这是我个人开发python代码的一些习惯风格,并不是所谓的“标准”要大家都认可遵循,以及读者有更好的点子,欢迎反馈建议,共同进步。
- 代码风格,除了团队开发时极个别需要强制规范的。大部分规则我们往往只能给予建议,而无法给予行动。因为有些规则也谈不上绝对正确,只是说大家风格尽量统一能提高彼此代码可读性,减少一些不必要的麻烦。
- 对于后文描述的内容,读者有看不明白的地方可以先跳过
- 特别还没有太多开发经验的萌新,不要纠结细节或一口吃个胖子,先消化几条直观易懂的就行
- 看不明白代表这个目前还不是你的痛点,或许只有等哪天自己亲自踩过坑了,才愿意从内心真正去接纳改变
- 当然,更鼓励虚心学习的读者,对遇到不懂和质疑的,能积极提出来,跟我们、身边的朋友一同探讨。这样的学习者进步是最快的。
TODO 应该有些工具可以暴力修改风格,统一成一套。就”不存在”代码风格太多的问题了~~
1 Python风格
1.1 基础
1.1.1 Ctrl + Alt + L
在PyCharm,可以用Ctrl + Alt + L,对代码格式化。
1.1.2 PEP8
剩下还有下图这种下划线提示的,鼠标移过去,会提示你的代码有什么瑕疵,一般是一些PEP8规范。
关于PEP8,至少要了解命名规范:
① 变量、函数、模块、包名:lower_with_under。模块、包名尽量不用下划线,除非确实极大提高可读性。
② 类名 CapWords
③ 常量 CAPS_WITH_UNDER
大家平时在opencv-python、pyqt等库见到不遵循这种命名规范,是因为那些库原来是用c++开发的,迁移到python保留了原来c++的名称规范。
注意代码逻辑的拆分,每个函数功能尽量控制在80行内,否则建议拆成多个逻辑的功能组件。
1.1.3 Alt + Enter
很多下划线问题,都可以把鼠标光标停留在上面,按Alt + Enter,不少问题IDE会帮忙自动修正,或者弹出多种参考修正方案的菜单。
1.2 注释
1.2.1 #!/usr/bin/env python3
每个文件开头,统一下述格式的模板,建议使用搜狗输入法等方式来配置宏
#!/usr/bin/env python3# -*- coding: utf-8 -*-# @Author : 陈坤泽# @Email : 877362867@qq.com# @Data : 2020/06/19 15:36
后面这段是个人习惯,不一定要照抄:
from pyxllib.xl import *if __name__ == '__main__':with TicToc(__name__):pass
1.2.2 文档字符串
多勤写文档字符串、文档测试
详见【Python】一、Python基础_代号4101的专栏-CSDN博客 3.3、3.4的内容。
更具体地,建议使用reST格式:
coding style - What is the standard Python docstring format? - Stack Overflow
pycharm中写法:
Specify types with docstrings | PyCharm
1.2.3 代码步骤中标注层次结构
编号格式使用常见的论文章节编号格式,来展现顺序、层级,编号后加一个空格,不要用其他间隔符。
(这个技巧适用于所有编程语言的开发)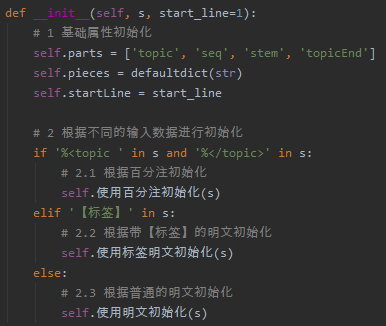
1.3 字符串
勤用f字符串
2 谷歌Python风格指南(中文版)
建议完整阅读一遍中文版后,再看我笔记总结。
中文版:Python语言规范 — Google 开源项目风格指南 (笔者整理时是v2.59版。)
英文原版:styleguide | Style guides for Google-originated open-source projects
TODO 我自己还没读英文原版
2.1 Python语言规范
| 内容 | 概述、补充、我的建议 | 示例代码(TODO 示例不够清晰明了,正反例不足;可以做一套视频详细讲解;格式高亮;根据读者受众不同举特定易理解的业务功能代码;) | 备注 |
|---|---|---|---|
| 1、运行pylint检查代码 | PyCharm涵盖pylint的功能,多关注IDE的警告提示,尽可能修复即可。 | 可以这样注释来抑制告警 # Bad Idea… pylint: disable=redefined-builtin |
|
| 2、仅对包和模块使用导入 | 为了代码清晰度是非常有益的,不过目前我的代码根本没遵守,经常把函数直接导进来用了。 | from sound.effects import echo |
|
| 3、包:使用模块的全路径名来导入每个模块 | 个人非常支持,能避免掉很多不必要的坑,写起来并不会多花太多时间。但如果一开始架构不好,重构起来确实比使用相对路径的写法麻烦的多。 | import sound.effects.echo |
可以用一个脚本自动把包加到全局sitepackages索引,简化一定的部署工作量。 |
| 4、允许在控制流中使用异常,但必须小心 | 不要使用”except:”,一定要尽可能指明具体的错误类型。原文档提到的其他条件要都了解遵守。 | try: pass except ValueError: pass |
|
| 5、避免全局变量 | 如果需要, 全局变量应该仅在模块内部可用, 并通过模块级的公共函数来访问。 | 目前我自己这点也做的很不好 | |
| 6、鼓励使用嵌套/本地/内部类或函数 | def func(): def foo(): … foo() |
||
| 7、简单情况推荐使用列表推导(List Comprehensions) | [x * x for x in range(10)] | ||
| 8、尽量使用默认迭代器和操作符 | for key in adict: … |
||
| 9、按需使用yield生成器 | 注意在生成器函数的文档字符串中使用”yields:”而不是”returns:”. | ||
| 10、lamda函数仅用于单行函数 | |||
| 11、条件表达式仅用于单行函数 | x = 1 if cond else 2 | ||
| 12、鼓励使用默认参数值 | def foo(a, b=None): | 注意默认参数只在模块加载时求值一次. 如果参数是列表或字典之类的可变类型, 这可能会导致问题. | |
| 13、在类中可以用属性(properties)设置轻量级的访问、设置 | class Square(object): … @property def perimeter(self): return self.side * 4 |
||
| 14、尽可能使用隐式False | if not users: |
||
| 15、不要使用过时的语言特性 | words = foo.split(‘:’) |
||
| 16、推荐使用词法作用域(Lexical Scoping)简化代码 | 但要尽量避免写出让人迷惑的代码。我个人一般是结合第6点的嵌套函数使用。 | 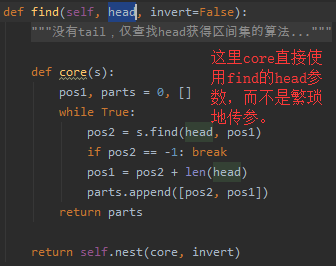 |
|
| 17、如果好处很显然, 就明智而谨慎的使用装饰器 | |||
| 18、多线程不要依赖内建类型的原子性 | 优先使用Queue模块的 Queue 数据类型作为线程间的数据通信方式. (唔~~我自己也是偷懒没管这么多,都是用最简洁的代码来实现多线程~) | ||
| 19、避免使用威力过大的特性 | 使用这些很”酷”的特性十分诱人, 但不是绝对必要. |
2.2 Python风格规范
| 内容 | 概述、补充、我的建议 | 示例代码 | 备注 |
|---|---|---|---|
| 1、不要用分号 | a, b = 1, 2 |
||
| 2、行长度:每行不超过80个字符;不要使用反斜杠连接行 | 我自己也有用反斜杠连接行,要改 | ||
| 3、宁缺毋滥的使用括号 | |||
| 4、用4个空格来缩进代码 | 不要用tab | ||
| 5、空行:顶级定义之间空两行, 方法定义之间空一行 | 个人推荐,用pycharm的格式化工具也可以自动完成:ctrl+shfit+alt+L | ||
| 6、空格:按照标准的排版规范来使用标点两边的空格 | 用pycharm格式化工具可以保证规范性 | ||
| 7、Shebang:程序的main文件应该以#!/usr/bin/python3开始. | 我自己有扩展变型 | ||
| 8、注释:文档字符串,块注释与行注释等 | 三重双引号;以一个标题行开始 | ||
| 9、类继承要显式使用object | 这个为了代码简洁,我个人并没有遵循~ | ||
| 10、字符串:使用列表实现多字符串拼接 | ①个人推荐用format、f字符串代替+、%操作 ②推荐统一用单引号字符串 |
 |
|
| 11、使用with等语句显式关闭文件和sockets | 对于不支持使用”with”语句的类似文件的对象,使用 contextlib.closing() | ||
| 12、TODO注释 | 在不方便识别作者的场景,要养成加上姓名的习惯 | # TODO(Zeke) Change this to use relations. | |
| 13、每个导入应该独占一行 | 顺序分组,每个分组内再字典序排序: ①标准库导入 ②第三方库导入 ③应用程序指定导入 |
import os import sys |
|
| 14、通常每个语句应该独占一行 | |||
| 15、访问控制 | 对于琐碎又不太重要的访问函数, 你应该直接使用公有变量来取代它们 | ||
| 16、命名 | 单下划线前缀保护 双下划线前缀私有 |
||
| 17、Main | 推荐使用if name == ‘main‘ |
2.3 临别赠言
请务必保持代码的一致性
制定风格指南的目的在于让代码有规可循, 这样人们就可以专注于“你在说什么”, 而不是“你在怎么说”.
*3 【个人详细】命名范式
(前缀)分组/动作 + 含义 + (后缀)类型
220221周一16:14版本
- 功能分组,树结构形式的功能分组,类似目录结构那样,按层次前缀命名
- 示例:metric_det、metric_rec、metric_ocr
- 主要用于:函数。全局架构,命名对齐考虑。
- 类型放在后缀
- 示例1:jpg_file、png_file;jpg_num、png_num;print_mode
- 主要用于:变量。局部使用,顺口考虑。
- 注意:尽量完整易读,不要用_n表示整数,而是_cnt、_num
高维数组类命名规范
以item条目为例,
一维数组:items
二维数组:itemgroups,itemgroupd2
三维数组:itemgroupss,itemgroupd3
四维数组:itemgroupsss,itemgroupd4
items转成ndarray,ndim=1
itemgroups同理,转出来ndim=2,所以也可以写成后缀d2
以此类推,可以在group后无限累加s,也可以用d表示层数
*4 【个人详细】功能命名
新旧函数更替、多版本函数(后缀_v1、_v2)
类、函数有多个版本的时候,不要简单的加数字123,而是用v1、v2来更清晰的表明版本号
有可能的话,可以用一个不带v1、v2的作为通用接口名
旧的引使用,如果依赖上下文难修改,可以先改名增加后缀_v1;不带v后缀的直接引用新的v2的实现版本
测试类分组名(用途前缀)
用特定前缀表明用途的函数、类:
demo,演示功能用法,综合性的使用示例,也可能含有test、perf
debug,检查功能有误问题,多用于自己代码的问题检查
test,测试运行效果,多用于标准库、三方库的问题检查
perf,测试性能速度
doc_,文档类函数,一般用于流程介绍,并不适合直接整个函数运行
注意上述几种目的经常是交错复合使用的,一般用其最核心的目的来命名
get/open系列(动作前缀)
| 内存对象 | 推荐用途 | 示例 | 三方库命名 |
|---|---|---|---|
| from_xxx | 从什么类型初始化 | xlcv.from_buffer 尽量不用前缀,比如read_from_buffer, 但已经写的就算了,不用改。 |
|
| to_xxx | 类型转换 | Document.to_fitzdoc | df.to_excel |
| get_xxx | 计算值 | get_device,get_encoding | |
| gen_xxx | 生成数据。 工厂函数工厂类可以写genfunc、gencls。 |
Labelme.gen_shape CocoGtDict.gen_images |
|
| cvt | |||
| build_xxx | 生成一个对象;复杂类构建中,一些组件的初始化 |
| 文件对象 | 推荐用途 | 示例 | 三方库命名 |
|---|---|---|---|
| open | 打开文件 | Image.open | |
| read | 低级的读; pyxllib统一规范read/write, 注意多文件场合要标记复数 |
cv2.imread pd.read_excel |
|
| write | 低级的写 | cv2.imwrite | |
| load | 高级的读 | (fitz)doc.load_page、json.load | |
| save | 高级的写 | (PIL)im.save | |
| create_ | 生成目录 | ||
| unpack、dump |
函数行为精细控制(print_mode)
prt、verbose -> print_mode?
方便跟其他场景组合使用:print_mode、return_mode、run_mode
print_mode只修改是否输出提示信息,以及复杂度(int数值大小)或者模式(str类型),不涉及函数功能本身
return_mode会修改函数返回值的情况
有时候功能和输出会同步处理,此时可以用一个run_mode统一说明
print_mode有时候也可以传入一个logger来代替存储运行细节
其他
在每个模块,用四个_前缀的变量,来对代码进行分类整理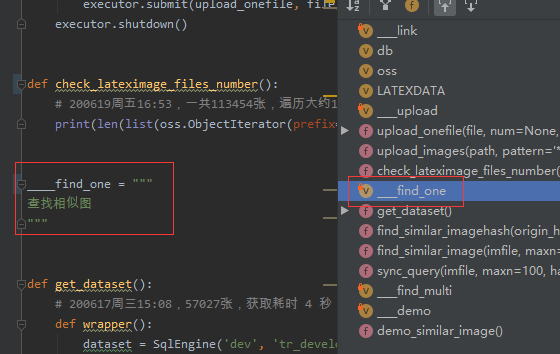
list默认变量名li,当然能用具体的业务逻辑规范命名最好:student_list
英语不太好有命名障碍的,推荐工具CODELF。
Python中的下划线(译文)_chevalier - SegmentFault 思否
如果就想用标准库的名称命名变量,例如id、type,为了防止冲突,习惯加个后缀,例如id、type_。
前缀_,例如_id、_type。(改成前缀,前缀看着顺眼,后缀总是觉得很奇怪)
最好是具体含义加上后缀:student_id、data_type

若有收获,就点个赞吧
0 人点赞
