1.多标签分类和单标签分类有什么区别?
多标记分类和传统的分类问题相比较,主要难点在于以下两个方面:
(1)类标数量不确定,有些样本可能只有一个类标,有些样本的类标可能只有一个,有的则可能十几个,但是在这个比赛中我们把这个问题简单化了,就是取 top5.
(2)类标之间相互依赖,例如一个问题可能是将神经网络算法的,那么它可能属于的话题就有深度学习,机器学习,人工智能等,这些话题,也就是标签之间可能是有比较强的相关性的。
解决方法:
·最简单的技术,每个标签当作单独的二分类问题。然后计算1999个二分类的一个平均值。这里看起来像是当做了1999个独立的问题,但实际上并不是。我们在神经网络的最后一层使用sigmoid计算交叉熵损失。对于每个输出节点,它们都共用前面的每一层网络,也就是前面各层的参数它们都是共享的,所以每个类别之间是有比较强的相关性来的。
·第二种方式是显式地去考虑标签之间的关系。有先后顺序的一系列Binary Classification,然后前边的Binary Classification会对后边的产生影响。比如在预测标签2的时候,我们把它预测成标签1的结果也当成输入。这时候算法的复杂度就非常大了。在类别数量非常多,样本数量非常大的时候几乎是不可实现的,而且我们要怎么去衡量这些类别之间的一个先后顺序也是比较困难的。
·在比赛中,我使用的是第一种方式。其他所有选手都没有显式考虑标签之间关系的。但是由于有很多类别之间关系紧密,也有一些可能比较容易混淆的类别。所以可以采用 boosting 的方式来提高识别率。1.我们先训练一个网络,在第一次预测的结果上,统计出训练样本中每个类别的错误率。2.然后在这个基础上调整每个类别的权重,重新训练相同的模型。3.如此反复,不断提高模型的拟合能力。这样做有两个问题:第一是非常非常耗费时间,因为boosting方法是串行的,单独训练一个网络就要一天了,所以这样boost计算时间要很多。就算是可以并行的,也没有这么多GPU可用。第二个是boosting的方法很有可能会过拟合,本身神经网络的拟合能力就很强了。但是好在这次比赛的数据量非常大,所以使用这种方式还是有明显的提高。
2.说说 tf-idf 的原理。
参考TF-IDF及其算法 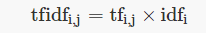
tf-idf 用来衡量词对于一个文档的重要程度。注意,在求 idf 的时候,如果所有文档中都没有出现过这个词,那么分母就会出现0,为了避免这个错误,通常分母是需要 +1 来避免出错。此外,idf 还需要取 log 进行处理。
至于为什么要使用对数,而不是开方或者其他的处理方式?感觉也没有非常正确的说法。
假设如果某个词在每个文档中都会出现:
(1)那么idf取了log算出来结果约等于0,直接认为这个词没什么用。
(2)如果idf不取log算出来的结果为 1,如果开方还是1,这时候和 tf 相乘,如果 tf 大说明这个词很重要。
上面这两种情况比较,会发现取 log 其实更好一些。
3.说说 HMM 和维特比译码的原理。
一文搞懂HMM(隐马尔可夫模型)
隐马尔可夫模型是可用于序列标注问题的统计学习模型,描述由马尔科夫链随机生成观测序列的过程,是一种生成模型。
3.1两个假设
·齐次马尔科夫假设:马尔科夫性质,无记忆。就是当前时刻只受前一个时刻的影响,不会受更往前一些时刻的影响。 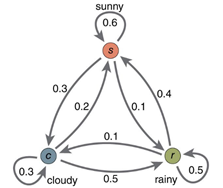
上图是一个马尔科夫链,每个节点表示状态,每条边表示转移概率。
在HMM中,假设状态有一个齐次马尔科夫链生成。(齐次:转移概率与起始位置无关)
·独立输出假设:在 HMM 中,每个时刻会输出一个可见的符号,这个符号与该时刻的状态相关,而且至于该时刻的状态相关。
3.2五个元素
通过上面的分析,就可以知道 HMM 模型其实是由五个元素构成的:状态序列I,输出序列O,转移概率分布A,输出概率分布B,初始状态概率分布π。
3.3三个问题
(1)概率计算问题:在已知模型 λ=(A,B,π)λ=(A,B,π) 和观测序列 O的情况下,计算 P(O|λ)P(O|λ) 的概率。
(2)学习问题:已知观测序列O,估计模型λ=(A,B,π)λ=(A,B,π)的参数,使得 P(O|λ)P(O|λ) 最大。
(3)预测问题(解码问题):已知模型λ=(A,B,π)λ=(A,B,π)和观测序列O,预测最有可能的状态序列I.
3.4以分词来理解预测问题
在自然语言处理中经常会用到隐马尔可夫模型,主要用在序列标注相关的问题上,比如:分词、命名实体识别和词性标注等。我自己也用BiLSTM + HMM 实现过简单的分词,在 HMM 中有 3 个问题,这是一个预测问题。
在分词中,可见序列指的是一个个文字,状态序列指的是该字的标注(词首,词中还是词尾等)。
已知:
·A(状态转移概率矩阵,通过统计训练样本获得)
·B(输出概率分布,以 Bi-LSTM 模型的分类输出概率作为对应时刻的输出概率)
·π(初始状态概率分布,初始只能是 s 或者 b,取 Bi-LSTM 预测的第一个时刻的结果中 s 和 b 的概率值)
要求的是: 通过维特比译码求解最有可能的状态(标注)序列。
实际步骤是:
我们有4个类别(s:singleword, b:begin, m:middle, e:end),然后对于每一个字都有对应的类别,通过有监督学习的方法来学习。
(1)使用 Bi-LSTM 进行分类,获得每个字属于每个类别的概率;
(2)以每个字在LSTM的分类概率作为该时刻的输出概率 b_t(i);
(3)使用维特比译码获取最有可能的标注结果。
在传统方法中,输出概率分布也是通过统计的方式来计算的。而在这里,我们先用 Bi-LSTM 分类的方式计算输出,然后再用维特比译码来进行强矫正。
4.关键词抽取怎么实现
这里学习结巴分词总结:
基于TF-IDF 算法的关键词抽取
·计算 TF-IDF,然后返回权重最大的 topK 作为关键词。
基于 TextRank 算法的关键词抽取
基本思想是:
Step 1. 将待抽取关键词的文本进行分词
Step 2. 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
Step 3. 计算图中节点的PageRank,注意是无向带权图
另外,我们可以结合 TextRank 和 tf-idf,先使用 TextRank 计算出每个词的得分,然后再乘以 tf-idf 作为最后的得分。
tf-idf 和 TextRank 比较
·tf-idf 依赖于整个数据库,我们要计算一个词在所有文档中出现的频率来衡量这个词的重要度。如果文档数量很少,使用 tf-idf 效果应该不好。
·而 TextRank 只是在一个文章中通过迭代的方式就可以算出每个词的重要度,如果文章比较长,词数比较多,那么这个转移矩阵就会非常大,迭代计算起来也会耗费很多时间。
5.page rank 的原理。
浅析PageRank算法
page rank 用来衡量一个网站的重要度。
·如果有很多网页指向 网页Y,那么Y的权重应该很大。就像一篇论文,如果有很多其他论文引用了它,那么这篇论文应该是很重要的一篇论文。
·不同网页给 Y 的贡献不同。就像一篇论文如果被 science 的论文引用了,那么这篇论文应该很不错。
假设世界上只有四个网页: 
那么就会有转移矩阵:
其中 Mij表示网页 j 分给网页 i 的权重。比如第 1 列是网页 A 分给其他网页的权重;第 1 行则表示网页 A 接受来自其他网页的权重。
初始权重: 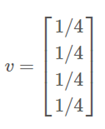
迭代一次: 
拿上面的网页 B 为例:看第二行,网页B接受了 1/3 网页 A 的权重和 1/2 网页 D 的权重,所以更新的结果为:1/4 1/3 + 1/4 1/2 = 5/24.
如此不断迭代,最终收敛就会得到每个网页的权重。
Dead Ends 没有输出,该列的值全为 0
处理Dead Ends的方法如下:迭代拿掉图中的Dead Ends节点及Dead Ends节点相关的边(之所以迭代拿掉是因为当目前的Dead Ends被拿掉后,可能会出现一批新的Dead Ends),直到图中没有Dead Ends。对剩下部分计算rank,然后以拿掉Dead Ends逆向顺序反推Dead Ends的rank。
Spider Traps及平滑处理
如果某个网页只有连到它自己的链接,那么迭代的时候就会越来越大,趋于1,而其他节点的值趋于0。这时候要做平滑,就是用户在浏览的时候可能会跳到一个随机网页继续浏览。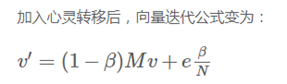
6.TextRank算法提取关键词和摘要
原理和PageRank一样。
(1)原本图中的节点是网页,这里的节点就是一个词。假设有1k个词,那么就有1k个节点。一般来说,去掉停用词以后,一篇长度为2千字的文章的词数应该最多就是几百吧;如果是两万字的文章,词数应该最多也就几千吧。
(2)原本每个网页通过链接到其他网页把权值分出去。这里在文本中,通过设定一个窗口长度,然后以这个词为中心,统计窗口内出现的其他词,然后把该词的权值分给它周围的词。
(3)在 tf-idf 中,我们计算 idf 需要统计一个词在所有文档中出现的次数,但是在这里我们只需要不需要考虑其他文档。
现在将每个单词作为图中的一个节点,同一个窗口中的任意两个单词对应的节点之间存在着一条边。然后利用投票的原理,将边看成是单词之间的互相投票,经过不断迭代,每个单词的得票数都会趋于稳定。一个单词的得票数越多,就认为这个单词越重要。
例如要从下面的文本中提取关键词:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
对这句话分词,去掉里面的停用词,然后保留词性为名词、动词、形容词、副词的单词。得出实际有用的词语:
程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理
现在建立一个大小为 9 的窗口,即相当于每个单词要将票投给它身前身后距离 5 以内的单词:
开发=[专业, 程序员, 维护, 英文, 程序, 人员]
软件=[程序员, 分为, 界限, 高级, 中国, 特别, 人员]
程序员=[开发, 软件, 分析员, 维护, 系统, 项目, 经理, 分为, 英文, 程序, 专业, 设计, 高级, 人员, 中国]
分析员=[程序员, 系统, 项目, 经理, 高级]
维护=[专业, 开发, 程序员, 分为, 英文, 程序, 人员]
系统=[程序员, 分析员, 项目, 经理, 分为, 高级]
项目=[程序员, 分析员, 系统, 经理, 高级]
经理=[程序员, 分析员, 系统, 项目]
分为=[专业, 软件, 设计, 程序员, 维护, 系统, 高级, 程序, 中国, 特别, 人员]
英文=[专业, 开发, 程序员, 维护, 程序]
程序=[专业, 开发, 设计, 程序员, 编码, 维护, 界限, 分为, 英文, 特别, 人员]
特别=[软件, 编码, 分为, 界限, 程序, 中国, 人员]
专业=[开发, 程序员, 维护, 分为, 英文, 程序, 人员]
设计=[程序员, 编码, 分为, 程序, 人员]
编码=[设计, 界限, 程序, 中国, 特别, 人员]
界限=[软件, 编码, 程序, 中国, 特别, 人员]
高级=[程序员, 软件, 分析员, 系统, 项目, 分为, 人员]
中国=[程序员, 软件, 编码, 分为, 界限, 特别, 人员]
人员=[开发, 程序员, 软件, 维护, 分为, 程序, 特别, 专业, 设计, 编码, 界限, 高级, 中国]
我们将文本中得票数多的若干单词作为该段文本的关键词,若多个关键词相邻,这些关键词还可以构成关键短语。
7.说说翻译模型是怎么进行评价的?对话系统怎么评价的?
7.1一种机器翻译的评价准则——Bleu
这篇文章介绍得很好,看一遍下来基本就能理解了,翻译模型一般使用 BLEU 指标进行评价,判断翻译的句子和提供参考的句子有多相似。
Step1. 每个生成句子(翻译结果),会跟提供的多个参考句子进行比较,比较 n-gram 的精确度。
Step2. 计算pn值,n-gram 的精确度。比如一个句子的长度为 18,那么就有17个 2-gram 语片。假设这17个 2-gram 中,有 10 个在参考句子中出现,那么 p2=10/17。有两点需要注意:1.参考句子中匹配过的片段,不能再被匹配;2.比如翻译句子中出现了 5 次 the 这个词,现在有3个参考句子,分别出现1/2/2次 the 这个值。那么 the 匹配正确的次数应该是 2 次,另外 3 次是错的。
由于可能取多个 n 值,一般来说会取 N = 4. 最后整合 p1, p2, p3, p4 作为最后的评价结果。
Step3. 计算BP值(Brevity Penalty,简洁度惩罚)。如果翻译的句子很短,那么上面(2)中的准确度很容易就取得很高的值。BP 值用来对翻译太短的结果进行惩罚。
7.2 BLEU的优缺点有哪些?
优点很明显:方便、快速、结果有参考价值
缺点也不少,主要有:
(1)不考虑语言表达(语法)上的准确性;
(2)测评精度会受常用词的干扰;
(3)短译句的测评精度有时会较高;
(4)没有考虑同义词或相似表达的情况,可能会导致合理翻译被否定;
7.3现在基于深度学习的对话系统常用的评价指标有哪些?
(1)检索类评价指标: Recall@k
(2)生成类评价指标:BLEU,ROUGE 和 METEOR。
(3)基于学习的评价指标:使用机器学习、神经网络学习一个评价指标,用来进行打分。
(4)人工评价。
8.文本聚类怎么评估?
8.1怎么评价聚类的好坏?
(1)聚类往往不像分类一样有一个最优化目标和学习过程,而是一个统计方法,将相似的数据和不相似的数据分开。
(2)因为没有标签,所以一般通过评估类的分离情况来决定聚类质量。类内越紧密,类间距离越小则质量越高。
8.2Kmeans算法
K-Means是常用的聚类算法,与其他聚类算法相比,其时间复杂度低,聚类的效果也还不错。这里简单介绍一下k-means算法。 基本思想:
(1)k-means算法需要事先指定簇的个数k,算法开始随机选择k个记录点作为中心点.
(2)然后遍历整个数据集的各条记录,将每条记录归到离它最近的中心点所在的簇中.
(3)之后以各个簇的记录的均值中心点取代之前的中心点,然后不断迭代,直到收敛。
k-means 的损失函数为平方误差: 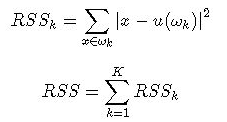
其中ωk表示第k个簇,u(ωk)表示第k个簇的中心点,RSSk是第k个簇的损失函数,RSS表示整体的损失函数。优化目标就是选择恰当的记录归属方案,使得整体的损失函数最小。
8.3Kmeans文本聚类
(1)先把文本转成数值矩阵(计算 tf-idf)
(2)再使用上面的 k-means 算法进行计算。
(3)如果已知真实类别,直接用 P,R,F1评价就行了。如果不知道的话,可以计算聚类的紧密程度。

若有收获,就点个赞吧
0 人点赞
