Web打开看到的是音频和视频分离两个文件:
从HTML内容中可以找到’video_id’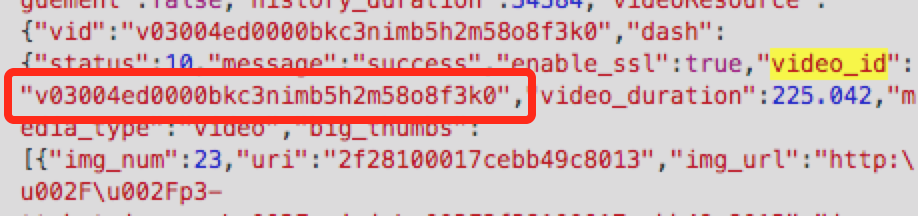
根据下面的算法请求可以获取融合的视频。(猜测也许是在另一个平台上播放)
记录一下西瓜视频 MP4 地址的获取步骤
目标:
指定西瓜视频地址,如 https://www.ixigua.com/a6562763969642103303/#mid=6602323830,获取其视频 MP4 文件的下载地址
以下使用 chrome 浏览器
开始分析:
首先在浏览器中打开视频页面,打开审查元素(右键 -> 审查元素 或 F12)并刷新页面,查看 network 选项中抓到的包
技巧 1:
由于我们获取的是视频文件的下载地址,而视频文件一般比较大,所以可以在 network 的包列表中使用 Size 排序一下 查看最大的几个包
如图: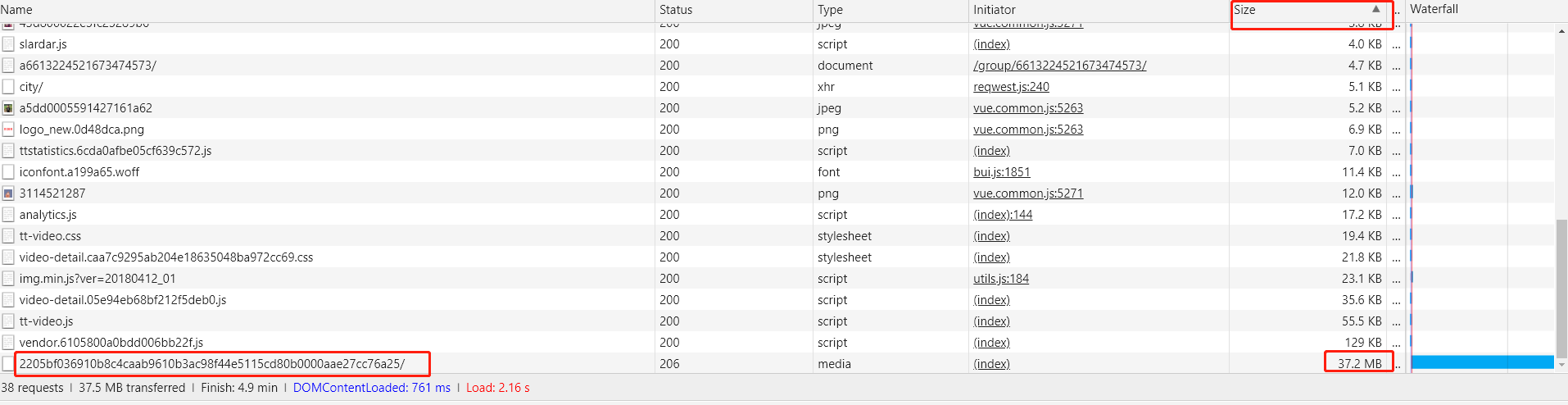
这里我们很容易就能确定视频文件的地址
http://v11-tt.ixigua.com/5cc4c0ae0f7d6f87014dc0f0058157e0/5bcc7300/video/m/220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc/
(你得到的地址和我得到的可能不一样,不过 url 路径中的最后一串字符串应该是一样的)
下面我们就要寻找这个地址是从哪里获取的,一般做法就是截取 url 中比较有代表的部分(这个看经验,你应该懂的)来搜索,搜索可以使用 chrome 审查元素的 Search 功能
这个搜索会查找 network 栏中所有包的响应内容,如果搜到的话,我们就可以确定视频文件地址的来源。
为什么这么做呢?
按照正常的想法,首先这个视频文件的获取请求是浏览器发起的,那么浏览器肯定在发起前就得到了视频文件的地址,那么地址存在什么地方呢?一般来说,不外乎直接写
在网页源代码中或者使用一个 ajax 请求之类的获取一下视频地址,所以这个地址肯定存在于我们目前所能看到的 network 列表中的包之中。
BUT,在这个例子中,搜索结果为空。尝试各种截取方法 比如 220f87599d445a14a53803fd01d86816e971157c7a70000cab5121742cc、5cc4c0ae0f7d6f87014dc0f0058157e0、v11-tt.ixigua.com
都搜索不到。
好吧,既然搜不到,那我们就用暴力一点的办法,好在这个网页的 network 包列表并不多,我们就一个一个找就好了,找的过程一般可以忽略 css、图片、多媒体等文件,
优先查看 json 格式的文件
下面人工查看中。。。
查看一遍之后呢,我发现了一个可疑的链接
https://ib.365yg.com/video/urls/v/1/toutiao/mp4/v02004bd0000bc9po7aj2boojm5cta5g?r=048136401358795045&s=3128215333&aid=1190&callback=axiosJsonpCallback1&_=1540123000124
首先,url 就很可疑,里面包含各种敏感关键词,如 mp4、urls 等
其次,内容可疑: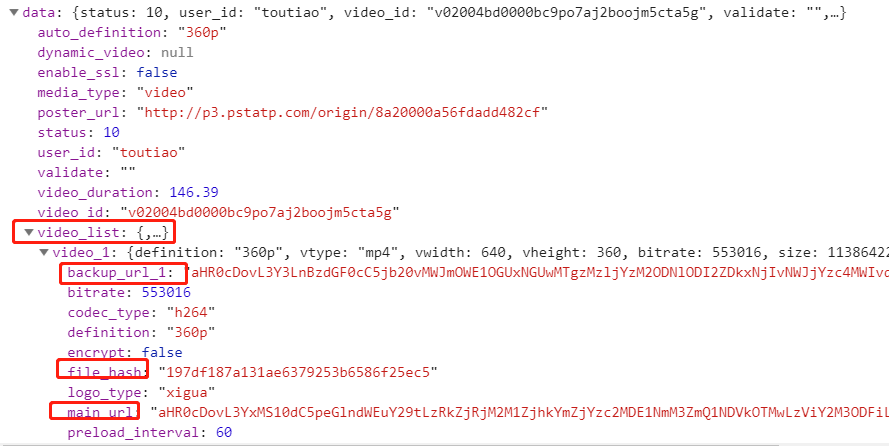
videolist 都出来了,不是它还能是谁呢?但是,定睛一看,这个内容里面的 url 格式不大对,一看就像是加密过后的,怪不得搜不到呢
下面就是想办法找到解密方法,来验证一下,这里看到的是不是我们想要的视频地址了
先捋一下思路,我们找到的这些数据是浏览器请求回来的,既然请求这些数据,肯定会有用到的地方,下面我们就来找一下这些数据在哪里被使用了,怎么找呢,还是搜索,拿这些数据中的变量名来搜
这些数据中可疑变量有两个:backup_url_1、main_url,第一个一看就是备用的,所以我们拿第二个搜吧
搜索结果如图: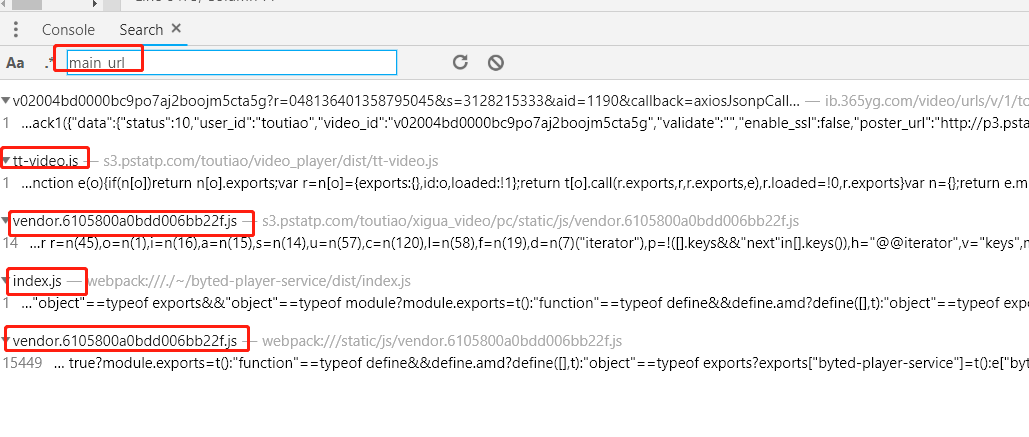
下面在这些包中定位 main_url 所在的代码,很幸运,第一个就是我们想要的(tt-video.js)
如图: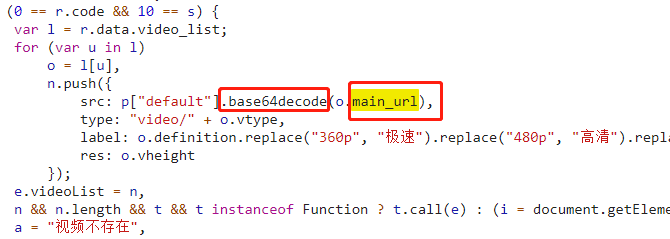
从代码中我们可以看到,main_url 使用了 base64decode 来进行解密,下面使用代码验证(这个请自行验证)一下,果然得到了我们想要的视频地址
此时,我们已经有了从这个包中获取视频地址的方法了,那么下个问题是,这个包的地址是如何生成的?
首先分析一下这个包的 url 的组成:
[https://ib.365yg.com/video/urls/v/1/toutiao/mp4/v02004bd0000bc9po7aj2boojm5cta5g?r=048136401358795045&s=3128215333&aid=1190&callback=axiosJsonpCallback1&=1540123000124](https://ib.365yg.com/video/urls/v/1/toutiao/mp4/v02004bd0000bc9po7aj2boojm5cta5g?r=048136401358795045&s=3128215333&aid=1190&callback=axiosJsonpCallback1&_=1540123000124)
首先去掉无关紧要的参数,方法很简单,直接在浏览器中打开这个 url,然后尝试删减参数,不断测试就可以了,删减后的 url 如下
https://ib.365yg.com/video/urls/v/1/toutiao/mp4/v02004bd0000bc9po7aj2boojm5cta5g?r=048136401358795045&s=3128215333
然后发现,其中有三个东西不知道哪里来的,下面继续使用我们的搜索工具来寻找,一个一个来。
(注意:跟随文章一步一步走的时候可能看到的参数和我这里写的参数不一样,请按照实际的来搜索)
先是 v02004bd0000bc9po7aj2boojm5cta5g,搜索结果如下: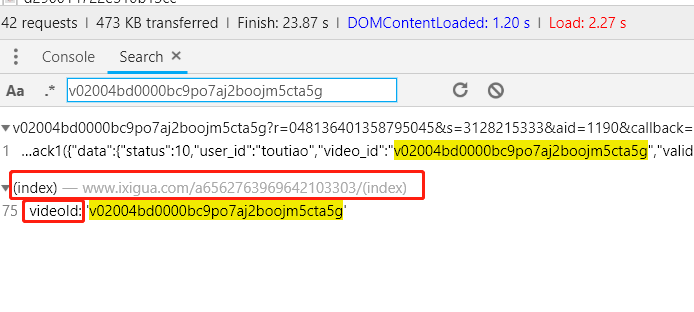
原来这个参数是视频的 videoId,直接在网页源码中,好,第一个搞定
下面看第二个参数 048136401358795045 搜不到
下面看第三个参数 3128215333 搜不到
后面两个参数都搜不到,可能是实时生成的或者加密了,所以换个思路,用 url 的前半部分的关键词去搜 https://ib.365yg.com/video/urls/v/1/toutiao/mp4, 看那里用到了这个
关于关键词 当然是越长越准确,所以我选取的搜索词是 video/urls/v/1/toutiao/mp4 搜索结果如下: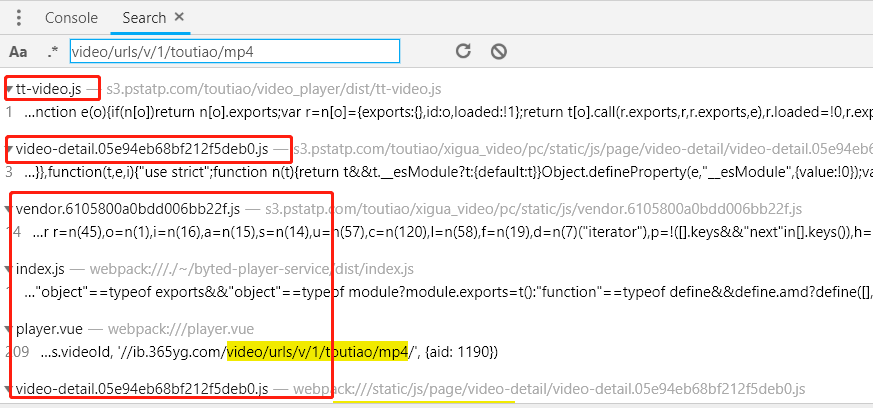
这里只能一个一个点开看源码了。。。
看源码的时候注意点有以下几个:
1、查看上下文,看所在函数作用 所在文件作用
2、思考我们搜索的东西是什么,比如本例中搜索的是一个视频资源的 url,那么肯定要特别关注和视频相关的关键词,函数名之类的东西
哈哈,幸运的是,在第一个文件(tt-video.js)中我就找到了很可疑的代码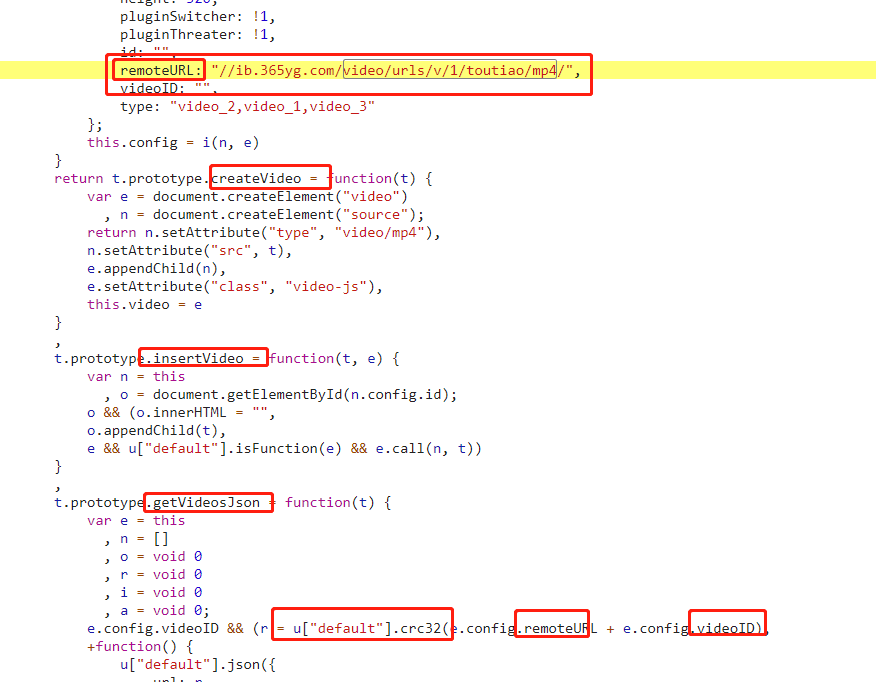
这里面全是 video 相关的,更可疑的是这个 getVideosJson 函数名,然后我发现有个 crc32 函数用到了目标 url,那下面就看一下 crc32 函数在哪里定义的
(PS:标准 crc32 是一个公开算法,用于生成一段数据的校验码,不过一般这些反爬虫的前端工程师们都会自己实现一下,所以还是以 JS 代码为准)
通过搜索 crc32 关键词,可以定位到如下代码: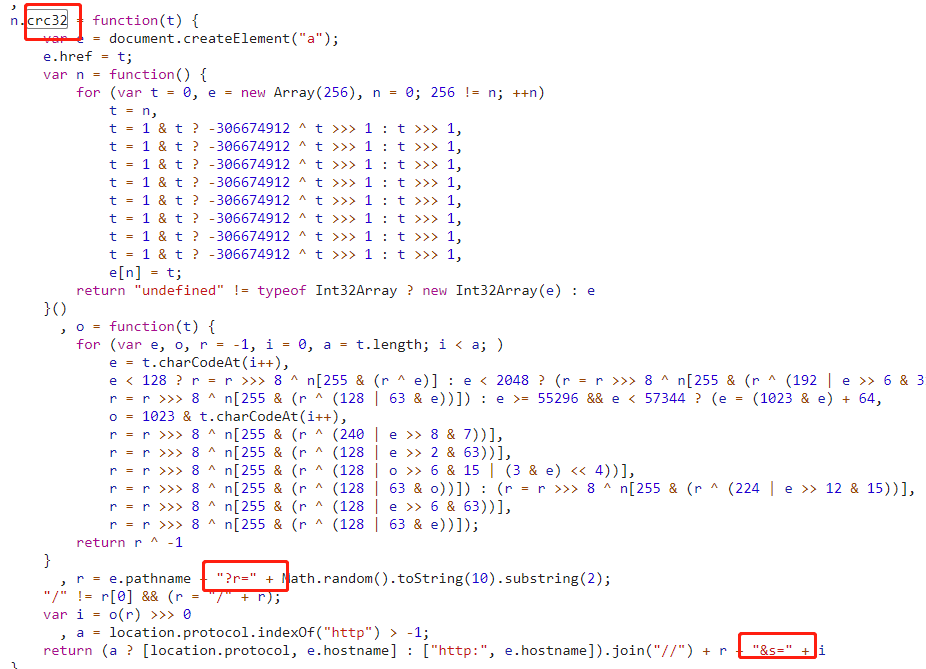
重点看图中的标红区域,苦寻不见的 r 和 s 参数在这里出现了,这说明我们的思路应该是正确的,然后发现 r 的值是随机生成的,这个好办,我们待会也随机生成一个就行,最好完全按照 JS 代码来模拟。
但是 s 的值好像略微复杂一下,嗯,下面就是考验你脑力的时刻了。
s 的值是由函数 o 生成的,但是 o 的代码很复杂,这个怎么办呢?
第一种办法:
硬上呗,把 JS 代码的算法完全模拟了,使用别的语言尝试计算,或者使用 js 引擎比如 pyv8, nodejs 等来执行都可以
第二种办法:
怎么说呢,换位思考一下,如果你是写这段代码的前端工程师,你会怎么做,难道你会去从零开始实现一个校验算法???(当然不可否认,确实有某些情况下,算法是自创的)既然这个函数是
crc32 这样的公开算法,每种语言基本都有实现的标准库,所以直接调用标准库测试一下就可以了,如果加密结果一致,皆大欢喜,不一致,请参考第一种方法。
ok,到目前为止,分析已经完成了,下面就是写代码的时刻了。代码如下: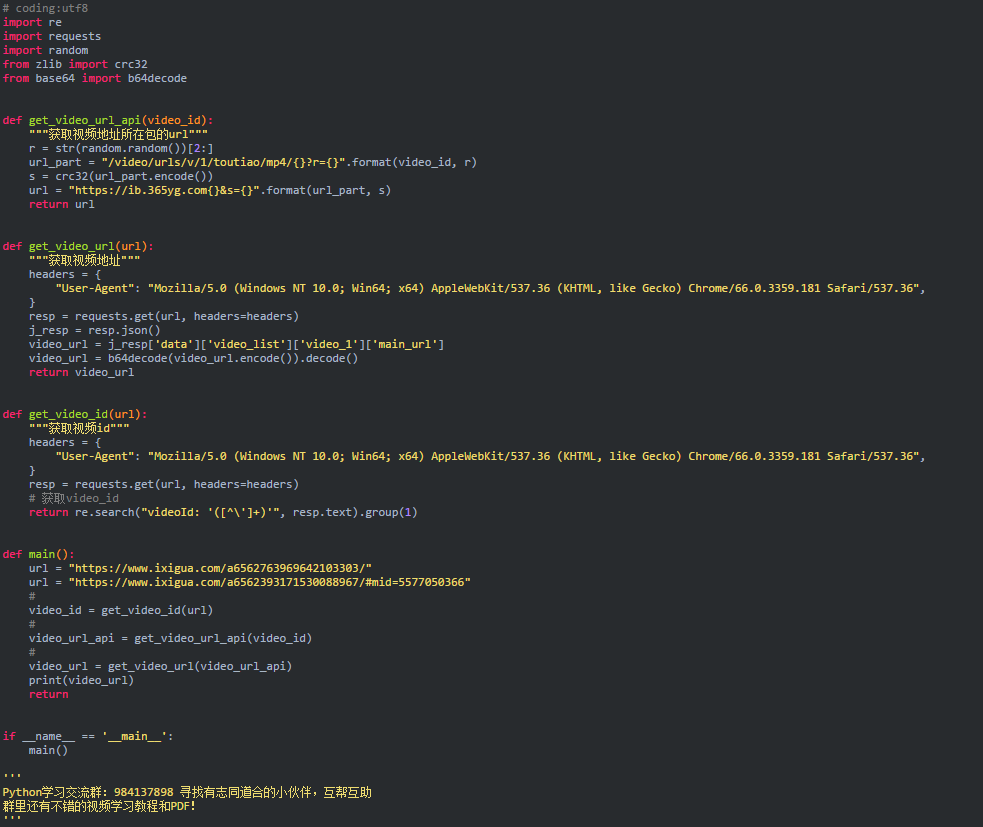

若有收获,就点个赞吧
0 人点赞
