参考1:语言模型的基本概念
统计语言模型
语言模型就是用来计算一个句子的概率的模型,即P(W,W,…W)。利用语言模型,可以确定哪个词序列的可能性更大,或者给定若干个词,可以预测下一个最可能出现的词语。
如何计算一个句子的概率呢?给定句子(词语序列)S=W,W,…,W,它的概率可以表示为:
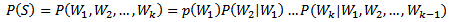
上式中的参数过多,因此需要近似的计算方法。常见的方法有n-gram模型方法、决策树方法、最大熵模型方法、最大熵马尔科夫模型方法、条件随机域方法、神经网络方法,等等。
n-gram 语言模型
n-gram模型也称为n-1阶马尔科夫模型,它有一个有限历史假设:当前词的出现概率仅仅与前面n-1个词相关。因此(1)式可以近似为:
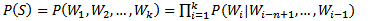
n-gram模型的参数估计 也称为模型的训练,一般采用最大似然估计, C(X)表示X在训练语料中出现的次数,训练语料的规模越大,参数估计的结果越可靠。
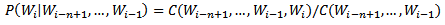 但即使训练数据的规模很大,如若干GB,还是会有很多语言现象在训练语料中没有出现过,这就会导致很多参数(某n元对的概率)为0。这种问题也被称为数据稀疏(Data Sparseness),解决数据稀疏问题可以通过数据平滑(Data Smoothing)技术来解决。
但即使训练数据的规模很大,如若干GB,还是会有很多语言现象在训练语料中没有出现过,这就会导致很多参数(某n元对的概率)为0。这种问题也被称为数据稀疏(Data Sparseness),解决数据稀疏问题可以通过数据平滑(Data Smoothing)技术来解决。n-gram模型的数据平滑
n-gram模型的解码算法(维特比译码)

若有收获,就点个赞吧
0 人点赞
