有序性
从数据处理的角度看,有序性在很多场合都能够极大地提高计算的效率。二分查找策略之所以可行,正是因为所有元素已按次序排列。
排序及其分类
因此在解决许多应用问题时我们普遍采用的一种策略就是,首先将向量转换为有序向量,再调用有序向量支持的各种高效算法。这一过程的本质就是向量的排序。
根据其处理数据的规模与存储的特点不同,可分为内部排序算法和外部排序算法:前者处理的数据规模相对不大,内存足以容纳;后者处理的数据规模很大,必须将借助外部甚至分布式存储器,在排序计算过程的任一时刻,内存中只能容纳其中一小部分数据。
根据输入形式的不同,排序算法也可分为离线算法( offline algorithm) 和在线算法( online algorithm)。前一情况下,待排序的数据以批处理的形式整体给出;而在网络计算之类的环境中,待排序的数据通常需要实时生成,在排序算法启动后数据才陆续到达。
针对所依赖的体系结构不同,又可分为串行和并行两大类排序算法。
根据排序算法是否采用随机策略,还有确定式和随机式之分。
下界
一般地, 任一问题在最坏情况下的最低计算成本,即为该问题的复杂度下界(lower bound)。
一旦某一算法的性能达到这一下界, 即意味着它已是最坏情况下最优的。
比较树
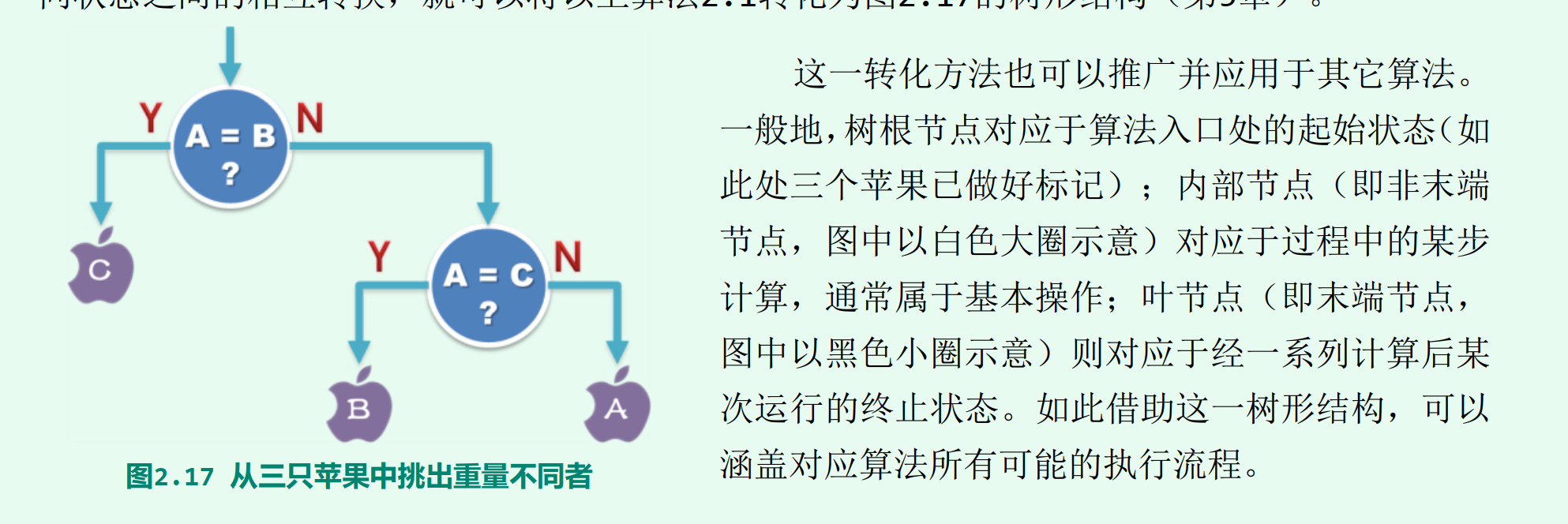
- 每一个内部节点各对应于一次比对操作
- 内部节点的左、右分支,分别对应于在两种比对结果(是否等重)下的执行方向
- 叶节点(或等效地,根到叶节点的路径)对应于算法某次执行的完整过程及输出
- 反过来,算法的每一运行过程都对应于从根到某一叶节点的路径
凡可如 此描述的算法,都称作基于比较式算法(comparison-based algorithm) ,简称CBA式算法
估计下界
求解排序算法CBA()都有一个下界(n*logn)

若有收获,就点个赞吧
0 人点赞
