1 怎么评价聚类的好坏?
(1)聚类往往不像分类一样有一个最优化目标和学习过程,而是一个统计方法,将相似的数据和不相似的数据分开。
(2)因为没有标签,所以一般通过评估类的分离情况来决定聚类质量。类内越紧密,类间距离越小则质量越高。
2 Kmeans算法
K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错。这里简单介绍一下k-means算法。 基本思想:
(1)k-means算法需要事先指定簇的个数k,算法开始随机选择k个记录点作为中心点.
(2)然后遍历整个数据集的各条记录,将每条记录归到离它最近的中心点所在的簇中.
(3)之后以各个簇的记录的均值中心点取代之前的中心点,然后不断迭代,直到收敛。
k-means 的损失函数为平方误差: 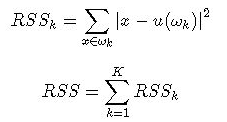
其中ωk表示第k个簇,u(ωk)表示第k个簇的中心点,RSSk是第k个簇的损失函数,RSS表示整体的损失函数。优化目标就是选择恰当的记录归属方案,使得整体的损失函数最小。
3 Kmeans文本聚类
(1)先把文本转成数值矩阵(计算 tf-idf)
(2)再使用上面的 k-means 算法进行计算。
(3)如果已知真实类别,直接用 P,R,F1评价就行了。如果不知道的话,可以计算聚类的紧密程度。

若有收获,就点个赞吧
0 人点赞
