Federated learning (aka collaborative learning) is a machine learning technique that trains an algorithm across multiple decentralized edge devices or servers holding local data samples, without exchanging their data samples.
联邦学习是一种机器学习技术,可在拥有本地数据样本的多个分布式边缘设备或服务器之间训练算法,而无需交换数据样本
联邦学习的起源
业界公认联邦学习的起源来Konevcny,McMahan和Ramage在2015年发表的论文《Federated Optimization: Distributed Optimization Beyond the Datacenter》[1],在这个文章中,来自爱丁堡大学和Google的两个学者提出了在分布式的数据中心中进行联邦优化的算法。接着,2017年McMahan在AISTATS大会上发表了《Communication-Efficient Learning of Deep Networks from Decentralized Data》[2]
这两篇文章奠定了联邦学习的基础,那么为什么要有联邦学习,它的业务价值是什么呢?
新的技术和框架的产生大部分都是为了解决一类业务问题,联邦学习的起源也是这样,联邦学习的产生背景是由于移动服务的兴起。移动服务商为了让用户能够获得更好的使用体验,就需要利用人工智能技术赋能很多场景,比如大家手机里的图库,是不是能够分类更准确,美颜效果更好。但是,这一切都依赖于两个因素,算力和训练数据。
在国内大家对于数据隐私的保护还没有那么强烈,是个应用都要很多的权限,但是在海外,特别是欧洲国家,GDPR的管控是极其严格的,不合法的采集用户隐私数据是会被发的倾家荡产的。所以,如何能够合法合规的利用海量的用户数据进行模型训练,提升模型的准确度呢?
Google提出联邦学习的概念,就是为了解决安卓手机的终端用户在本地更新模型的问题。
联邦学习可以用下图做一个简单的解释: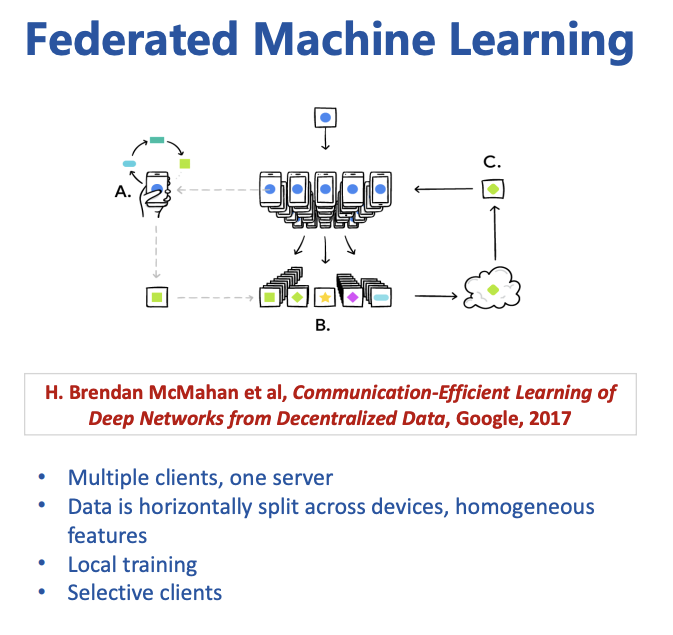
https://img.fedai.org.cn/fedweb/1552916850679.pdf
用户的手机根据使用情况在移动设备上用本地数据训练本地模型(A),然后将许多用户模型进行更新汇总成为(B),当形成对共享模型的共识后,统一更改共享模型(C)。然后重复此过程,从而不断地优化模型算法,并且这个过程充分的利用了所有移动设备的算力。
联邦学习的几个特点:
- 一个服务器,多个客户端
- 数据非均匀的分布在不同位置的不同类型的设备上
- 本地训练
- 客户端是非全量
这个过程中,作为移动服务商,并不会采集用户的数据,不需要把数据传到服务器上,只需要在服务器(Server)和每一个节点(Worker)之间传递参数就可以了,就解决了数据隐私的问题。
这个想法其实不是全新的,因为我们发现它和原来的MapReduce是一样的,就是分布式计算的一种实现。但是,在机器学习领域过去却是不可想象的,因为过去移动设备的计算能力对于运行任何机器学习模型都是有限的。而在2018年后期,配备人工智能芯片的手机越来越多,所以很多的机器学习模型都可以在移动设备上运行了。
联邦学习的三种类型
微众银行(WeBank)在2018年发布了联邦学习的白皮书[3],这个白皮书将联邦学习分为三类,横向联邦学习,纵向联邦学习和迁移联邦学习。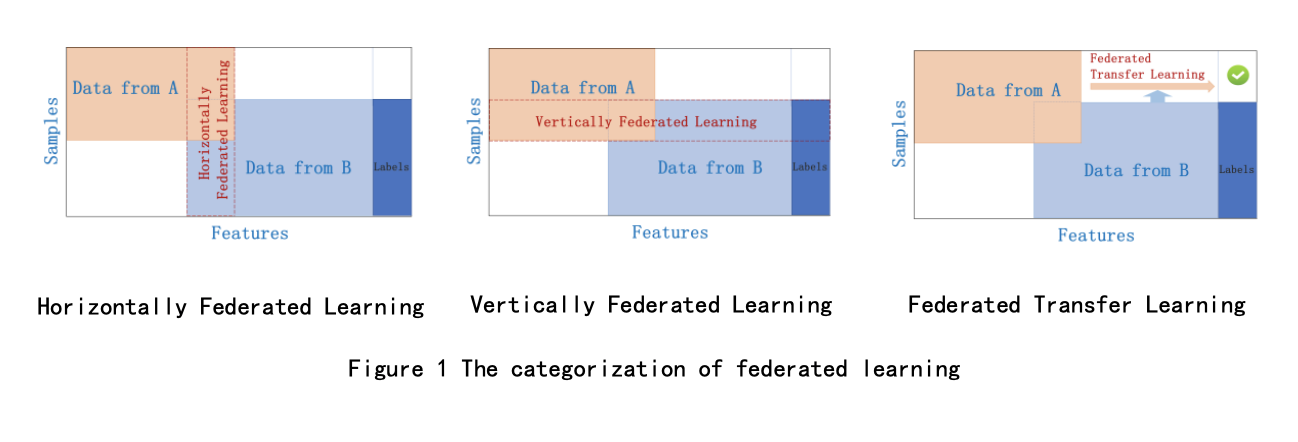
横向联邦学习
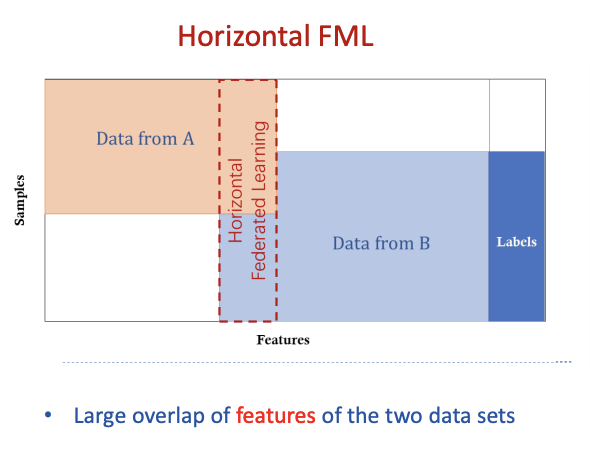
横向联邦学习的特点是业务(特征)相似,但是用户(样本)不同,这种情况下的处理过程一般是这样: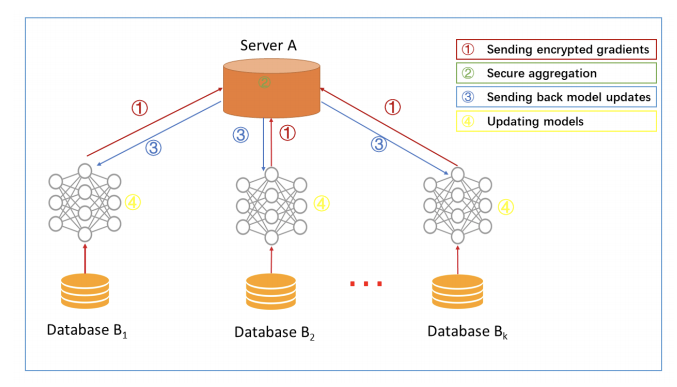
step1:参与方各自从服务器A下载最新模型;
step2:每个参与方利用本地数据训练模型,加密梯度上传给服务器A,服务器A聚合各用户的梯度更新模型参数;
step3:服务器A返回更新后的模型给各参与方;
step4:各参与方更新各自模型。
纵向联邦学习
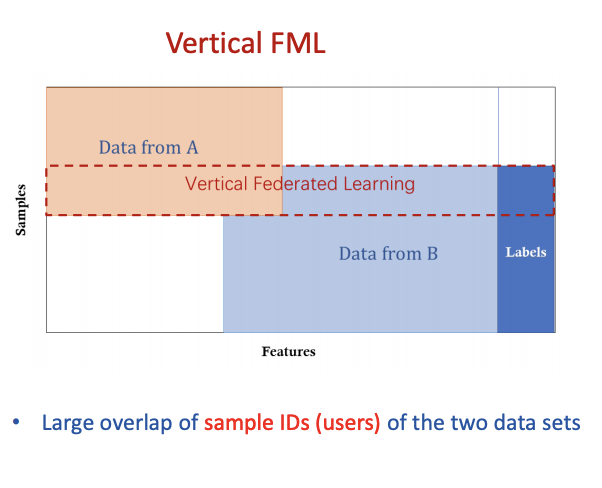
纵向联邦学习的特点是分布式的数据集中大量的用户重复(样本),服务器利用这样的数据来训练对应的用户的模型,但是并不获取相关的数据。
如微众银行在下图所示的场景:
这种情况下,联邦学习的架构如下:
- Step1:服务器向客户端发送公钥
- Step2:客户端间交换中间的训练结果
- Step3:加密汇总后的梯度与损失数据
-
联邦迁移学习
如何能够再不交换数据的前提下进行迁移学习,这是联邦迁移学习解决的问题。适用于参与者间特征和样本重叠都很少的场景,比如不同地区的银行和商超间的联合学习。
联邦迁移学习的典型架构如下:
Step1:双方交换公钥
- Step2:双方分别计算加密和交换中间训练结果
- Step3:双方计算加密后的梯度,加上混淆码发给对方
- Step4:双方解密梯度,并交换,反混淆并更新本地的模型
联邦学习的典型应用场景
由于联邦学习能够解决数据隐私的问题,并且能够充分的利用算力,所以在不同的行业都收到了广泛的应用。移动服务
移动服务是联邦学习的起源行业,所以在移动服务领域,到处都是联邦学习的场景。
比如通过联邦学习,提升图片识别的准确度,提升美颜的效果,训练更加准确地分类器等。医疗健康
医疗健康数据领域⻓期存在“信息孤岛”问题,不同地区甚⾄不同医院间的医疗数据没有互联,也没有统⼀的标准。联邦学习可以绕过医疗机构之间的信息壁垒,不考虑将各⾃数据做合并,⽽是通过协议在其间传递加密之后的信息,该加密过程具有⼀定的隐私保护机制,保证加密后的信息不会产⽣数据泄露。各个医疗机构通过使⽤这些加密的信息更新模型参数,从⽽实现在不暴露原始数据的条件下使⽤全部患者数据的训练过程。物联网
联邦学习本身就是边缘计算的一种体现形式,所以在物联网设备的终端上,训练采集到的传感器状态数据,从而进行异常检测,告警压缩等,也是典型的应用场景。联邦学习与分布式机器学习的区别
从本质上讲,联邦学习也是一种分布式机器学习,但是它与分布式机器学习也有这几个重大的区别。Server与Worker的关系
分布式机器学习的服务器对Worker有着很强的控制力,甚至能够下达指令关闭Worker节点,而在联邦学习的架构中,Server对于Worker的控制力很弱,甚至是可以理解为没有什么控制力。
拿典型的移动服务场景就容易理解了,Worker是分布在全球的不同地区的不同位置的不同设备,什么时候开机,什么时候关机是不受中心节点控制的,所以这种情况下,Server与Worker之间的关系是相对松散的。Worker节点的区别
分布式机器学习的每个节点基本上是均衡的,是有很高的相似乃至一致性的,而在联邦学习的架构里,Worker节点与节点之间的差距是非常大的,是完全随机的。
还是用典型的移动服务场景就很好理解,同样的一个图片训练的联邦学习场景,节点与节点直接的差距是巨大的,有的是最新的华为Mate 40,有的是几年前的手机,所以性能是不一样的。而且由于终端的训练数据集也不一样,有的图片很简单,很少,而有的则很复杂,所以训练的负载也不一样,可能一个训练任务有的节点几秒钟就计算完毕,而有的节点则可能需要几天。成本构成的区别
分布式机器学习架构中节点间的通讯成本很低,主要的成本是计算成本,而在联邦学习的架构中,由于各个节点的不确定性很高,所以服务器与节点间的通信成本要高于传统的分布式机器学习架构。联邦学习趋势
移动设备的不断普及和增加,社会对于数据隐私,数据安全的关注越来越高,联邦学习越来越受重视,也涌现出越来越多的支持联邦学习的框架。
目前主流的联邦学习开源框架如下图所示:
联邦学习白皮书_v2.0.pdf
[1]https://arxiv.org/pdf/1511.03575.pdf
[2]https://arxiv.org/pdf/1602.05629.pdf
[3]https://www.fedai.org/static/flwp-en.pdf

若有收获,就点个赞吧
0 人点赞
