参考1:CS224n笔记2 词的向量表示:word2vec 参考2:CS224n笔记3 高级词向量表示 参考2:不懂word2vec,还敢说自己是做NLP?
参考1 hancks 的笔记非常详细易懂,根据该笔记进行复习基本上就差不多了。
1 两种算法
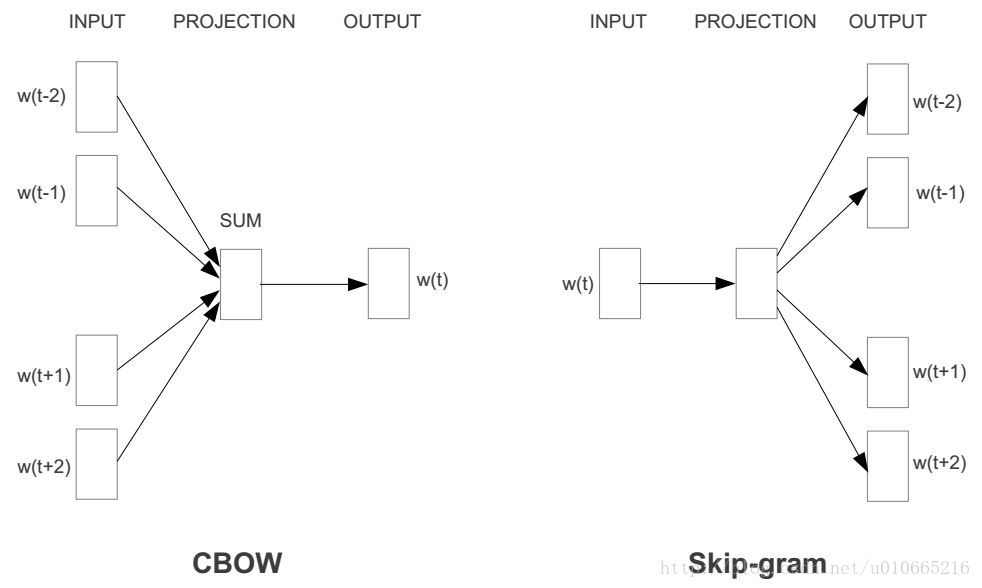
1.1 CBOW (Continuous Bag-of-Words Model)
根据上下文来预测当前词,一般会设一个窗口大小,比如 5,那么输入就是上下文的 10 个词
在 CBOW 中一般把上下文的 10 个词的词向量求和(或者求平均),然后预测中间的词
1.2 SG (Skip-gram)
根据当前词来预测上下文,同样也会选择窗口大小,比如 5,那么我们就会根据当前和窗口内的词构成10组样本
每一次都是根据中间的词预测窗口内的某一个词
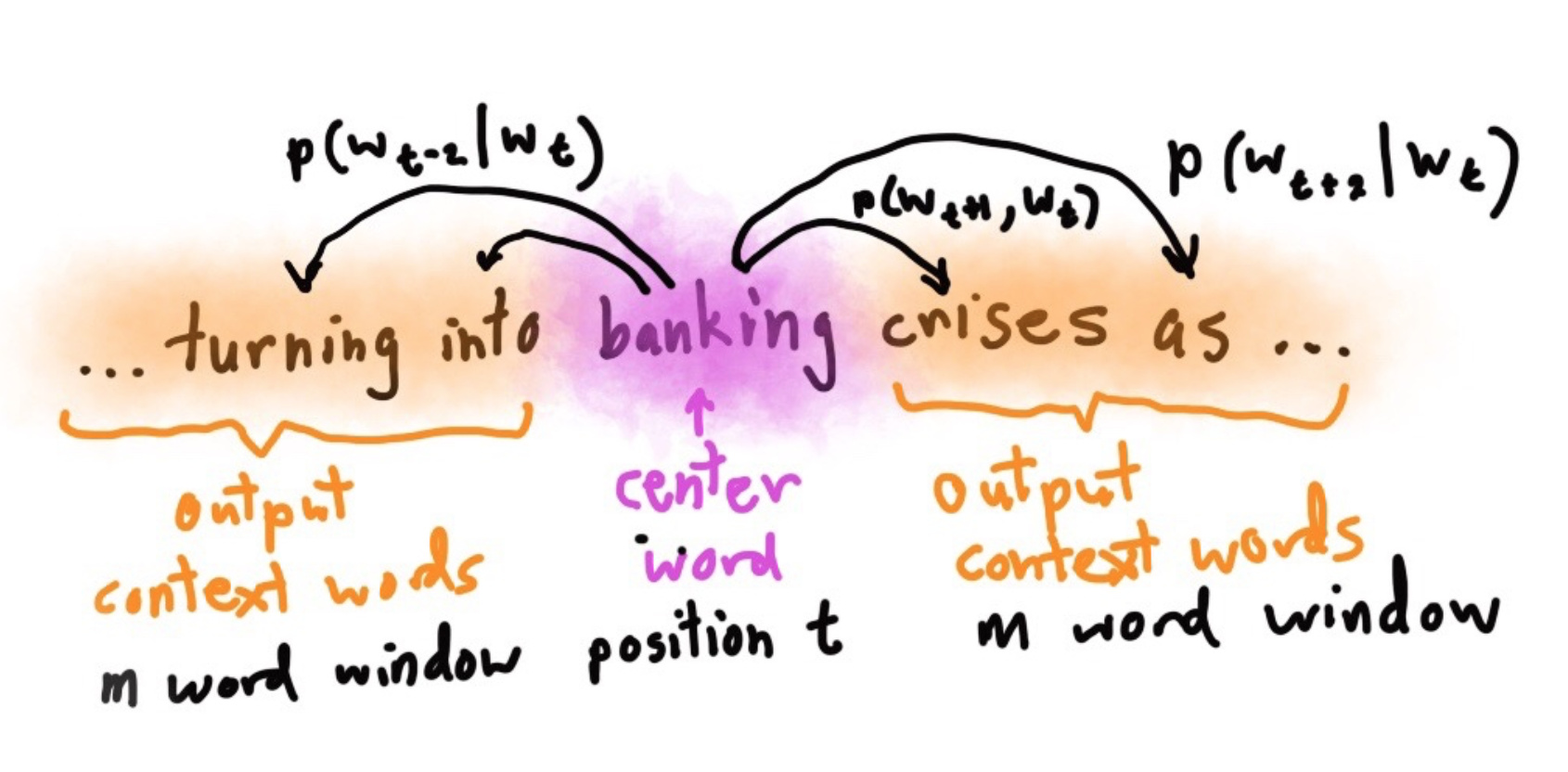
每个样本是包含中间词作为输入,窗口内的某个词作为预测输出的一组。
目标是最大化似然函数: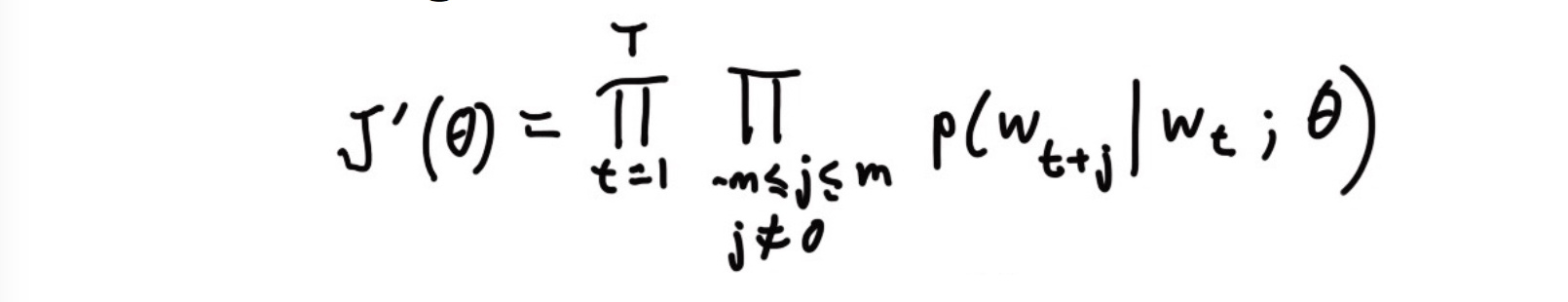
取负对数: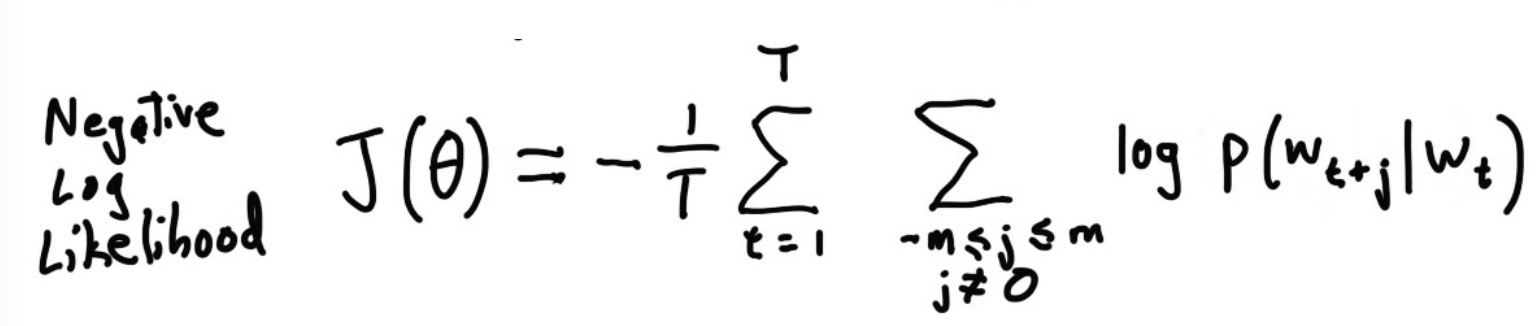
预测到的某个上下文条件概率p(wt+j|wt)可由softmax得到:
o是输出的上下文词语中的确切某一个,c是中间的词语。u是对应的上下文词向量,v是词向量。
在这里有两个矩阵 U, V,一般会有两种策略:
把两个矩阵就平均(或者相加)
把两个矩阵进行拼接
2 两种高效的训练方法
2.1 Negative sample
词表V的量级非常大,以至于下式的分母很难计算,因此在分母中需要进行负采样():
于是,练习1中要求用negative sampling实现skip-gram。这是一种采样子集简化运算的方法。具体做法是,对每个正例(中央词语及上下文中的一个词语)采样几个负例(中央词语和其他随机词语),训练binary logistic regression(也就是二分类器)。
在负采样中,有了 U,V 两个大矩阵,每次我们就是计算几个 logistic regression:
2.2 Hierarchical Softmax
参考: word2vec 中的数学原理详解(四)基于 Hierarchical Softmax 的模型
首先是根据词频构建一棵哈夫曼树,每个叶子节点对应一个词 w 向量
 ,假设长度是100.
,假设长度是100.  表示上下文对应的词向量
表示上下文对应的词向量每个非叶子节点对应一个维度和词向量相同的向量 θ,
 表示词 w 对应的路径上面的非叶子节点的参数。每个非叶子节点都是一个 LR 二分类。
表示词 w 对应的路径上面的非叶子节点的参数。每个非叶子节点都是一个 LR 二分类。 对应路径中每个节点的编码(类别标签,比如 1 表示左边,0 表示分到右边)
对应路径中每个节点的编码(类别标签,比如 1 表示左边,0 表示分到右边)那么词 w 的条件概率为
 ,其中
,其中  表示词 w 对应的路径长度; 表示词 w 的上下文对应的词向量
表示词 w 对应的路径长度; 表示词 w 的上下文对应的词向量先更新 θ
- 在实际计算中,我们不会去优化上面连乘的条件概率,而是逐个更新每个节点上面的参数。比如词 w 路径中有 5 个节点,那么就会分别更新这个对应的五个节点的参数,而且是可以并行更新的
再更新
 上下文对应的词向量
上下文对应的词向量- 在更新了每个节点的参数 θ 之后,然后计算每个节点的 loss 并求和,得到的就是 training loss, 再根据这个 loss 来更新 (此时是固定所有的 θ),如果 是 SG 的话直接更新就行了,如果是CBOW 中根据上下文求和得到的向量,则每个词都更新。
- 在更新了每个节点的参数 θ 之后,然后计算每个节点的 loss 并求和,得到的就是 training loss, 再根据这个 loss 来更新

可以看到,每次更新的都是上下文的词向量。
3 Trick
窗口的大小是随机的,默认值 5 是上限
每次选出来的词 pair 会根据词频计算一个概率值来判断这次是否要丢弃它,从而保证低频词能够更加准确
无论是负采样还是分层的哈夫曼,实际上都没有计算 softmax,而是计算 sigmoid。在工程实现中一般是先对
 建好取值表,从而加快计算速度
建好取值表,从而加快计算速度在分层哈夫曼中,是通过近似的方式来计算路径的条件概率。即每个节点对应的二分类都是分别优化的,而且是可以并行的。

若有收获,就点个赞吧
0 人点赞
