1 关键词提取
基于TF-IDF 算法的关键词抽取
- 计算 TF-IDF,然后返回权重最大的 topK 作为关键词。
基于 TextRank 算法的关键词抽取,基本思想是:
Step 1. 将待抽取关键词的文本进行分词
Step 2. 以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图
Step 3. 计算图中节点的PageRank,注意是无向带权图
另外,我们可以结合 TextRank 和 tf-idf,先使用 TextRank 计算出每个词的得分,然后再乘以 tf-idf 作为最后的得分。
tf-idf 和 TextRank 比较
tf-idf 依赖于整个数据库,我们要计算一个词在所有文档中出现的频率来衡量这个词的重要度。如果文档数量很少,使用 tf-idf 效果应该不好。
而 TextRank 只是在一个文章中通过迭代的方式就可以算出每个词的重要度,如果文章比较长,词数比较多,那么这个转移矩阵就会非常大,迭代计算起来也会耗费很多时间。
2 说说 tf-idf 的原理。
参考TF-IDF及其算法 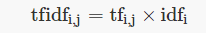
tf-idf 用来衡量词对于一个文档的重要程度。注意,在求 idf 的时候,如果所有文档中都没有出现过这个词,那么分母就会出现0,为了避免这个错误,通常分母是需要 +1 来避免出错。此外,idf 还需要取 log 进行处理。

至于为什么要使用对数,而不是开方或者其他的处理方式?感觉也没有非常正确的说法。
假设如果某个词在每个文档中都会出现:
(1)那么idf取了log算出来结果约等于0,直接认为这个词没什么用。
(2)如果idf不取log算出来的结果为 1,如果开方还是1,这时候和 tf 相乘,如果 tf 大说明这个词很重要。 上面这两种情况比较,会发现取 log 其实更好一些。
3 page rank 的原理。
浅析PageRank算法 page rank 用来衡量一个网站的重要度。
·如果有很多网页指向 网页Y,那么Y的权重应该很大。就像一篇论文,如果有很多其他论文引用了它,那么这篇论文应该是很重要的一篇论文。
·不同网页给 Y 的贡献不同。就像一篇论文如果被 science 的论文引用了,那么这篇论文应该很不错。
假设世界上只有四个网页: 
那么就会有转移矩阵:
其中 Mij表示网页 j 分给网页 i 的权重。比如第 1 列是网页 A 分给其他网页的权重;第 1 行则表示网页 A 接受来自其他网页的权重。
初始权重: 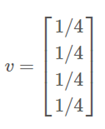
迭代一次: 
拿上面的网页 B 为例:看第二行,网页B接受了 1/3 网页 A 的权重和 1/2 网页 D 的权重,所以更新的结果为:1/4 1/3 + 1/4 1/2 = 5/24.
如此不断迭代,最终收敛就会得到每个网页的权重。
Dead Ends 没有输出,该列的值全为 0
处理Dead Ends的方法如下:迭代拿掉图中的Dead Ends节点及Dead Ends节点相关的边(之所以迭代拿掉是因为当目前的Dead Ends被拿掉后,可能会出现一批新的Dead Ends),直到图中没有Dead Ends。对剩下部分计算rank,然后以拿掉Dead Ends逆向顺序反推Dead Ends的rank。
Spider Traps及平滑处理
如果某个网页只有连到它自己的链接,那么迭代的时候就会越来越大,趋于1,而其他节点的值趋于0。这时候要做平滑,就是用户在浏览的时候可能会跳到一个随机网页继续浏览。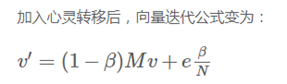
这里学习结巴分词总结:
4 TextRank算法提取关键词和摘要
原理和PageRank一样。
(1)原本图中的节点是网页,这里的节点就是一个词。假设有1k个词,那么就有1k个节点。一般来说,去掉停用词以后,一篇长度为2千字的文章的词数应该最多就是几百吧;如果是两万字的文章,词数应该最多也就几千吧。
(2)原本每个网页通过链接到其他网页把权值分出去。这里在文本中,通过设定一个窗口长度,然后以这个词为中心,统计窗口内出现的其他词,然后把该词的权值分给它周围的词。
(3)在 tf-idf 中,我们计算 idf 需要统计一个词在所有文档中出现的次数,但是在这里我们只需要不需要考虑其他文档。
现在将每个单词作为图中的一个节点,同一个窗口中的任意两个单词对应的节点之间存在着一条边。然后利用投票的原理,将边看成是单词之间的互相投票,经过不断迭代,每个单词的得票数都会趋于稳定。一个单词的得票数越多,就认为这个单词越重要。 例如要从下面的文本中提取关键词:
程序员(英文Programmer)是从事程序开发、维护的专业人员。一般将程序员分为程序设计人员和程序编码人员,但两者的界限并不非常清楚,特别是在中国。软件从业人员分为初级程序员、高级程序员、系统分析员和项目经理四大类。
对这句话分词,去掉里面的停用词,然后保留词性为名词、动词、形容词、副词的单词。得出实际有用的词语:
程序员, 英文, 程序, 开发, 维护, 专业, 人员, 程序员, 分为, 程序, 设计, 人员, 程序, 编码, 人员, 界限, 特别, 中国, 软件, 人员, 分为, 程序员, 高级, 程序员, 系统, 分析员, 项目, 经理
现在建立一个大小为 9 的窗口,即相当于每个单词要将票投给它身前身后距离 5 以内的单词:
开发=[专业, 程序员, 维护, 英文, 程序, 人员] 软件=[程序员, 分为, 界限, 高级, 中国, 特别, 人员] 程序员=[开发, 软件, 分析员, 维护, 系统, 项目, 经理, 分为, 英文, 程序, 专业, 设计, 高级, 人员, 中国] 分析员=[程序员, 系统, 项目, 经理, 高级] 维护=[专业, 开发, 程序员, 分为, 英文, 程序, 人员] 系统=[程序员, 分析员, 项目, 经理, 分为, 高级] 项目=[程序员, 分析员, 系统, 经理, 高级] 经理=[程序员, 分析员, 系统, 项目] 分为=[专业, 软件, 设计, 程序员, 维护, 系统, 高级, 程序, 中国, 特别, 人员] 英文=[专业, 开发, 程序员, 维护, 程序] 程序=[专业, 开发, 设计, 程序员, 编码, 维护, 界限, 分为, 英文, 特别, 人员] 特别=[软件, 编码, 分为, 界限, 程序, 中国, 人员] 专业=[开发, 程序员, 维护, 分为, 英文, 程序, 人员] 设计=[程序员, 编码, 分为, 程序, 人员] 编码=[设计, 界限, 程序, 中国, 特别, 人员] 界限=[软件, 编码, 程序, 中国, 特别, 人员] 高级=[程序员, 软件, 分析员, 系统, 项目, 分为, 人员] 中国=[程序员, 软件, 编码, 分为, 界限, 特别, 人员] 人员=[开发, 程序员, 软件, 维护, 分为, 程序, 特别, 专业, 设计, 编码, 界限, 高级, 中国]
我们将文本中得票数多的若干单词作为该段文本的关键词,若多个关键词相邻,这些关键词还可以构成关键短语。

若有收获,就点个赞吧
0 人点赞
