(一)什么是雪崩效应
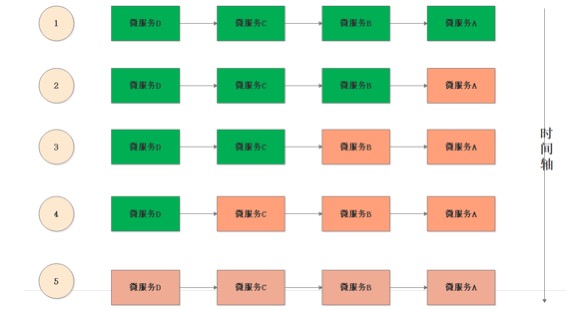
业务场景,高并发调用
①:正常情况下,微服务A B C D 都是正常的
②:随着时间推移,在某一个时间点 微服务A突然挂了, 此时的微服务B 还在疯狂的调用微服务A,由于A已经挂了,所以B调用A必须等待服务调用超时。而我们知道每次B->A的时候B都会去创建线程(而线程由是计算机的资源 比如cpu 内存等)。由于是高并发场景 B就会阻塞大量的线程。那么B所在的机器就会去创建线程,但是计算机资源是有限的,最后B的服务器就会宕机。(说白了微服务B 活生生的被猪队友微服务A给拖死的)
③: 由于微服务A这个猪队友活生生的把微服务B给拖死,导致微服务B也宕机了,然后也会导致微服务C D 出现类是的情况,最终我们的猪队友A成功的把微服务 B C D 都拖死了。这种情况也叫做服务雪崩。也有一个专业术语( cascading failures ) 级联故障.
(二)解决方案
1.超时机制
超时: 超时机制你懂的,配置一下超时时间,例如1秒——每次请求在1秒内必须返回,否则到点就把线程掐死,释放资源!
思路:一旦超时,就释放资源。由于释放资源速度较快,应用就不会那么容易被拖死
/*** 第一步:设置RestTemplate的超时时间*/@Configurationpublic class WebConfig {@Beanpublic RestTemplate restTemplate() {//设置restTemplate的超时时间SimpleClientHttpRequestFactory requestFactory = new SimpleClientHttpRequestFactory();requestFactory.setReadTimeout(1000);requestFactory.setConnectTimeout(1000);RestTemplate restTemplate = new RestTemplate(requestFactory);return restTemplate;}}/***第二步:进行超时异常处理*/try{ResponseEntity<ProductInfo> responseEntity= restTemplate.getForEntity(uri+orderInfo.getProductNo(), ProductInfo.class);productInfo = responseEntity.getBody();}catch (Exception e) {throw new RuntimeException("调用超时");}/*** 设置全局异常处理*/@ControllerAdvicepublic class TulingExceptionHandler {@ExceptionHandler(value = {RuntimeException.class})@ResponseBodypublic Object dealBizException() {OrderVo orderVo = new OrderVo();orderVo.setOrderNo("‐1");orderVo.setUserName("容错用户");return orderVo;}}
2.舱壁隔离模式
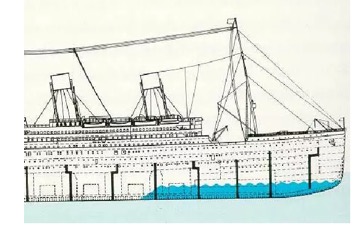
一般来说,现代的轮船都会分很多舱室,舱室之间用钢板焊死,彼此隔离。这样即使有某个/某些船舱进水,也不会影响其他舱室,浮力够,船不会沉。
代码中的舱壁隔离(线程池隔离模式)
M类使用线程池1,N类使用线程池2,彼此的线程池不同,并且为每个类分配的线程池大小,例如coreSize=10。举个例子:M类调用B服务,N类调用C服务,如果M类和N类使用相同的线程池,那么如果B服务挂了,M类调用B服务的接口并发又很高,你又没有任何保护措施,你的服务就很可能被M类拖死。而如果M类有自己的线程池,N类也有自己的线程池,如果B服务挂了,M类顶多是将自己的线程池占满,不会影响N类的线程池——于是N类依然能正常工作,
思路:不把鸡蛋放在一个篮子里。你有你的线程池,我有我的线程池,你的线程池满了和我没关系,你挂了也和我没关系。
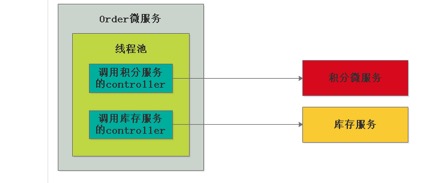
order微服务调用积分服务和库存服务共用一个线程池,由于积分服务消耗大量资源,导致库存服务就拿不到线程池资源,此时就会调用不通.
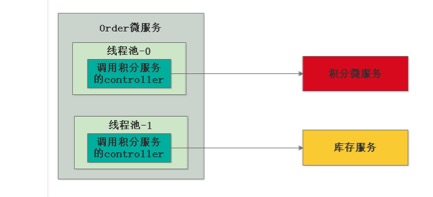
解决方案是分两个线程池,如果调用积分服务出问题了,只会给线程池0消耗掉,此时是不会影响线程池1的,所有调用积分服务是不会受到牵连的.
3.断路器模式
现实世界的断路器大家肯定都很了解,每个人家里都会有断路器。断路器实时监控电路的情况,如果发 现电路电流异常,就会跳闸,从而防止电路被烧毁。
保险丝熔点比较低,如果一旦家庭的电路短路的话,通过的电量就会变大,就会产生大量的热量,就会如果没保险丝的话就会烧毁你家里的电器,如果有保险丝的话,因为保险丝熔点比较低,就会给烧断了之后,此时就保护了家庭的电器,这样电器就不会着火.
断路器打开
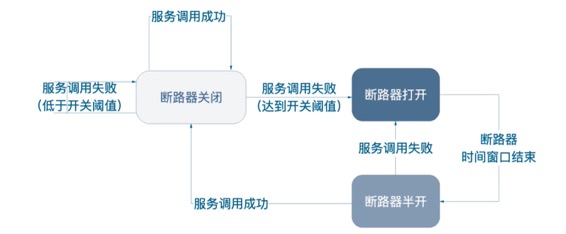
软件世界的断路器可以这样理解:实时监测应用,如果发现在一定时间内失败次数/失败率达到一定阈值,就“跳闸”,断路器打开——此时,请求直接返回,而不去调用原本调用的逻辑。
默认情况下断路器是关闭的,一旦你调用你的Controller的时候,比如说在10秒钟之内,调用错误的比例超过了断路器的阈值的话,或者是错误的次数超过阈值的话.
此时断路器就会打开,此时就不会进行远程调用,而是去调用你本地已经设置好的降级的方法
断路器关闭
从断路器打开的一瞬间开始,比如经过10秒钟之内结束的话,你一直是不会进行远程调用的,都是调用本地设置好的降级方法.
过了10秒之后,断路器会进入半开状态,此时会释放一次请求允许你进行远程调用,如果远程调用成功了,那么断路器就会回到关闭状态,如果这次释放的请求远程调用还是失败的话,那么断路器还是打开状态.
接着等10秒钟之后再次释放一次请求允许进行远程调用….. 以此循环..
这也是Hystrix框架的原理.

若有收获,就点个赞吧
0 人点赞
