前言
MyBatis 可能很多人都一直在用,但是 MyBatis 的 SQL 执行流程可能并不是所有人都清楚了,那么既然进来了,通读本文你将收获如下:
- 1、Mapper 接口和映射文件是如何进行绑定的
- 2、MyBatis 中 SQL 语句的执行流程
- 3、自定义 MyBatis 中的参数设置处理器 typeHandler
- 4、自定义 MyBatis 中结果集处理器 typeHandler
PS:本文基于 MyBatis3.5.5 版本源码。
概要
在 MyBatis 中,利用编程式进行数据查询,主要就是下面几行代码:
SqlSession session = sqlSessionFactory.openSession();UserMapper userMapper = session.getMapper(UserMapper.class);List<LwUser> userList = userMapper.listUserByUserName("孤狼1号");
第一行是获取一个 SqlSession 对象在上一篇文章分析过了,想要详细了解的可以点击这里,第二行就是获取 UserMapper 接口,第三行一行代码就实现了整个查询语句的流程,接下来我们就来仔细分析一下第二和第三步。
获取 Mapper 接口 (getMapper)
第二步是通过 SqlSession 对象是获取一个 Mapper 接口,这个流程还是相对简单的,下面就是我们调用 session.getMapper 方法之后的运行时序图:
1、在调用 getMapper 之后,会去 Configuration 对象中获取 Mapper 对象,因为在项目启动的时候就会把 Mapper 接口加载并解析存储到 Configuration 对象
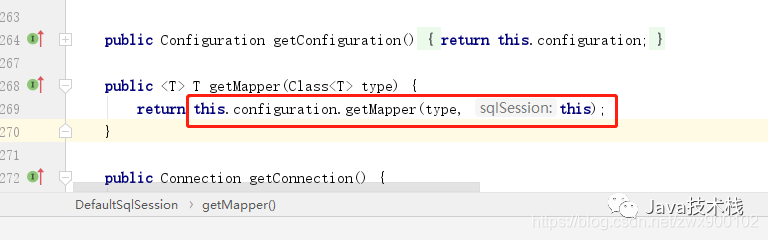
图片
2、通过 Configuration 对象中的 MapperRegistry 对象属性,继续调用 getMapper 方法
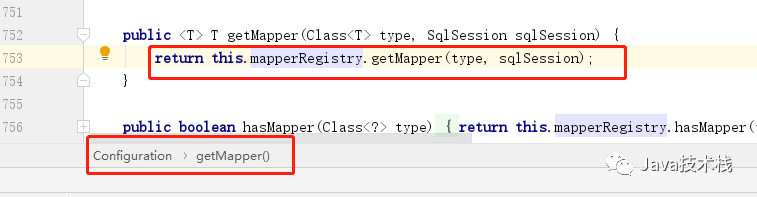
图片
3、根据 type 类型,从 MapperRegistry 对象中的 knownMappers 获取到当前类型对应的代理工厂类,然后通过代理工厂类生成对应 Mapper 的代理类
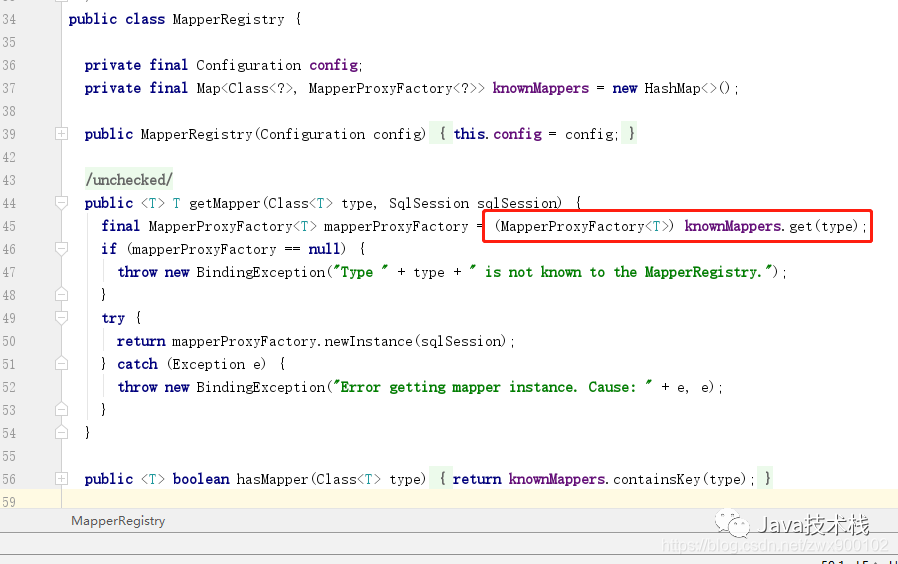
图片
4、最终获取到我们接口对应的代理类 MapperProxy 对象

图片
而 MapperProxy 可以看到实现了 InvocationHandler,使用的就是 JDK 动态代理。
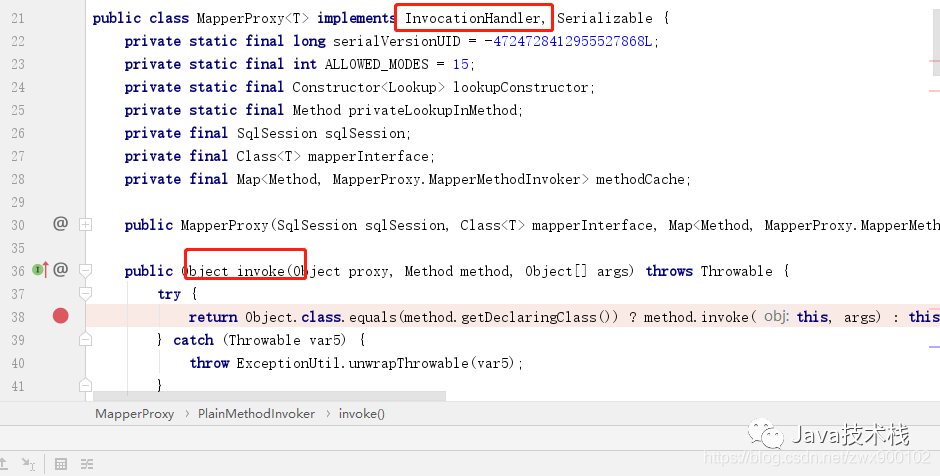
图片
至此获取 Mapper 流程结束了,那么就有一个问题了 MapperRegistry 对象内的 HashMap 属性 knownMappers 中的数据是什么时候存进去的呢?
Mapper 接口和映射文件是何时关联的
Mapper 接口及其映射文件是在加载 mybatis-config 配置文件的时候存储进去的,下面就是时序图:
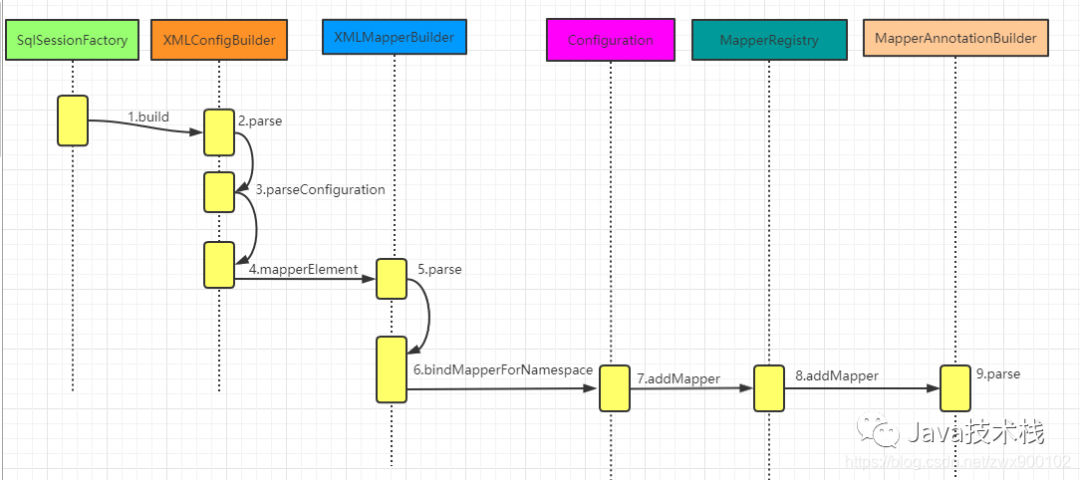
图片
1、首先我们会手动调用 SqlSessionFactoryBuilder 方法中的 build() 方法:
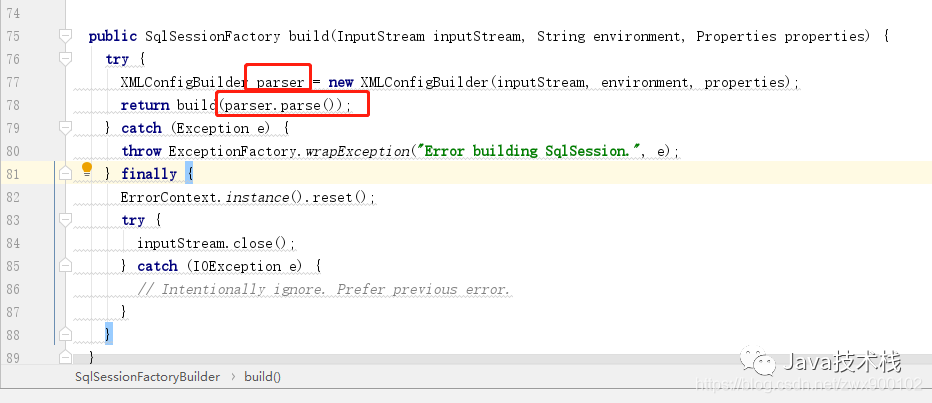
图片
2、然后会构造一个 XMLConfigBuilder 对象,并调用其 parse 方法:
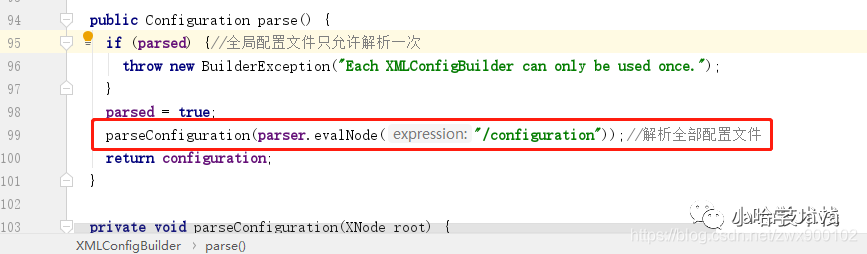
img
3、然后会继续调用自己的 parseConfiguration 来解析配置文件,这里面就会分别去解析全局配置文件的顶级节点,其他的我们先不看,我们直接看最后解析 mappers 节点
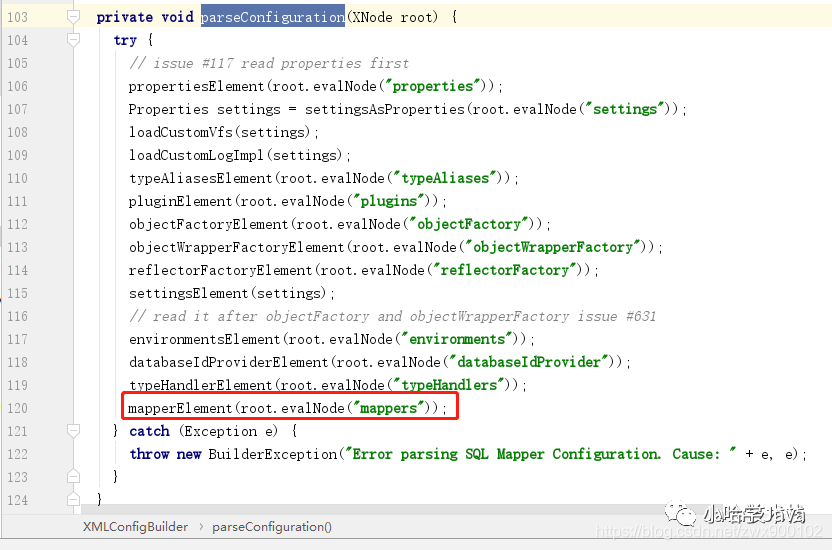
img
4、继续调用自己的 mapperElement 来解析 mappers 文件(这个方法比较长,为了方便截图完整,所以把字体缩小了 1 号),可以看到,这里面分了四种方式来解析 mappers 节点的配置,对应了「4 种 mapper 配置方式」,而其中红框内的两种方式是直接配置的 xml 映射文件,蓝框内的两种方式是解析直接配置 Mapper 接口的方式,从这里也可以说明,「不论配置哪种方式,最终 MyBatis 都会将 xml 映射文件和 Mapper 接口进行关联」。
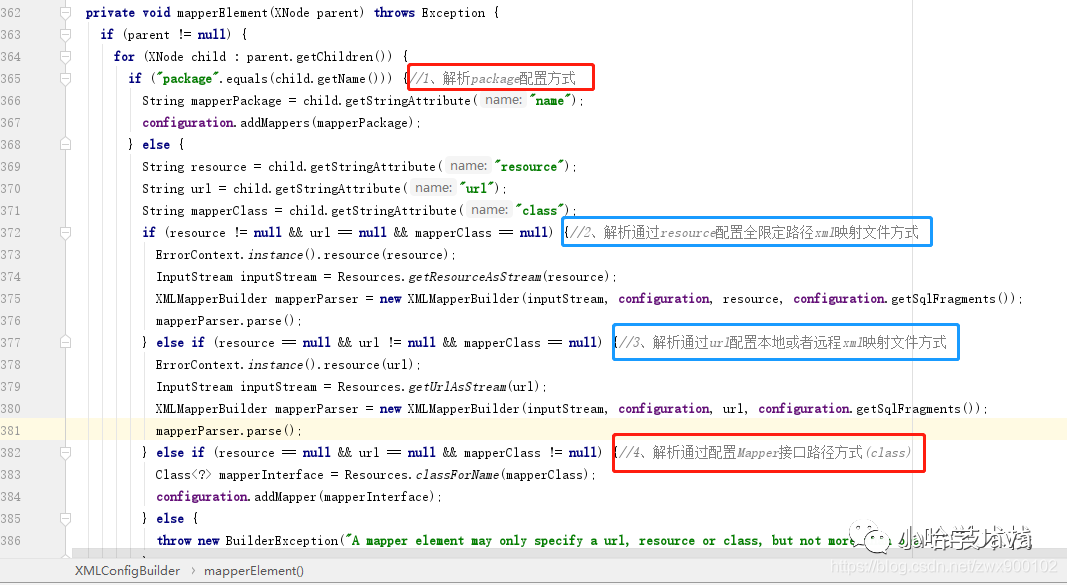
img
5、我们先看第 2 种和第 3 中(直接配置 xml 映射文件的解析方式),会构建一个 XMLMapperBuilder 对象并调用其 parse 方法。
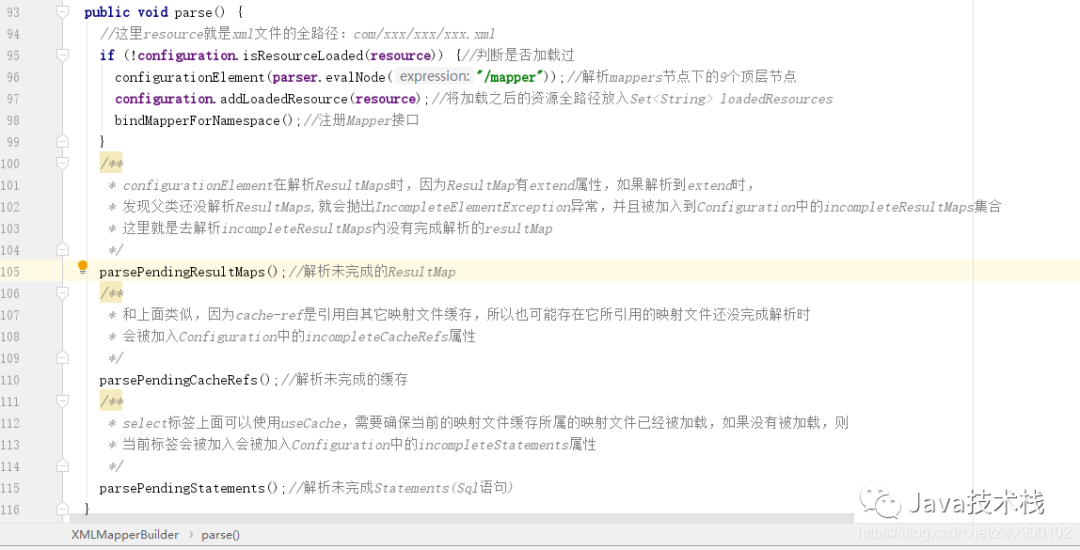
但是这里有一个问题,如果有多重继承或者多重依赖时在这里是可能会无法被完全解析的,比如说三个映射文件互相依赖,那么 if 里面 (假设是最坏情况) 只能加载 1 个,「失败 2 个」,然后走到下面 if 之外的代码又只能加载 1 个,「还有 1 个会失败」(如下代码中,只会处理 1 次,再次失败并不会继续加入 incompleteResultMaps):
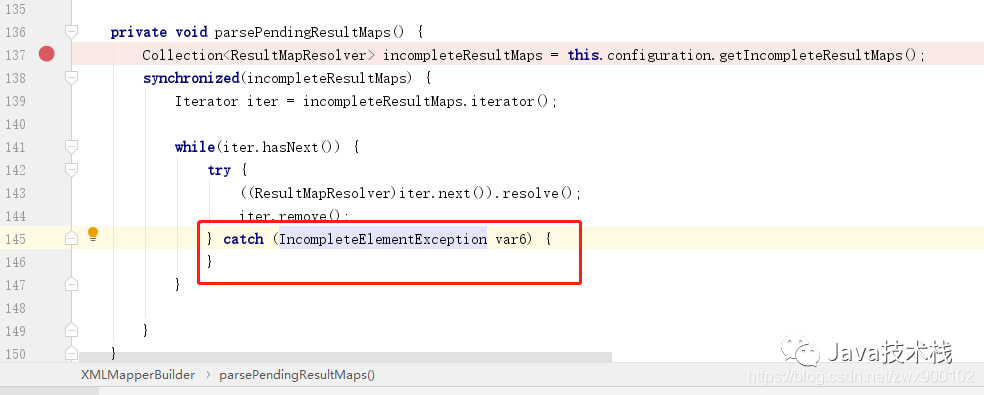
「当然,这个还是会被解析的,后面执行查询的时候会再次通过不断遍历去全部解析完毕,不过有一点需要注意的是,互相引用这种是会导致解析失败报错的,所以在开发过程中我们应该避免循环依赖的产生」。
6、解析完映射文件之后,调用自身方法 bindMapperForNamespace,开始绑定 Mapper 接口和映射文件:
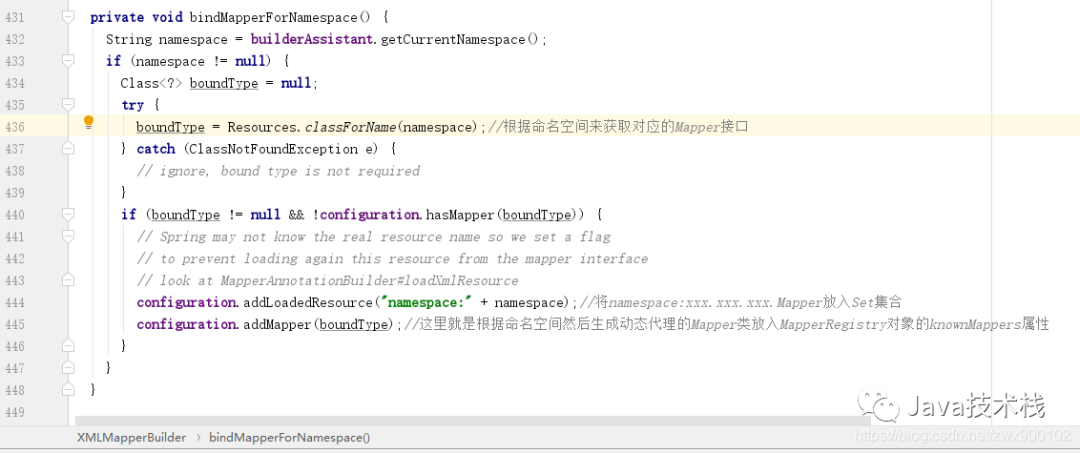
图片
7、调用 Configuration 对象的 addMapper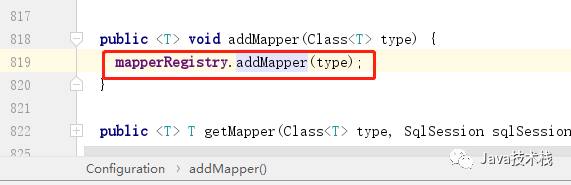
8、调用 Configuration 对象的属性 MapperRegistry 内的 addMapper 方法,这个方法就是正式将 Mapper 接口添加到 knownMappers,所以上面 getMapper 可以直接获取:
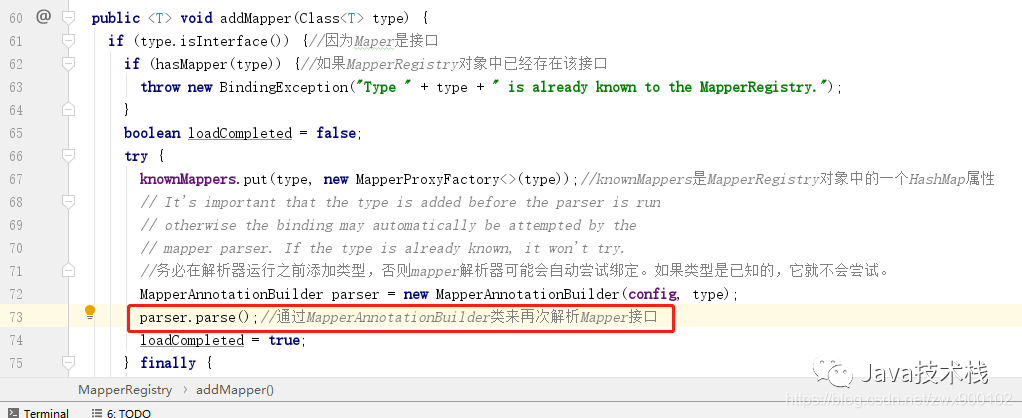
图片
到这里我们就完成了 Mapper 接口和 xml 映射文件的绑定,关注公众号 Java 技术栈获取更多 Mybatis 教程 。
9、注意上面红框里面的代码,又调用了一次 parse 方法,这个 parse 方法主要是解析注解,比如下面的语句:
@Select("select * from lw_user")List<LwUser> listAllUser();
所以这个方法里面会去解析 @Select 等注解,需要注意的是, 「parse 方法里面会同时再解析一次 xml 映射文件,因为上面我们提到了 mappers 节点有 4 种配置方式,其中两种配置的是 Mapper 接口,而配置 Mapper 接口会直接先调用 addMapper 接口,并没有解析映射文件,所以进入注解解析方法 parse 之中会需要再尝试解析一次 XML 映射文件。」
解析完成之后,还会对 Mapper 接口中的方法进行解析,并将「每个方法的全限定类名作为 key」存入存入 Configuration 中的 mappedStatements 属性。
需要指出的是,这里存储的时候,同一个 value 会存储 2 次,「一个全限定名作为 key,另一个就是只用方法名 (sql 语句的 id) 来作为 key」:

img
所以最终 mappedStatements 会是下面的情况:
事实上如果我们通过接口的方式来编程的话,最后来 getStatement 的时候,都是根据全限定名来取的,「所以即使有重名对我们也没有影响,而之所以要这么做的原因其实还是为了兼容早期版本的用法,那就是不通过接口,而是直接通过方法名的方式来进行查询」:
session.selectList("com.lonelyWolf.mybatis.mapper.UserMapper.listAllUser");
这里如果 shortName 没有重复的话,是可以直接通过简写来查询的:
session.selectList("listAllUser");
但是通过简写来查询一旦 shortName 重复了就会抛出以下异常:

img
这里的异常其实就是 StrickMap 的 get 方法抛出来的:
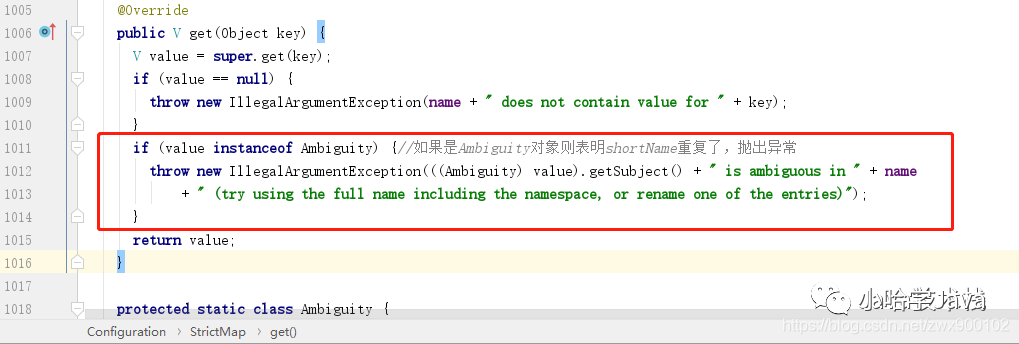
img
sql 执行流程分析
上面我们讲到了,获取到的 Mapper 接口实际上被包装成为了代理对象,所以我们执行查询语句肯定是执行的代理对象方法,接下来我们就以 Mapper 接口的代理对象 MapperProxy 来分析一下查询流程。
整个 sql 执行流程可以分为两大步骤:
- 一、寻找 sql
- 二、执行 sql 语句
寻找 sql
首先还是来看一下寻找 sql 语句的时序图:
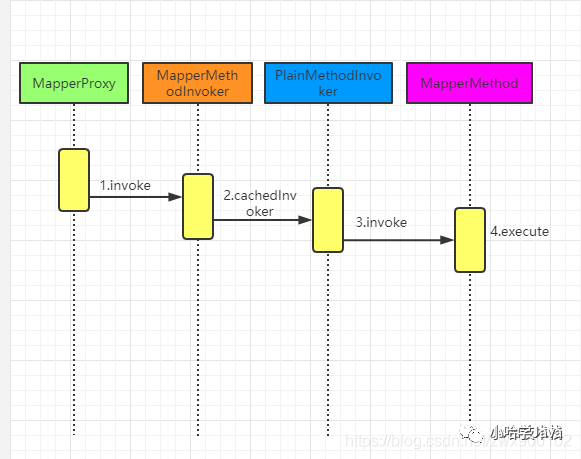
img
1、了解代理模式的应该都知道,调用被代理对象的方法之后实际上执行的就是代理对象的 invoke 方法
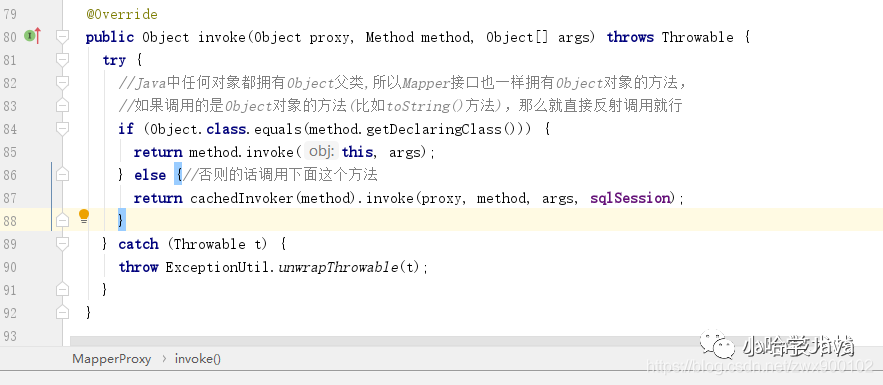
img
2、因为我们这里并没有调用 Object 类中的方法,所以肯定走的 else。else 中会继续调用 MapperProxy 内部类 MapperMethodInvoker 中的方法 cachedInvoker,这里面会有一个判断,判断一下我们是不是 default 方法,因为 Jdk1.8 中接口中可以新增 default 方法,而 default 方法是并不是一个抽象方法,所以也需要特殊处理(刚开始会从缓存里面取,缓存相关知识我们这里先不讲,后面会单独写一篇来分析一下缓存))。
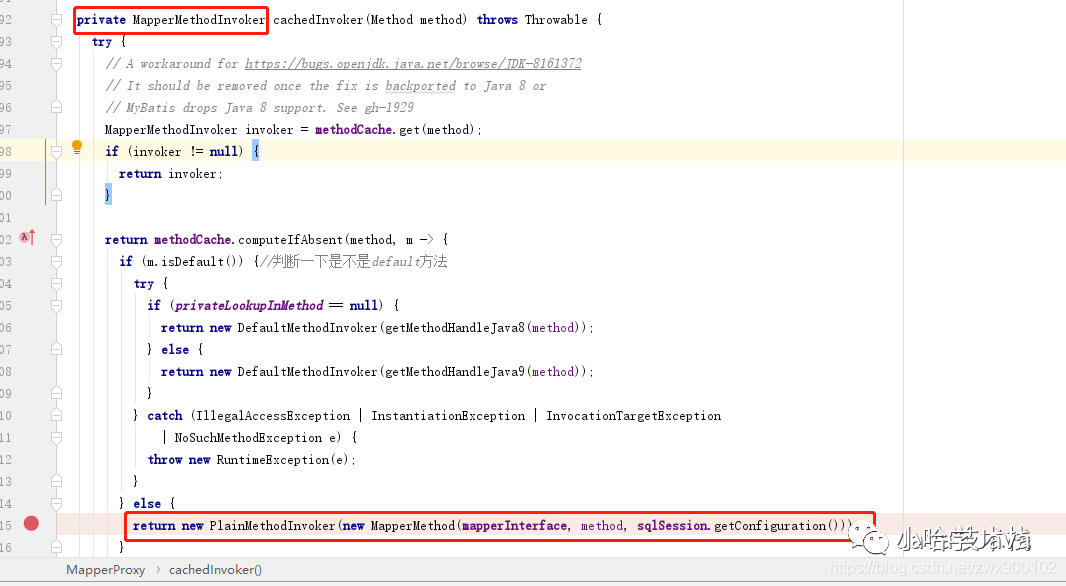
img
3、接下来,是构造一个 MapperMethod 对象, 这个对象封装了 Mapper 接口中对应的方法信息以及对应的 sql 语句信息:
这里面就会把要执行的 sql 语句,请求参数,方法返回值全部解析封装成 MapperMethod 对象,然后后面就可以开始准备执行 sql 语句了。想获取 Mybatis 系列面试题,可以关注公众号 Java 技术栈回复面试,即可获取。
执行 sql 语句
还是先来看一下执行 Sql 语句的时序图:
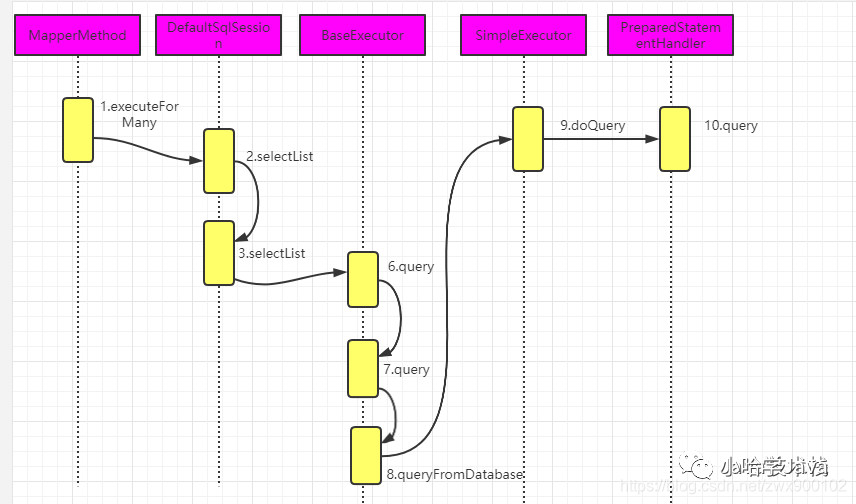
img
1、我们继续上面的流程进入 execute 方法:
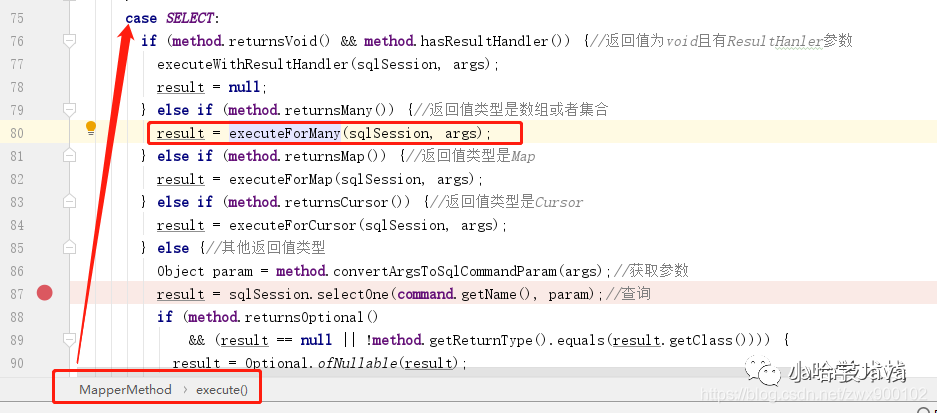
img
2、这里面会根据语句类型以及返回值类型来决定如何执行,本人这里返回的是一个集合,故而我们进入 executeForMany 方法:
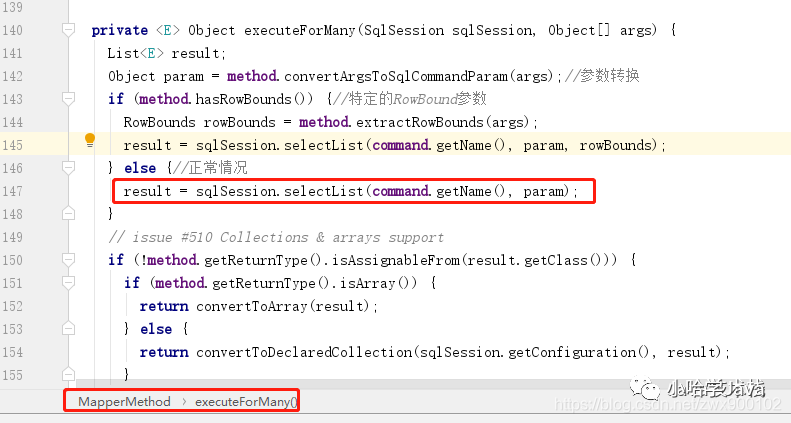
img
3、这里面首先会将前面存好的参数进行一次转换,然后绕了这么一圈,回到了起点 SqlSession 对象,继续调用 selectList 方法:
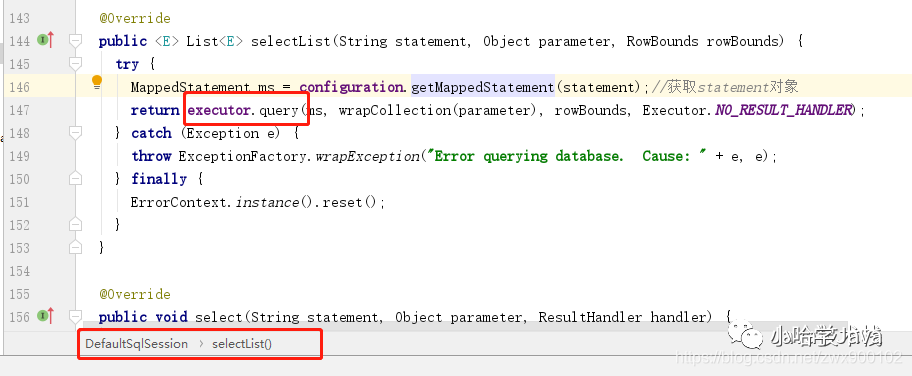
img
4、接下来又讲流程委派给了 Execute 去执行 query 方法,最终又会去调用 queryFromDatabase 方法:
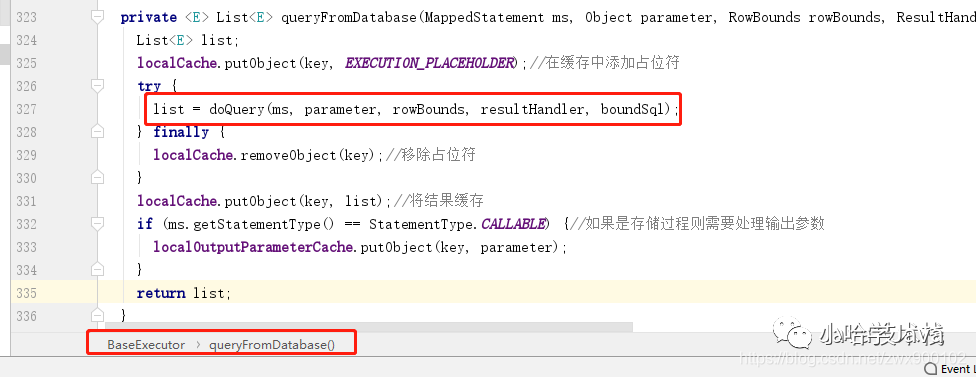
img
5、到这里之后,终于要进入正题了,一般带了这种 do 开头的方法就是真正做事的,Spring 中很多地方也是采用的这种命名方式:
注意,前面我们的 sql 语句还是占位符的方式,并没有将参数设置进去,所以这里在 return 上面一行调用 prepareStatement 方法创建 Statement 对象的时候会去设置参数,替换占位符。参数如何设置我们先跳过,等把流程执行完了我们在单独分析参数映射和结果集映射。
6、继续进入 PreparedStatementHandler 对象的 query 方法,可以看到,这一步就是调用了 jdbc 操作对象 PreparedStatement 中的 execute 方法,最后一步就是转换结果集然后返回。
到这里,整个 SQL 语句执行流程分析就结束了,中途有一些参数的存储以及转换并没有深入进去,因为参数的转换并不是核心,只要清楚整个数据的流转流程,我们自己也可以有自己的实现方式,只要存起来最后我们能重新解析读出来就行。
参数映射
现在我们来看一下上面在执行查询之前参数是如何进行设置的,我们先进入 prepareStatement 方法:
我们发现,最终是调用了 StatementHandler 中的 parameterize 进行参数设置,接下来这里为了节省篇幅,我们不会一步步点进去,直接进入设置参数的方法:
上面的 BaseTypeHandler 是一个抽象类,setNonNullParameter 并没有实现,都是交给子类去实现,而每一个子类就是对应了数据库的一种类型。
下图中就是默认的一个子类 StringTypeHandler,里面没什么其他逻辑,就是设置参数。
可以看到 String 里面调用了 jdbc 中的 setString 方法,而如果是 int 也会调用 setInt 方法。
看到这些子类如果大家之前阅读过我前面讲的 MyBatis 参数配置(关注 Java 技术栈搜索 mybatis 进行阅读)应该就很明显可以知道,这些子类就是系统默认提供的一些 typeHandler。而这些默认的 typeHandler 会默认被注册并和 Java 对象进行绑定:
正是因为 MyBatis 中默认提供了常用数据类型的映射,所以我们写 Sql 的时候才可以省略参数映射关系,可以直接采用下面的方式,系统可以根据我们参数的类型,自动选择合适的 typeHander 进行映射:
select user_id,user_name from lw_user where user_name=#{userName}
上面这条语句实际上和下面这条是等价的:
select user_id,user_name from lw_user where user_name=#{userName,jdbcType=VARCHAR}
或者说我们可以直接指定 typeHandler:
select user_id,user_name from lw_user where user_name=#{userName,jdbcType=VARCHAR,typeHandler=org.apache.ibatis.type.IntegerTypeHandler}
这里因为我们配置了 typeHandler,所以会「优先以配置的 typeHandler 为主」不会再去读取默认的映射,如果类型不匹配就会直接报错了:
看到这里很多人应该就知道了,如果我们自己自定义一个 typeHandler,然后就可以配置成我们自己的自定义类。所以接下来就让我们看看如何自定义一个 typeHandler
自定义 typeHandler
自定义 typeHandler 需要实现 BaseTypeHandler 接口,BaseTypeHandler 有 4 个方法,包括结果集映射,为了节省篇幅,代码没有写上来:
package com.lonelyWolf.mybatis.typeHandler;import org.apache.ibatis.type.BaseTypeHandler;import org.apache.ibatis.type.JdbcType;import java.sql.CallableStatement;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;public class MyTypeHandler extends BaseTypeHandler<String> {@Overridepublic void setNonNullParameter(PreparedStatement preparedStatement, int index, String param, JdbcType jdbcType) throws SQLException {System.out.println("自定义typeHandler生效了");preparedStatement.setString(index,param);}
然后我们改写一下上面的查询语句:
select user_id,user_name from lw_user where user_name=#{userName,jdbcType=VARCHAR,typeHandler=com.lonelyWolf.mybatis.typeHandler.MyTypeHandler}
然后执行,可以看到,自定义的 typeHandler 生效了:
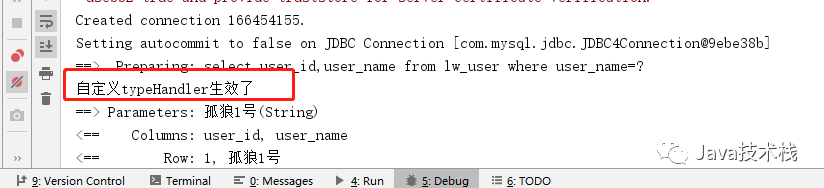
图片
结果集映射
接下来让我们看看结果集的映射,回到上面执行 sql 流程的最后一个方法:
resultSetHandler.handleResultSets(ps)
结果集映射里面的逻辑相对来说还是挺复杂的,因为要考虑到非常多的情况,这里我们就不会去深究每一个细节,直接进入到正式解析结果集的代码,下面的 5 个代码片段就是一个简单的但是完整的解析流程:
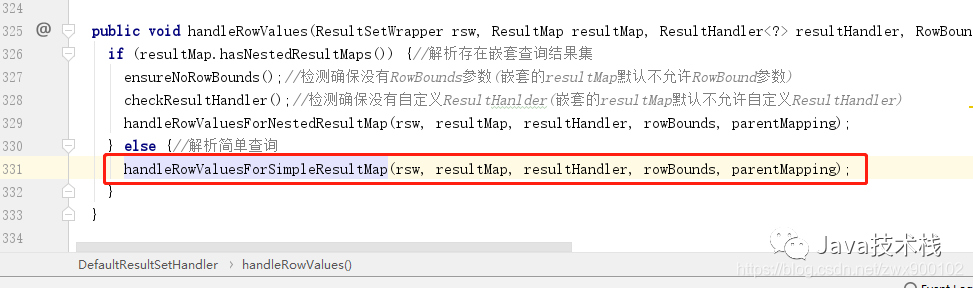
图片
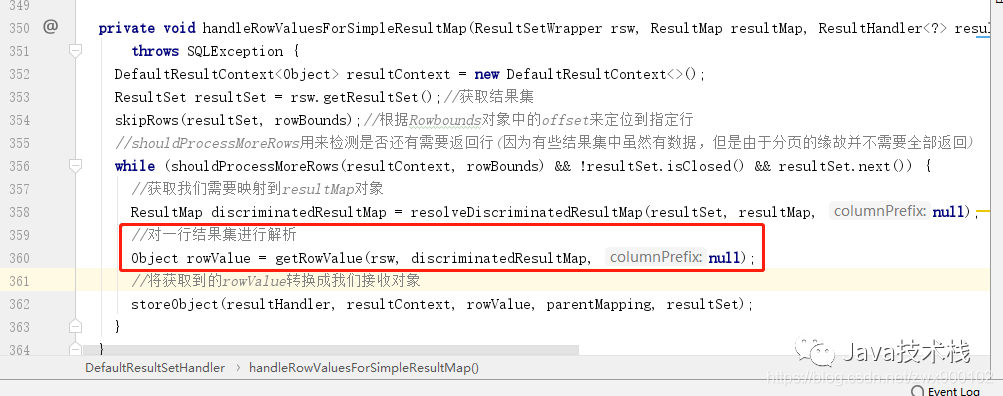
图片
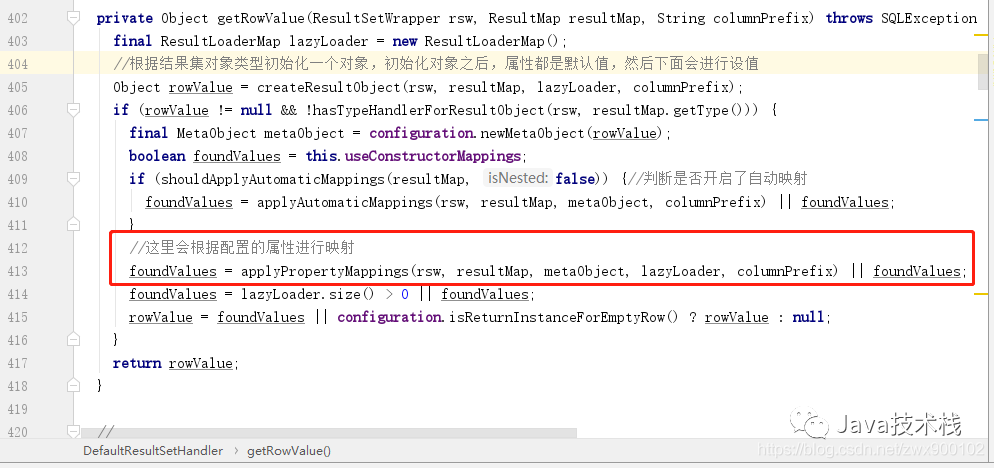
图片
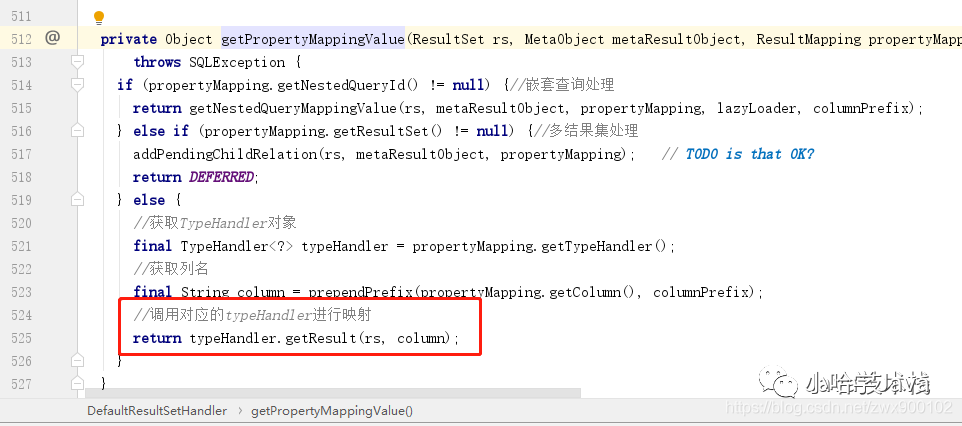
img
从上面的代码片段我们也可以看到,实际上解析结果集还是很复杂的,就如我们上一篇介绍的复杂查询一样,一个查询可以不断嵌套其他查询,还有延迟加载等等一些复杂的特性 的处理,所以逻辑分支是有很多,但是不管怎么处理,最后的核心还是上面的一套流程,最终还是会调用 typeHandler 来获取查询到的结果。
是的,你没猜错,这个就是上面我们映射参数的 typeHandler,因为 typeHandler 里面不只是一个设置参数方法,还有获取结果集方法 (上面设置参数的时候省略了)。
自定义 typeHandler 结果集
所以说我们还是用上面那个 MyTypeHandler 例子来重写一下取值方法 (省略了设置参数方法):
package com.lonelyWolf.mybatis.typeHandler;import org.apache.ibatis.type.BaseTypeHandler;import org.apache.ibatis.type.JdbcType;import java.sql.CallableStatement;import java.sql.PreparedStatement;import java.sql.ResultSet;import java.sql.SQLException;public class MyTypeHandler extends BaseTypeHandler<String> {/*** 设置参数*/@Overridepublic void setNonNullParameter(PreparedStatement preparedStatement, int index, String param, JdbcType jdbcType) throws SQLException {System.out.println("设置参数->自定义typeHandler生效了");preparedStatement.setString(index,param);}/*** 根据列名获取结果*/@Overridepublic String getNullableResult(ResultSet resultSet, String columnName) throws SQLException {System.out.println("根据columnName获取结果->自定义typeHandler生效了");return resultSet.getString(columnName);}/*** 根据列的下标来获取结果*/@Overridepublic String getNullableResult(ResultSet resultSet, int columnIndex) throws SQLException {System.out.println("根据columnIndex获取结果->自定义typeHandler生效了");return resultSet.getString(columnIndex);}/*** 处理存储过程的结果集*/@Overridepublic String getNullableResult(CallableStatement callableStatement, int columnIndex) throws SQLException {return callableStatement.getString(columnIndex);}}
改写 Mapper 映射文件配置:
<resultMap id="MyUserResultMap" type="lwUser"><result column="user_id" property="userId" jdbcType="VARCHAR" typeHandler="com.lonelyWolf.mybatis.typeHandler.MyTypeHandler" /><result column="user_name" property="userName" jdbcType="VARCHAR" /></resultMap><select id="listUserByUserName" parameterType="String" resultMap="MyUserResultMap">select user_id,user_name from lw_user where user_name=#{userName,jdbcType=VARCHAR,typeHandler=com.lonelyWolf.mybatis.typeHandler.MyTypeHandler}</select>
执行之后输出如下:
因为我们属性上面只配置了一个属性,所以只输出了一次。
工作流程图
上面介绍了代码的流转,可能绕来绕去有点晕,所以我们来画一个主要的对象之间流程图来更加清晰的展示一下 MyBatis 主要工作流程:
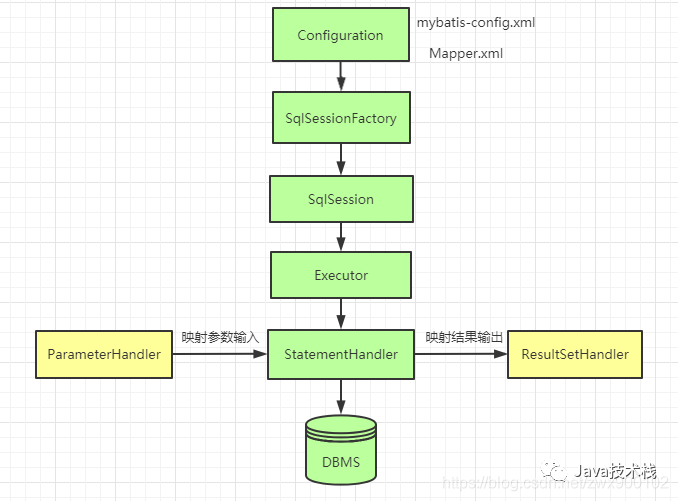
从上面的工作流程图上我们可以看到,SqlSession 下面还有 4 大对象,这 4 大对象也很重要,后面学习拦截器的时候就是针对这 4 大对象进行的拦截,关于这 4 大对象的具体详情,我们下一篇文章再展开分析。
总结
本文主要分析了 MyBatis 的 SQL 执行流程。在分析流程的过程中,我们也举例论证了如何自定义 typeHandler 来实现自定义的参数映射和结果集映射,不过 MyBatis 中提供的默认映射其实可以满足大部分的需求,如果我们对某些属性需要特殊处理,那么就可以采用自定义的 typeHandle 来实现,相信如果本文如果读懂了,以下几点大家应该至少会有一个清晰的认识:
- 1、Mapper 接口和映射文件是如何进行绑定的
- 2、MyBatis 中 SQL 语句的执行流程
- 3、自定义 MyBatis 中的参数设置处理器 typeHandler
- 4、自定义 MyBatis 中结果集处理器 typeHandler
当然,其中很多细节并没有提到,而看源码我们也并不需要追求每一行代码都能看懂,就比如我们一个稍微复杂一点的业务系统,即使我们是项目开发者如果某一个模块不是本人负责的,恐怕也很难搞清楚每一行代码的含义。所以对于 MyBatis 及其他框架的源码中也是一样,首先应该从大局入手,掌握整体流程和设计思想,然后如果对某些实现细节感兴趣,再深入进行了解。
原文

若有收获,就点个赞吧
0 人点赞
