总结
概念
官网地址:http://dubbo.apache.org/zh/docs/v2.7/user/examples/fault-tolerent-strategy/
集群容错表示:服务消费者在调用某个服务时,这个服务有多个服务提供者,在经过负载均衡后选出其中一个服务提供者之后进行调用,但调用报错后,Dubbo所采取的后续处理策略。
说白了就是我consumer调用了一个provider之后,请求报错了,那么consumer会自动重新调用集群中其它的provider, 如果还报错了,那么接着调用集群中另外其它的provider .直到超出集群容错上线,默认是重试2次
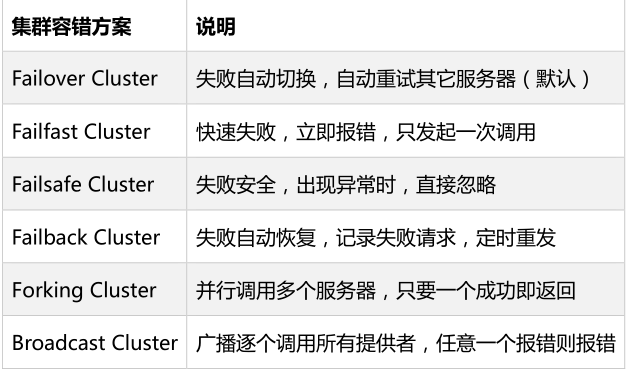
Failover Cluster失败自动切换(默认)
dubbo 的默认容错方案,当调用失败时自动切换到其他可用的节点,具体的重试次数和间隔时间可用通过引用服务的时候配置,默认重试次数为 1 是只调用一次。
失败自动切换,当出现失败,重试其它服务器。通常用于读操作,但重试会带来更长延迟。可通过 retries=”2” 来设置重试次数(不含第一次)。
Failfast Cluster
快速失败,只发起一次调用,失败立即报错。通常用于非幂等性的写操作,比如新增记录。
Failsafe Cluster
失败安全,出现异常时,直接忽略,返回一个空。通常用于写入审计日志等操作。
Failback Cluster失败自动恢复
失败自动恢复,后台记录失败请求,定时进行重发操作。通常用于消息通知操作。
在调用失败,记录日志和调用信息,然后返回空结果给 consumer,并且通过定时任务每隔 5 秒对失败的调用进行重试
Forking Cluster 并行调用多个服务提供者
通过线程池创建多个线程,并发调用多个 provider,结果保存到阻塞队列,只要有一个 provider 成功返回了结果,就会立刻返回结果
并行调用多个服务器,只要一个provider成功即返回,就代表本次调用成功了。通常用于实时性要求较高的读操作,但需要浪费更多服务资源。可通过 forks=”2” 来设置最大并行数。
Broadcast Cluster
逐个调用每个 provider,如果其中一台报错,在循环调用结束后,抛出异常。
广播调用所有提供者,逐个调用,任意一台报错则报错。通常用于通知所有提供者更新缓存或日志等本地资源信息。
现在广播调用中,可以通过 broadcast.fail.percent 配置节点调用失败的比例,当达到这个比例后,BroadcastClusterInvoker 将不再调用其他节点,直接抛出异常。 broadcast.fail.percent 取值在 0~100 范围内。默认情况下当全部调用失败后,才会抛出异常。 broadcast.fail.percent 只是控制的当失败后是否继续调用其他节点,并不改变结果(任意一台报错则报错)。broadcast.fail.percent 参数 在 dubbo2.7.10 及以上版本生效。
Broadcast Cluster 配置 broadcast.fail.percent。
broadcast.fail.percent=20 代表了当 20% 的节点调用失败就抛出异常,不再调用其他节点。
配置方式
consumer
//cluster = "failfast" 配置容错机制@Reference(timeout = 1000, cluster = "failfast")private DemoService demoService;

若有收获,就点个赞吧
0 人点赞
