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝带NameNode存储数据的平级目录,并删除in_use.lock文件
/path/data/tmp/dfs/namesecondary/* 拷贝过去
rm -rf in_use.lock
pwd(/path/data/tmp/dfs)
ls(data name namesecondary)
机架感知配置
Hadoop机架感知
- 背景
Hadoop在设计时考虑到数据的安全与高效,数据文件默认在HDFS上存放三份,存储策略为本地一份,同机架内其它某一节点上一份,不同机架的某一节点上一份。这样如果本地数据损坏,节点可以从同一机架内的相邻节点拿到数据,速度肯定比从跨机架节点上拿数据要快;同时,如果整个机架的网络出现异常,也能保证在其它机架的节点上找到数据。为了降低整体的带宽消耗和读取延时,HDFS会尽量让读取程序读取离它最近的副本。如果在读取程序的同一个机架上有一个副本,那么就读取该副本。如果一个HDFS集群跨越多个数据中心,那么客户端也将首先读本地数据中心的副本。那么Hadoop是如何确定任意两个节点是位于同一机架,还是跨机架的呢?答案就是机架感知。
默认情况下,hadoop的机架感知是没有被启用的。所以,在通常情况下,hadoop集群的HDFS在选机器的时候,是随机选择的,也就是说,很有可能在写数据时,hadoop将第一块数据block1写到了rack1上,然后随机的选择下将block2写入到了rack2下,此时两个rack之间产生了数据传输的流量,再接下来,在随机的情况下,又将block3重新又写回了rack1,此时,两个rack之间又产生了一次数据流量。在job处理的数据量非常的大,或者往hadoop推送的数据量非常大的时候,这种情况会造成rack之间的网络流量成倍的上升,成为性能的瓶颈,进而影响作业的性能以至于整个集群的服务
- 配置
默认情况下,namenode启动时候日志是这样的:
2013-09-22 17:27:26,423 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/ 192.168.147.92:50010
每个IP 对应的机架ID都是 /default-rack ,说明hadoop的机架感知没有被启用。
要将hadoop机架感知的功能启用,配置非常简单,在 NameNode所在节点的/home/bigdata/apps/hadoop/etc/hadoop的core-site.xml配置文件中配置一个选项:
<property>
<name>topology.script.file.name</name>
<value>/home/bigdata/apps/hadoop/etc/hadoop/topology.sh</value>
</property>
这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架ID,保存到内存的一个map中.
至于脚本的编写,就需要将真实的网络拓朴和机架信息了解清楚后,通过该脚本能够将机器的ip地址和机器名正确的映射到相应的机架上去。一个简单的实现如下:
#!/bin/bash
HADOOP_CONF=/home/bigdata/apps/hadoop/etc/hadoop
while [ $# -gt 0 ] ; do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]; then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
topology.data,格式为:节点(ip或主机名) /交换机xx/机架xx
192.168.147.91 tbe192168147091 /dc1/rack1
192.168.147.92 tbe192168147092 /dc1/rack1
192.168.147.93 tbe192168147093 /dc1/rack2
192.168.147.94 tbe192168147094 /dc1/rack3
192.168.147.95 tbe192168147095 /dc1/rack3
192.168.147.96 tbe192168147096 /dc1/rack3
需要注意的是,在Namenode上,该文件中的节点必须使用IP,使用主机名无效,而Jobtracker上,该文件中的节点必须使用主机名,使用IP无效,所以,最好ip和主机名都配上。
这样配置后,namenode启动时候日志是这样的:
2013-09-23 17:16:27,272 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /dc1/rack3/ 192.168.147.94:50010
说明hadoop的机架感知已经被启用了。
查看HADOOP机架信息命令:
./hadoop dfsadmin -printTopology
Rack: /dc1/rack1
192.168.147.91:50010 (tbe192168147091)
192.168.147.92:50010 (tbe192168147092)
Rack: /dc1/rack2
192.168.147.93:50010 (tbe192168147093)
Rack: /dc1/rack3
192.168.147.94:50010 (tbe192168147094)
192.168.147.95:50010 (tbe192168147095)
192.168.147.96:50010 (tbe192168147096)
- 增加数据节点,不重启NameNode
假设Hadoop集群在192.168.147.68上部署了NameNode和DataNode,启用了机架感知,执行bin/hadoop dfsadmin -printTopology看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
现在想增加一个物理位置在rack2的数据节点192.168.147.69到集群中,不重启NameNode。
首先,修改NameNode节点的topology.data的配置,加入:192.168.147.69 dbj69 /dc1/rack2,保存。
192.168.147.68 dbj68 /dc1/rack1
192.168.147.69 dbj69 /dc1/rack2
然后,sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,任意节点执行bin/hadoop dfsadmin -printTopology 看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
Rack: /dc1/rack2
192.168.147.69:50010 (dbj69)
说明hadoop已经感知到了新加入的节点dbj69。
注意:如果不将dbj69的配置加入到topology.data中,执行sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,datanode日志中会有异常发生,导致dbj69启动不成功。
2013-11-21 10:51:33,502 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool BP-1732631201-192.168.147.68-1385000665316 (storage id DS-878525145-192.168.147.69-50010-1385002292231) service to dbj68/192.168.147.68:9000
org.apache.hadoop.ipc.RemoteException(org.apache.hadoop.net.NetworkTopology$InvalidTopologyException): Invalid network topology. You cannot have a rack and a non-rack node at the same level of the network topology.
at org.apache.hadoop.net.NetworkTopology.add(NetworkTopology.java:382)
at org.apache.hadoop.hdfs.server.blockmanagement.DatanodeManager.registerDatanode(DatanodeManager.java:746)
at org.apache.hadoop.hdfs.server.namenode.FSNamesystem.registerDatanode(FSNamesystem.java:3498)
at org.apache.hadoop.hdfs.server.namenode.NameNodeRpcServer.registerDatanode(NameNodeRpcServer.java:876)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolServerSideTranslatorPB.registerDatanode(DatanodeProtocolServerSideTranslatorPB.java:91)
at org.apache.hadoop.hdfs.protocol.proto.DatanodeProtocolProtos$DatanodeProtocolService$2.callBlockingMethod(DatanodeProtocolProtos.java:20018)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Server$ProtoBufRpcInvoker.call(ProtobufRpcEngine.java:453)
at org.apache.hadoop.ipc.RPC$Server.call(RPC.java:1002)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1701)
at org.apache.hadoop.ipc.Server$Handler$1.run(Server.java:1697)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1408)
at org.apache.hadoop.ipc.Server$Handler.run(Server.java:1695)
at org.apache.hadoop.ipc.Client.call(Client.java:1231)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:202)
at $Proxy10.registerDatanode(Unknown Source)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:601)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invokeMethod(RetryInvocationHandler.java:164)
at org.apache.hadoop.io.retry.RetryInvocationHandler.invoke(RetryInvocationHandler.java:83)
at $Proxy10.registerDatanode(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.DatanodeProtocolClientSideTranslatorPB.registerDatanode(DatanodeProtocolClientSideTranslatorPB.java:149)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.register(BPServiceActor.java:619)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.connectToNNAndHandshake(BPServiceActor.java:221)
at org.apache.hadoop.hdfs.server.datanode.BPServiceActor.run(BPServiceActor.java:660)
at java.lang.Thread.run(Thread.java:722)
- 节点间距离计算
有了机架感知,NameNode就可以画出下图所示的datanode网络拓扑图。D1,R1都是交换机,最底层是datanode。则H1的rackid=/D1/R1/H1,H1的parent是R1,R1的是D1。这些rackid信息可以通过topology.script.file.name配置。有了这些rackid信息就可以计算出任意两台datanode之间的距离,得到最优的存放策略,优化整个集群的网络带宽均衡以及数据最优分配。
distance(/D1/R1/H1,/D1/R1/H1)=0 相同的datanode
distance(/D1/R1/H1,/D1/R1/H2)=2 同一rack下的不同datanode
distance(/D1/R1/H1,/D1/R2/H4)=4 同一IDC下的不同datanode
distance(/D1/R1/H1,/D2/R3/H7)=6 不同IDC下的datanode
datanode节点超时时间设置
hadoop datanode节点超时时间设置
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
hdfs-site.xml中的参数设置格式:
<property>
<name>heartbeat.recheck.interval</name>
<value>2000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>1</value>
</property>
hadoop安装部署问题
hadoop的日志目录(/home/hadoop/app/hadoop-2.6.4/logs)
hadoop启动不正常
用浏览器访问namenode的50070端口,不正常,需要诊断问题出在哪里:
a、在服务器的终端命令行使用jps查看相关进程
(namenode1个节点 datanode3个节点 secondary namenode1个节点)
b、如果已经知道了启动失败的服务进程,进入到相关进程的日志目录下,查看日志,分析异常的原因
1)配置文件出错,saxparser exception; ——找到错误提示中所指出的配置文件检查修改即可
2)unknown host——主机名不认识,配置/etc/hosts文件即可,或者是配置文件中所用主机名跟实际不一致
(注:在配置文件中,统一使用主机名,而不要用ip地址)
3)directory 访问异常—— 检查namenode的工作目录,看权限是否正常
start-dfs.sh启动后,发现有datanode启动不正常
a)查看datanode的日志,看是否有异常,如果没有异常,手动将datanode启动起来
sbin/hadoop-daemon.sh start datanode
b)很有可能是slaves文件中就没有列出需要启动的datanode
c)排除上述两种情况后,基本上,能在日志中看到异常信息:
1、配置文件
2、ssh免密登陆没有配置好
3、datanode的身份标识跟namenode的集群身份标识不一致(删掉datanode的工作目录)
HDFS冗余数据块的自动删除
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝;当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,所以造成了HDFS上某些block的备份数超过了设定的备份数。通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,那么这个时间取决于什么呢?
该时间的长短跟数据块报告的间隔时间有关。Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。
hdfs-site.xml文件中有一个参数:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>3600000</value>
<description>Determines block reporting interval in milliseconds.</description>
</property>
其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
当namenode发现集群中的block丢失数量达到一个阀值时,namenode就进入安全模式状态,不再接受客户端的数据更新请求
namenode安全模式
在正常情况下,namenode也有可能进入安全模式:
集群启动时(namenode启动时)必定会进入安全模式,然后过一段时间会自动退出安全模式(原因是datanode汇报的过程有一段持续时间)
也确实有异常情况下导致的安全模式
原因:block确实有缺失
措施:可以手动让namenode退出安全模式,bin/hdfs dfsadmin -safemode leave
或者:调整safemode门限值: dfs.safemode.threshold.pct=0.999f
安全模式下不能执行重要操作(写操作).集群启动完成后,自动退出安全模式
查看安全模式
hdfs dfsadmin -safemode get
进入安全模式状态
hdfs dfsadmin -safemode enter
离开安全模式状态
hdfs dfsadmin -safemode leave
等待安全模式状态
hdfs dfsadmin -safemode wait
ntp时间服务同步
第一种方式:同步到网络时间服务器
# ntpdate time.windows.com
将硬件时间设置为当前系统时间。
#hwclock –w
加入crontab:
30 8 * * * root /usr/sbin/ntpdate 192.168.0.1; /sbin/hwclock -w每天的8:30将进行一次时间同步。
重启crond服务:
service crond restart
第二种方式:同步到局域网内部的一台时间同步服务器
一、搭建时间同步服务器
1、编译安装ntp server
rpm -qa | grep ntp
若没有找到,则说明没有安装ntp包,从光盘上找到ntp包,使用
rpm -Uvh ntp***.rpm
进行安装
2、修改ntp.conf配置文件
vi /etc/ntp.conf
①、第一种配置:允许任何IP的客户机都可以进行时间同步
将“restrict default nomodify notrap noquery”这行修改成:
restrict default nomodify notrap
配置文件示例:/etc/ntp.conf
②、第二种配置:只允许192.168.211.***网段的客户机进行时间同步
在restrict default nomodify notrap noquery(表示默认拒绝所有IP的时间同步)之后增加一行:
restrict 192.168.211.0 mask 255.255.255.0 nomodify notrap
3、启动ntp服务
service ntpd start
开机启动服务
chkconfig ntpd on
4、ntpd启动后,客户机要等几分钟再与其进行时间同步,否则会提示“no server suitable for synchronization found”错误。
二、配置时间同步客户机
手工执行ntpdate <ntp server>来同步
或者利用crontab来执行
crontab -e
0 21 * * * ntpdate 192.168.211.22 >> /root/ntpdate.log 2>&1
每天晚上9点进行同步
附:
当用ntpdate -d 来查询时会发现导致 no server suitable for synchronization found 的错误的信息有以下2个:
错误1.Server dropped: Strata too high
在ntp客户端运行ntpdate serverIP,出现no server suitable for synchronization found的错误。
在ntp客户端用ntpdate –d serverIP查看,发现有“Server dropped: strata too high”的错误,并且显示“stratum 16”。而正常情况下stratum这个值得范围是“0~15”。
这是因为NTP server还没有和其自身或者它的server同步上。
以下的定义是让NTP Server和其自身保持同步,如果在/ntp.conf中定义的server都不可用时,将使用local时间作为ntp服务提供给ntp客户端。
server 127.127.1.0
fudge 127.127.1.0 stratum 8
在ntp server上重新启动ntp服务后,ntp server自身或者与其server的同步的需要一个时间段,这个过程可能是5分钟,在这个时间之内在客户端运行ntpdate命令时会产生no server suitable for synchronization found的错误。
那么如何知道何时ntp server完成了和自身同步的过程呢?
在ntp server上使用命令:
# watch ntpq -p
出现画面:
Every 2.0s: ntpq -p Thu Jul 10 02:28:32 2008
remote refid st t when poll reach delay offset jitter
==============================================================================
192.168.30.22 LOCAL(0) 8 u 22 64 1 2.113 179133. 0.001
LOCAL(0) LOCAL(0) 10 l 21 64 1 0.000 0.000 0.001
注意LOCAL的这个就是与自身同步的ntp server。
注意reach这个值,在启动ntp server服务后,这个值就从0开始不断增加,当增加到17的时候,从0到17是5次的变更,每一次是poll的值的秒数,是64秒*5=320秒的时间。
如果之后从ntp客户端同步ntp server还失败的话,用ntpdate –d来查询详细错误信息,再做判断。
错误2.Server dropped: no data
从客户端执行netdate –d时有错误信息如下:
transmit(192.168.30.22) transmit(192.168.30.22)
transmit(192.168.30.22)
transmit(192.168.30.22)
transmit(192.168.30.22)
192.168.30.22: Server dropped: no data
server 192.168.30.22, port 123
.....
28 Jul 17:42:24 ntpdate[14148]: no server suitable for synchronization found出现这个问题的原因可能有2:
- 检查ntp的版本,如果你使用的是ntp4.2(包括4.2)之后的版本,在restrict的定义中使用了notrust的话,会导致以上错误。
使用以下命令检查ntp的版本:
# ntpq -c version
下面是来自ntp官方网站的说明:
The behavior of notrust changed between versions 4.1 and 4.2.
In 4.1 (and earlier) notrust meant "Don't trust this host/subnet for time".
In 4.2 (and later) notrust means "Ignore all NTP packets that are not cryptographically authenticated." This forces remote time servers to authenticate themselves to your (client) ntpd
解决:
把notrust去掉。
- 检查ntp server的防火墙。可能是server的防火墙屏蔽了upd 123端口。
可以用命令
#service iptables stop
来关掉iptables服务后再尝试从ntp客户端的同步,如果成功,证明是防火墙的问题,需要更改iptables的设置。
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set.的问题
来自https://www.cnblogs.com/huxinga/p/6875929.html
报错如下:
300 [main] DEBUG org.apache.hadoop.util.Shell - Failed to detect a valid hadoop home directory
java.io.IOException: HADOOP_HOME or hadoop.home.dir are not set
解决办法一:
根据 http://blog.csdn.net/baidu_19473529/article/details/54693523 配置hadoop_home变量
下载winutils地址https://github.com/srccodes/hadoop-common-2.2.0-bin下载解压
依然报相同的错误
解决办法二:
在java程序中加入
System.setProperty("hadoop.home.dir", "/usr/local/hadoop-2.6.0");
依然报错
解决办法三:
根据该提示:
依然报错
今天早上再次执行该程序,将上传到HDFS部分的代码给注释掉后发现日志报错信息如下:
132 [main] DEBUG org.apache.hadoop.util.NativeCodeLoader - Trying to load the custom-built native-hadoop library...
134 [main] DEBUG org.apache.hadoop.util.NativeCodeLoader - Failed to load native-hadoop with error: java.lang.UnsatisfiedLinkError: no hadoop in java.library.path
1)check Hadoop library:
root@Ubuntu-1:/usr/local/hadoop-2.6.0/lib/native# file libhadoop.so.1.0.0
It's 64-bite library
2)Try adding the HADOOP_OPTS environment variable:
root@Ubuntu-1:~# vi /etc/profile //environment variable
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/native/"
It doesn't work, and reports the same error.
3)Try adding the HADOOP_OPTS and HADOOP_COMMON_LIB_NATIVE_DIR environment variable:
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_HOME}/lib/native
export HADOOP_OPTS="-Djava.library.path=${HADOOP_HOME}/lib/"
It still doesn't work, and reports the same error.
4)Adding the Hadoop library into LD_LIBRARY_PATH
root@Ubuntu-1:~# vi .bashrc
export LD_LIBRARY_PATH=/usr/local/hadoop/lib/native/:$LD_LIBRARY_PATH
It doesn't work, and reports the same error.
5)append word native to HADOOP_OPTS like this
export HADOOP_OPTS="$HADOOP_OPTS -Djava.library.path=$HADOOP_HOME/lib/native"
It doesn't work, and reports the same error.
win下依旧无法使用java代码上传文件到HDFS
copy了一份hadoop-2.6.0文件到本机,更改bin目录和path ,显示无效的path,遂更改回去
今天早上开机 试了一下 发现它已经好了 其实上述的设置已经可以解决大部分遇到这类问题的人群

若有收获,就点个赞吧
0 人点赞
