1 图像分类/imgcls1_basic.py
相比上节只是讲基本框架的demo,这次新增了很多新知识点,对常用功能封装组件进行使用:
- 【超参数】集中管理配置
- 【图片数据】的处理,制作dataloader
- 使用torchvision内置的MNIST数据
- 为了简化代码,使用xl库的File、Dir等文件工具。
- 【模型】使用LeNet5
- 【训练阶段】使用ITER,而不是epoch的机制迭代训练
- 这里需要一个无限抽样的TrainingSampler类
- 以及结合ITER,进行周期性保存model权重文件等扩展操作
- 【评价阶段】
- 对预测器XlPredictor进行封装
- 对分类任务评价方法的功能ClasEvaluater进行封装,使用更严谨的f1_score分类指标
import osfrom tqdm import tqdmimport torchfrom torch.utils.data import DataLoaderfrom torchvision import datasets, transformsfrom pyxllib.xl import TicTocfrom pyxlpr.ai.torch import TrainingSampler, LeNet5, XlPredictor, ClasEvaluater # 封装了一些通用组件,简化开发# 零 配置表DATA_DIR = 'datasets' # 数据集所在根目录NUM_CLASSES = 10 # 几分类任务DEVICE = 'cuda' # 在哪个设备运行BASE_LR = 0.01 # 学习率IMS_PER_BATCH = 200 # BATCH_SIZEMAX_ITER = 600 # 训练集迭代次数CHECKPOINT_PERIOD = 100 # 每迭代多少次保存模型STATE_FILE = 'mnist/lenet5_model.pth' # 计划存储权重文件的路径# 一 数据集mnist_transform = transforms.Compose([transforms.ToTensor(),transforms.Resize((32, 32)),])# 训练集数量 60000, 28*28 -> 32*32train_dataset = datasets.MNIST(DATA_DIR, train=True, download=True, transform=mnist_transform)train_loader = DataLoader(train_dataset, batch_size=IMS_PER_BATCH)# 验证集数量 10000, 28*28 -> 32*32val_dataset = datasets.MNIST(DATA_DIR, train=False, transform=mnist_transform)val_loader = DataLoader(val_dataset, batch_size=IMS_PER_BATCH)# 二 训练、推断def train():# 1 准备工作model = LeNet5(NUM_CLASSES)model.to(DEVICE) # 使用cpu,还是哪个gpu训练optimizer = torch.optim.Adam(model.parameters(), lr=BASE_LR) # 学习器# 2 开始训练# 这里不用前面预设的train_loader,而是新建一个可以无限迭代的loaderloader = DataLoader(train_dataset, batch_size=IMS_PER_BATCH,sampler=TrainingSampler(len(train_dataset)))for i, batch_inputs in tqdm(enumerate(loader, 1), 'train', MAX_ITER):# 2.1 训练终止标记/正常训练过程if i > MAX_ITER:breakloss = model(batch_inputs)optimizer.zero_grad()loss.backward()optimizer.step()# 2.2 扩展功能,可以根据i进行某些周期性操作,也可以写一些每次迭代都处理的操作if CHECKPOINT_PERIOD and i % CHECKPOINT_PERIOD == 0:# 确保父级目录存在,也可以用 os.makedirs(str(STATE_FILE.parent), exist_ok=True) 实现os.makedirs(os.path.dirname(STATE_FILE), exist_ok=True)torch.save(model.state_dict(), STATE_FILE)def eval():predictor = XlPredictor(LeNet5(NUM_CLASSES), STATE_FILE, DEVICE, batch_size=IMS_PER_BATCH)print('【训练集】') # 训练集一般不做eval。但为了分析过拟合欠拟合问题,是可以对比验证集看一下的。# 因为要返回gt给下游的eval计算分值,所以要打开return_gt,这跟部署阶段使用模式是不一样的preds = predictor.forward(train_loader, print_mode=True) # 得到所有数据的预测结果evaluater = ClasEvaluater.from_pairs(preds) # 测评器print(evaluater.f1_score('all')) # 训练集看下总精度就行了print('【验证集】')preds = predictor.forward(val_loader, print_mode=True)evaluater = ClasEvaluater.from_pairs(preds)print(evaluater.crosstab()) # 验证集可以详细看下交叉表print(evaluater.f1_score('all'))if __name__ == '__main__':with TicToc(__name__):train()eval()# 不设种子seed的话,每次结果都会不太一样,但这个模型效果基本稳定在0.97# 2021-07-23 10:51:47 time.process_time(): 2.58 seconds.# train: 100%|██████████| 600/600 [00:27<00:00, 21.85it/s]# 【训练集】# eval batch: 100%|██████████| 300/300 [00:12<00:00, 24.59it/s]# {'f1_weighted': 0.9743, 'f1_macro': 0.9743, 'f1_micro': 0.9744}# 【验证集】# eval batch: 100%|██████████| 50/50 [00:02<00:00, 21.51it/s]# pred 0 1 2 3 4 5 6 7 8 9# gt# 0 957 0 3 0 1 2 4 8 2 3# 1 0 1126 0 2 0 2 2 1 2 0# 2 6 5 967 27 4 0 1 13 9 0# 3 0 0 1 992 0 2 0 8 3 4# 4 2 0 1 0 970 0 2 1 0 6# 5 4 0 0 9 0 869 3 1 3 3# 6 8 2 2 0 6 3 935 0 2 0# 7 0 4 1 6 1 0 0 1016 0 0# 8 6 4 1 11 4 3 1 7 935 2# 9 1 6 0 3 21 3 0 14 4 957# {'f1_weighted': 0.9724, 'f1_macro': 0.9723, 'f1_micro': 0.9724}# 2021-07-23 10:52:33 __main__ finished in 45.52 seconds.
注意这里CHECKPOINT_PERIOD只是一个简单的示例,实际运行中,可能要按照model100.pth、model200.pth来保存特定迭代次数后的权重,不要相互覆盖。
在for结束后,还要再存一个modelfinal.pth。eval阶段调用的是modelfinal.pth进行测评。
Macro-F1 Score与Micro-F1 Score - 知乎
weighted:每一类都算出f1,然后按样本量加权平均
macro:每一类都算出f1,然后求平均值(样本少的类依然有同等权重)
micro:按二分类形式直接计算全样本的f1 (效果同常见的acc)
2 MNIST数据可视化
存成图片文件
import osimport os.path as ospimport tempfilefrom tqdm import tqdmfrom torchvision import datasetsDATA_DIR = osp.join(tempfile.gettempdir(), 'datasets')# 验证集数量 10000train_dataset = datasets.MNIST(DATA_DIR, train=False, download=True)for i, (img, label) in tqdm(enumerate(train_dataset, start=1)):file = osp.join(DATA_DIR, f'MNIST/test/{label}/{i:06}.jpg')os.makedirs(osp.dirname(file), exist_ok=True)# 可以调试,查出img是PIL.Image类型,可以直接用save保存成文件# 如果是tensor,可以transforms.ToPILImage转PIL# np.ndarray同理,可以做格式转换,或者使用cv2.imwriteimg.save(file)
(常见)matplotlib
matplotlib是最常见的可视化工具库,其展示图片的方法大概如下:
import matplotlib.pyplot as pltfor i, (img, label) in tqdm(enumerate(train_dataset, start=1)):plt.imshow(img)plt.show()break
还有很多复杂的用法,详见XLPR_Classification,或官方文档。
在需要精细化展示标注,比如标出每个检测框,和对应文本信息,特别是结果可视化的时候,用的会比较多。
(高级)tensorboard
也很常见的可视化工具,原本是tensorflow框架体系的一个工具,但也可以直接pip install tensorboard来使用。
在pytorch中,要用from torch.utils.tensorboard import SummaryWriter,
将模型、各种曲线图数据存储到一个目录中。
然后执行命令行:tensorboard —logdir=”logger_dir”,开启服务,默认在http://localhost:6006/。
详细用法见 XLPR_Classification,不仅可以看曲线图,还能查看模型结构。
(轻便)visdom
参考:visdom · 语雀,是一个专为pytorch设计的可视化工具,数据结构互通。
先做好准备工作
pip install visdom # 安装python -m visdom.server # 开服务, http://localhost:8097
visdom是专为pytorch设计的,所以直接兼容标准的dataset格式[batch_size, chanels, height, width]
from visdom import Visdomvis = Visdom()for x, y in train_loader:vis.images(x * 255, win='训练集数据') # ToTensor会变成0~1,但是visdom是按[0,255]来显示图片的break # 只展示一轮随便看下

可以输出y,或者使用vis.text对比查看标签;
3 visdom在研发中的应用/imgcls2_visdom.py
一般直接看模型最后的指标,就能对着做消融实验改进了。
但有时候遇到bug,或者需要精调模型的时候,需要分析一些训练过程中的细节问题,这时候可以使用一些可视化等辅助工具手段。
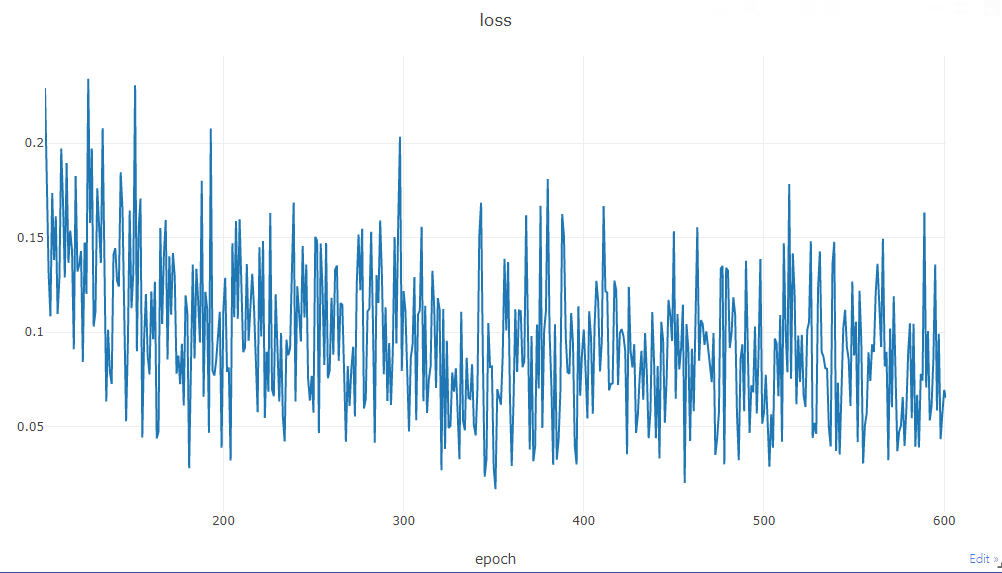
训练过程的loss可视化
之前的各种分类实验,很难把握应该跑几次iter收敛。
此时可以把训练中的loss画出来,能更清楚模型训练中的效果。
只需在train增加几行代码(见红色代码部分,和蓝色解释):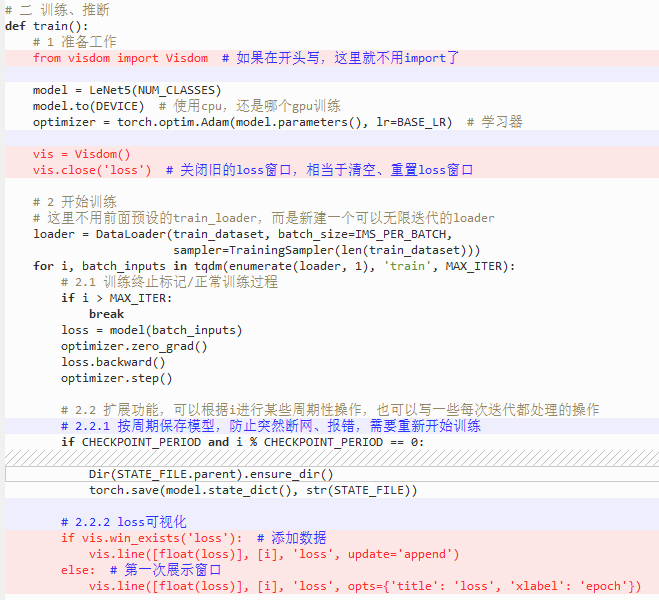
可以看到损失的变化过程,前面100轮在快速下降,后面500轮则没有显著的下降与收敛。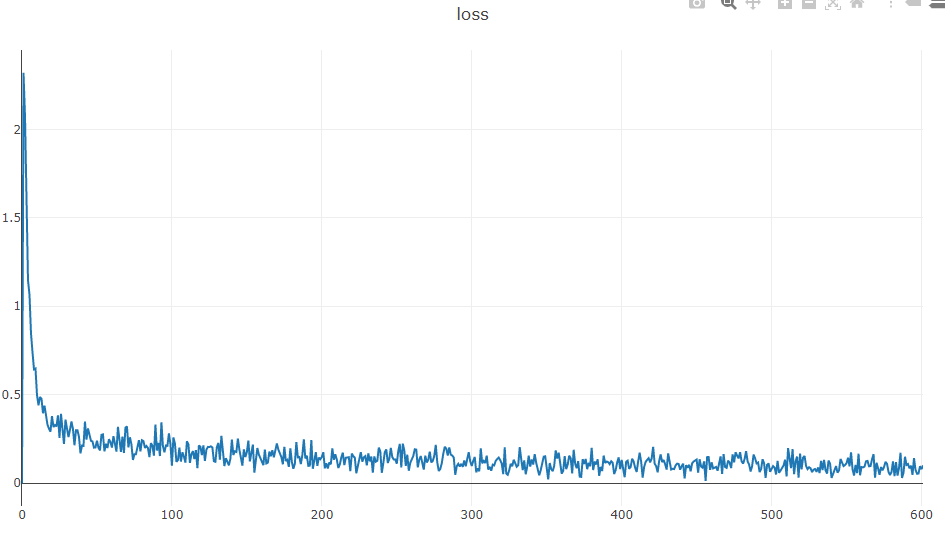
如果嫌刚开始的数值尺度太大,不方便查看后面的具体loss效果,有两种办法:
- 图表右上角有工具栏,可以调整比例查看
- 加判断条件if i > 100,vis.line只在第100次迭代后,才开始展示loss
if i > 100:if vis.win_exists('loss'): # 添加数据vis.line([float(loss)], [i], 'loss', update='append')else: # 第一次展示窗口vis.line([float(loss)], [i], 'loss', opts={'title': 'loss', 'xlabel': 'epoch'})
精度可视化/train和val对比
可以每隔几个大ITER,就对train、val的精度做一轮计算,查看中间结果,这在需要训练好几天的模型中时用的比较多,
也更便于掌握是否过拟合、欠拟合,需要早停等问题。
加个EVAL_PERIOD=200的配置参数,然后完整的train实现如下:
def train():# 1 准备工作from visdom import Visdom # 如果在开头写,这里就不用import了model = LeNet5(NUM_CLASSES)model.to(DEVICE) # 使用cpu,还是哪个gpu训练optimizer = torch.optim.Adam(model.parameters(), lr=BASE_LR) # 学习器vis = Visdom()vis.close('loss')vis.close('eval')# 2 开始训练# 这里不用前面预设的train_loader,而是新建一个可以无限迭代的loaderloader = DataLoader(train_dataset, batch_size=IMS_PER_BATCH,sampler=TrainingSampler(len(train_dataset)))for i, batch_inputs in tqdm(enumerate(loader, 1), 'train', MAX_ITER):# 2.1 训练终止标记/正常训练过程if i > MAX_ITER:breakloss = model(batch_inputs)optimizer.zero_grad()loss.backward()optimizer.step()# 2.2 扩展功能,可以根据i进行某些周期性操作,也可以写一些每次迭代都处理的操作# 2.2.1 按周期保存模型,防止突然断网、报错,需要重新开始训练if CHECKPOINT_PERIOD and i % CHECKPOINT_PERIOD == 0:Dir(STATE_FILE.parent).ensure_dir()torch.save(model.state_dict(), str(STATE_FILE))# 2.2.2 loss可视化if vis.win_exists('loss'): # 添加数据vis.line([float(loss)], [i], 'loss', update='append')else: # 第一次展示窗口vis.line([float(loss)], [i], 'loss', opts={'title': 'loss', 'xlabel': 'epoch'})# 2.2.3 模型精度中间结果可视化(含train和test数据效果对比)if EVAL_PERIOD and i % EVAL_PERIOD == 0:predictor = XlPredictor(model)train_f1 = ClsEvaluater(predictor.forward(train_loader)).f1_score()test_f1 = ClsEvaluater(predictor.forward(val_loader)).f1_score()model.train() # 计算完要主动转回train模式if vis.win_exists('eval'):vis.line([[train_f1, test_f1]], [i], 'eval', update='append')else:vis.line([[train_f1, test_f1]], [i], 'eval',opts={'title': '模型精度', 'legend': ['train', 'test']})
从精度(f1_score)曲线可以看出,虽然后续loss好像变化不大,但模型实际效果确实是有提升的。
看着图(没图的时候其实直接看结果精度分析也行,只是图表能直观展现更多不易发觉的细节问题),
有问题可以对照下述策略改进(吴恩达课程的学习笔记)
- 训练集的精度太低,属于高偏差,欠拟合
- 可以尝试更大的网络模型
- 看loss图,检查是不是没收敛,尝试训练更久一点
- 超参数搜索,尝试修改学习率等参数
- 训练集还不错,但验证集太低,属于高方差,过拟合
- 尝试给模型加正则项
- 寻找更大的训练集
4 改resnet,tensorboard示例/imgcls3_resnet.py
5 选读:部署阶段
from torchvision import transformsfrom pyxllib.xl import XlPath, TicToc, dprint # pip install pyxllibfrom pyxllib.xlcv import xlcv # pip install pyxllib[xlcv]from pyxlpr.ai.torch import LeNet5, XlPredictor # 封装了一些通用组件,简化开发NUM_CLASSES = 10 # 几分类任务IMS_PER_BATCH = 200 # BATCH_SIZESTATE_FILE = XlPath('mnist/lenet5_model.pth') # 计划存储权重文件的路径def deploy():""" 部署阶段开发演示"""# 1 初始化预测器:因为是预测真实数据,没有y标签,可以y_placeholder=-1作为占位符制作dataset数据集# 权重文件支持给url,会自动下载到本地,在部署一些小模型、可公开功能的时候很方便。也方便在云端替换最新版最好的权重文件。# 如果读者写的model.forward前传机制不同,本来batch_inputs就只输入x没有y,则这里不用设置y_placeholder参数numcls = XlPredictor(LeNet5(NUM_CLASSES), STATE_FILE, 'cuda', batch_size=IMS_PER_BATCH, y_placeholder=-1)numcls.transform = transforms.Compose([lambda x: xlcv.read(x, 0), # 我自己的一个类,能自动读取文件、或者转换格式成numpy数据,类似cv2.imread,但比其强大的多transforms.ToTensor(),transforms.Resize((32, 32)),])# 2 使用函数接口功能,执行下游任务# 2.1 这是验证集里的图片,训练集和验证集的数据精度都很高,预测基本没有问题v1 = numcls('test/000031.jpg')dprint(v1)# v1<int>=3,准确返回3# 2.2 这里我们自己手写几个数字试试,存成文件abcde,这些图片接近部署真实场景,尺寸都是随意的,没有固定到32*32v2 = numcls('test/a.jpg')dprint(v2)# v<int>=1,准确识别为1# 2.3 支持批量识别,forward的时候会使用前面设置的batch_size批量前传vals1 = numcls(['test/b.jpg', 'test/c.jpg', 'test/d.jpg'])dprint(vals1)# vals1<list>=[2, 3, 4],b、d、e都正确识别# 2.4 传入numpy数据也行import cv2imgs = [cv2.imread('test/d.jpg'), cv2.imread('test/e.jpg', 0)]vals2 = numcls(imgs)dprint(vals2)# vals2<list>=[4, 5]# 2.5 也支持PIL数据格式from PIL import Imageimg = Image.open('test/e.jpg')vals3 = numcls([img])dprint(vals3)# vals3<int>=[5]if __name__ == '__main__':with TicToc(__name__):deploy()
部署所用测试数据包: test.zip.docx (下载后去掉docx后缀)

若有收获,就点个赞吧
0 人点赞
