简单的说一下MyBatis的一级缓存和二级缓存?
Mybatis首先去缓存中查询结果集,如果没有则查询数据库,如果有则从缓存取出返回结果集就不走数据库。Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句。value为从查询出来映射生成的java对象
Mybatis的二级缓存即查询缓存,它的作用域是一个mapper的namespace,即在同一个namespace中查询sql可以从缓存中获取数据。二级缓存是可以跨SqlSession的。
详细描述
缓存概念
什么是缓存:内存中的临时数据
为什么用缓存:如果缓存中有数据就不用从数据库中获取,大大提高系统性能(主要是减少和数据库交互的次数,减少数据库的压力,提高执行效率)
Mybatis的缓存
MyBatis的缓存分为一级缓存和 二级缓存。
一级缓存是SqlSession级别的缓存,默认开启。
二级缓存是NameSpace级别(Mapper)的缓存,多个SqlSession可以共享,使用时需要进行配置开启。
Mybatis首先去缓存中查询结果集,如果没有则查询数据库,如果有则从缓存取出返回结果集就不走数据库。Mybatis内部存储缓存使用一个HashMap,key为hashCode+sqlId+Sql语句。value为从查询出来映射生成的java对象
Mybatis的二级缓存即查询缓存,它的作用域是一个mapper的namespace,即在同一个namespace中查询sql可以从缓存中获取数据。二级缓存是可以跨SqlSession的。
1)一级缓存: 基于 PerpetualCache 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
2)二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置
3)对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
缓存的查找顺序
开启二级缓存的数据查找顺序: 二级缓存 —> 一级缓存—>数据库
Mybatis查询数据时,会先查询二级缓存,再查询一级缓存,然后再查询数据库。
什么样的数据适用于缓存,什么样的数据不适用:
适用的:
经常查询,且不经常改变的。同时缓存数据的正确与否对最终结果影响不大的。
不适用的:
经常修改的以及敏感数据。
敏感数据:数据的正确与否对最终结果影响很大。
例如:股市牌价,银行的汇率,商品的库存等等。
一级缓存
| 案例:ZJJMybatis_2019/09/30 4:20:05_6m00g |
|---|
一级缓存默认会启用,想要关闭一级缓存可以在select标签上配置flushCache=“true”;一级缓存存在于 SqlSession 的生命周期中,在同一个 SqlSession 中查询时, MyBatis 会把执行的方法和参数通过算法生成缓存的键值,将键值和查询结果存入一个 Map对象中。如果同一个 SqlSession 中执行的方法和参数完全一致,那么通过算法会生成相同的键值,当 Map 缓存对象中己经存在该键值时,则会返回缓存中的对象;任何的 INSERT 、UPDATE 、 DELETE 操作都会清空一级缓存;
一级缓存只存在当前线程,当前线程没了,一级缓存也就没了
ü 工作流程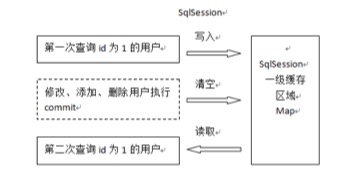
从图中可以看出:第一次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,如果没有,从数据库查询用户信息。得到用户信息,将用户信息存储到一级缓存中。
如果中间sqlSession去执行commit操作(执行插入、更新、删除),则会清空SqlSession中的一级缓存,这样做的目的为了让缓存中存储的是最新的信息,避免脏读。
第二次发起查询用户id为1的用户信息,先去找缓存中是否有id为1的用户信息,缓存中有,直接从缓存中获取用户信息。
二级缓存
会有脏数据
| 案例:ZJJMybatis_2019/09/30 4:30:59_hkdk5 |
|---|
二级缓存也叫应用缓存,存在于 SqlSessionFactory 的生命周期中,SqlSessionFactory生命周期是只要Mybatis还启动着,SqlSessionFactory就一直存在内存里面,所以二级缓存是一个常驻内存的一个缓存数据.
可以理解为跨sqlSession;缓存是以namespace为单位的,不同namespace下的操作互不影响。假如项目有八个Mapper.xml文件,那么这个项目最多有八个二级缓存的块儿.每个namespace专门存自己业务相关的二级缓存数据.
在MyBatis的核心配置文件中 cacheEnabled参数是二级缓存的全局开关,默认值是 true,如果把这个参数设置为 false,即使有后面的二级缓存配置,也不会生效;
ü 开启二级缓存
在当前的Mapper.xml加上<cache></cache>就说明开启了二级缓存
要开启二级缓存,你需要在你的 SQL Mapper文件中添加配置:
<cache eviction=“LRU” flushInterval=”60000” size=”512” readOnly=”true”/>
参数1 缓存的清空策略,
参数2多长时间之后会把缓存清空掉,
参数3,我的缓存里面只是允许有512个对象,如果对象超过了512就会使用参数1的缓存清空策略
参数4 我的缓存只可读
这段配置的效果如下:
ü 映射语句文件中的所有 select 语句将会被缓存。
ü 映射语句文件中的所有 insert,update 和 delete 语句会刷新缓存。
ü 缓存会使用 Least Recently Used(LRU,最近最少使用的)算法来收回。
ü 根据时间表(比如 no Flush Interval,没有刷新间隔), 缓存不会以任何时间顺序 来刷新。
ü 缓存会存储列表集合或对象(无论查询方法返回什么)的 512个引用。
ü 缓存会被视为是 read/write(可读/可写)的缓存;
1.二级缓存脏读原因
二级缓存的作用范围为SqlSessionFactory,映射语句文件中的所有select语句都会被缓存,所有CRUD的操作都会刷新缓存,缓存会存储1024个对象,缓存容易造成脏读数据,影响真实数据的准确性,而且Key是程序员无法修改的,实际开发业务中会放弃二级缓存。
假如有两个namespace ,namespace A 和namespace B ,此时 A和 B查询的都是同样的sql,结果也是一样的,都放入自己的二级缓存区域,此时namespace A 进行了增删改操作了, 操作完毕会清空自己的二级缓存区域(为了防止脏数据),但是不会清空namespace B 的二级缓存区域(因为二级缓存是namespace为单位的存放),此时namespace B的二级缓存就是脏数据了.
2.二级缓存工作原理
它是mybatis中SqlSessionFactory对象的缓存。它里面存的不再是对象,而是对象的内容(数据)
User{id:41,username:aaa,sex:男…}
由同一个工厂生产的SqlSession共享二级缓存的内容
ü 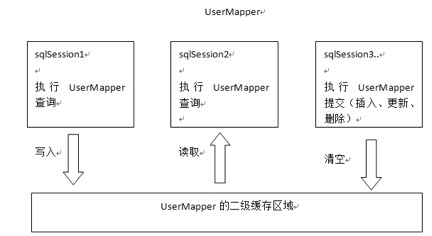
首先开启mybatis的二级缓存。
sqlSession1去查询用户id为1的用户信息,查询到用户信息会将查询数据存储到二级缓存中。
如果SqlSession3去执行相同 mapper下sql,执行commit提交,清空该 mapper下的二级缓存区域的数据。
sqlSession2去查询用户id为1的用户信息,去缓存中找是否存在数据,如果存在直接从缓存中取出数据。
二级缓存与一级缓存区别,二级缓存的范围更大,多个sqlSession可以共享一个UserMapper的二级缓存区域。
UserMapper有一个二级缓存区域(按namespace分) ,其它mapper也有自己的二级缓存区域(按namespace分)。
每一个namespace的mapper都有一个二缓存区域,两个mapper的namespace如果相同,这两个mapper执行sql查询到数据将存在相同的二级缓存区域中.
3.redis实现二级缓存
需要在有redis环境下来实现
<dependency>
<groupId>org.mybatis.caches</groupId>
<artifactId>mybatis-redis</artifactId>
<version>1.0.0-beta2</version>
</dependency>
配置文件,注意,必须放到resources根目录下面,不能挪地方,同时里面属性的key不能修改名字,不然mybatis-redis 无法读取到redis配置信息就会报错.
那个xml需要使用二级缓存就在哪个xml里面配置cache标签
需要注意,实体类必须要实现序列化接口
需要注意脏数据问题 ,
解决办法:所有增删改都需要手动清空二级缓存,flushCache=”true”
<insert id=”bbb” parameterType=”com.lanmili.pojo.SysUser” flushCache=”true” >
insert into sys_user (id,user_name) values (#{id},#{user_name})
</insert>
4.使用场景
可以在字典表里面去使用,只要保证这个数据源只有这一个NameSpace的xml里面操作就行了..这样就不会出现脏数据问题.
cache 标签的属性
<cacheeviction="FIFO" // 回收策略为先进先出flushInterval="60000" // 自动刷新时间60ssize="512" // 最多缓存512个引用对象readOnly="true"/> // 只读
cache 标签可指定如下属性,每种属性的指定都是针对都是针对底层Cache的一种装饰,采用的是装饰器的模式。
- blocking:默认为false,当指定为true时将采用BlockingCache进行封装,blocking,阻塞的意思。
使用BlockingCache会在查询缓存时锁住对应的Key,如果缓存命中了则会释放对应的锁,否则会在查询数据库以后再释放锁,这样可以阻止并发情况下多个线程同时查询数据,详情可参考BlockingCache的源码。
简单理解,也就是设置true时,在进行增删改之后的并发查询,只会有一条去数据库查询,而不会并发。
- eviction:eviction 就是 驱逐的意思,也就是元素驱逐算法,默认是LRU。
LRU 对应的就是LruCache,其默认只保存1024个Key,超出时按照最近最少使用算法进行驱逐,详情请参考LruCache的源码。
如果想使用自己的算法,则可以将该值指定为自己的驱逐算法实现类,只需要自己的类实现Mybatis的Cache接口即可。
除了LRU以外,系统还提供:
- FIFO(先进先出,对应FifoCache)
- SOFT(采用软引用存储Value,便于垃圾回收,对应SoftCache)
WEAK(采用弱引用存储Value,便于垃圾回收,对应WeakCache)这三种策略。
这里,根据个人需求选择了,没什么要求的话,默认的LRU即可。
- flushInterval:清空缓存的时间间隔,单位是毫秒,默认是不会清空的。
当指定了该值时会再用ScheduleCache包装一次,其会在每次对缓存进行操作时判断距离最近一次清空缓存的时间是否超过了flushInterval指定的时间,如果超出了,则清空当前的缓存,详情可参考ScheduleCache的实现。
- readOnly:是否只读 。默认为false。
当指定为false时,底层会用SerializedCache包装一次,其会在写缓存的时候将缓存对象进行序列化,然后在读缓存的时候进行反序列化,这样每次读到的都将是一个新的对象,即使你更改了读取到的结果,也不会影响原来缓存的对象,即非只读,你每次拿到这个缓存结果都可以进行修改,而不会影响原来的缓存结果;
当指定为true时,那就是每次获取的都是同一个引用,对其修改会影响后续的缓存数据获取,这种情况下是不建议对获取到的缓存结果进行更改,意为只读。 (不建议设置为true)这是Mybatis二级缓存读写和只读的定义,可能与我们通常情况下的只读和读写意义有点不同。每次都进行序列化和反序列化无疑会影响性能,但是这样的缓存结果更安全,不会被随意更改,具体可根据实际情况进行选择。详情可参考SerializedCache的源码。
- size:用来指定缓存中最多保存的Key的数量。
其是针对LruCache而言的,LruCache默认只存储最多1024个Key,可通过该属性来改变默认值,当然,如果你通过eviction指定了自己的驱逐算法,同时自己的实现里面也有setSize方法,那么也可以通过cache的size属性给自定义的驱逐算法里面的size赋值。
- type:指定当前底层缓存实现类,默认是PerpetualCache。
如果我们想使用自定义的Cache,则可以通过该属性来指定,对应的值是我们自定义的Cache的全路径名称
cache-ref 标签
<cache-ref namespace="cn.chenhaoxiang.dao.UserMapper"/>
cache-ref 可以用来指定其它 Mapper.xml 中定义的Cache,有的时候可能我们多个不同的 Mapper 需要共享同一个缓存的是希望在MapperA中缓存的内容在MapperB中可以直接命中的,这个时候我们就可以考虑使用cache-
ref,这种场景只需要保证它们的缓存的Key是一致的即可命中,二级缓存的Key是通过Executor接口的createCacheKey()方法生成的,其实现基本都是BaseExecutor.
总结
对于查询多、commit少且用户对查询结果实时性要求不高,此时采用 mybatis 二级缓存技术降低数据库访问量,提高访问速度。
但不能滥用二级缓存,二级缓存也有很多弊端,从MyBatis默认二级缓存是关闭的就可以看出来。
二级缓存是建立在同一个 namespace下的,如果对表的操作查询可能有多个 namespace,那么得到的数据就是错误的。
举个简单的例子:
订单 和 订单详情 分别是 orderMapper、orderDetailMapper。
在查询订单详情(orderDetailMapper)时,我们需要把订单信息(orderMapper)也查询出来,那么这个订单详情(orderDetailMapper)的信息被二级缓存在 orderDetailMapper 的 namespace中,这个时候有人要修改订单的基本信息(orderMapper),那就是在 orderMapper 的 namespace 下修改,他是不会影响到 orderDetailMapper 的缓存的,那么你再次查找订单详情时,拿到的是缓存的数据,这个数据其实已经是过时的。
二级缓存的使用原则
只能在一个命名空间下使用二级缓存
由于二级缓存中的数据是基于namespace的,即不同 namespace 中的数据互不干扰。
在多个namespace中存在对同一个表的操作,那么这多个namespace中的数据可能就会出现不一致现象。在单表上使用二级缓存
如果一个表与其它表有关联关系,那么就非常有可能存在多个 namespace 对同一数据的操作。
而不同 namespace 中的数据相互干扰,所以就有可能出现多个 namespace 中的数据不一致现象。查询多于修改时使用二级缓存
在查询操作远远多于增删改操作的情况下可以使用二级缓存。因为任何增删改操作都将刷新二级缓存,对二级缓存的频繁刷新将降低系统性能。

若有收获,就点个赞吧
0 人点赞
