P4 pytorch基本开发框架_哔哩哔哩_bilibili
通知
大家好,我的《人工智能开发基础》第二次内容大纲见:https://www.yuque.com/xlpr/doai/session4。
本次分享会
1、首先会简单回顾下第一次讲了哪些python基础内容,再做一点简单的补充扩展。
我补充了一个题目,有时间的同学可以试做一下https://www.yuque.com/xlpr/doai/session2最后面的那道doctest考题。复习完第一次分享会内容后,我会讲这题答案。
2、第二次分享会,我先过一下环境配置https://www.yuque.com/xlpr/doai/install-pytorch,然后主要讲pytorch开发一个分类任务的基本框架,和几个组件常见的变种写法 https://www.yuque.com/xlpr/doai/session5。
3、上次其实讲了本来规划两次分享会的内容,我想想组会分享还是讲慢点,要录屏留给以后的新人看。但文档我会尽快写好大家可以提前看。下次组会准备讲的图像分类框架基本完成了https://www.yuque.com/xlpr/doai/session6,有需要的可以结合海礼写的,我们团队的分类框架 https://www.yuque.com/xlpr/code/hrvtof 先学习。
1 整体框架、流程概览

按照研发时间从上到下,分三个阶段:训练、评价、部署。对于大部分研究生而言,掌握前两个阶段即可。
按照程序运行从左到右,也分三个阶段:(加载)数据、(运行)模型、特定阶段操作。
一般拿到个新项目,都是从左上到右下的顺序逐步完成五个组件的功能代码:
① 数据 ② 模型 ③ 损失 ④ 优化器 ⑤ 评价指标
因为是二维结构,从左上到右下其实有很多种走法,具体问题具体分析。
总之做任何一个单元格里的组件时,必须要确保其左边、上面的所有工作都已完成。
2 直播写代码
我们来照着这个表格,实现一个数值二分类的代码。
net:forward、仿函数、call
跳转看torch源码,Structure
演示断点调试
3 完整代码:numcls1_basic.py
数值二分类任务
""" pytorch做分类任务的基本框架(基础版) """from tqdm import tqdm # pip install tqdm,进度条工具import numpy as npimport torchfrom torch import nn, optimdef build_dataloader(n):""" 生成n个数据样本,每个样本是 5个 [0, 6) 的整数按照数值和分成两类, 10<sum(x)<20是1类,其他是0类"""data = np.random.randint(0, 6, [n, 5])dataset = [(np.array(x, dtype='float32'), int(10 < sum(x) < 20)) for x in data]return torch.utils.data.DataLoader(dataset, batch_size=16, shuffle=True)class NumNet(nn.Module):def __init__(self):super().__init__()self.classifier = nn.Sequential(nn.Linear(5, 10),nn.ReLU(),nn.Linear(10, 5),nn.ReLU(),nn.Linear(5, 2),nn.ReLU(),)def forward(self, batched_inputs):x, y = batched_inputslogits = self.classifier(x)if self.training:loss = nn.functional.cross_entropy(logits, y)return losselse:y_hat = logits.argmax(dim=1)return y_hatdef train(epochs=10):# 1 数据、模型、优化器train_num = 5000train_loader = build_dataloader(train_num)model = NumNet()optimizer = optim.SGD(model.parameters(), lr=0.01)# 2 训练for epoch in tqdm(range(epochs), 'epoch'):for batched_inputs in train_loader:loss = model(batched_inputs) # 前向传播optimizer.zero_grad() # 清空之前梯度loss.backward() # 进行该轮梯度反传optimizer.step() # 按指定学习策略,更新网络权重的梯度# 3 保存torch.save(model.state_dict(), 'model.pth')def eval():# 1 数据val_num = 1000val_loader = build_dataloader(val_num)# 2 加载模型model = NumNet() # 初始化模型结构model.load_state_dict(torch.load('model.pth')) # 加载模型权重model.eval() # 进入推断模式# 3 检查分类精度with torch.no_grad():correct_num = 0for batched_inputs in val_loader:y_hat = model(batched_inputs)correct_num += sum(batched_inputs[1] == y_hat)print(f'正确率: {correct_num} / {val_num} ≈ {correct_num / val_num:.2%}')if __name__ == '__main__':np.random.seed(4102)torch.manual_seed(4102) # torch也有随机数种子train()eval()# 在我们自己十卡服务器上运行的结果# epoch: 100%|████████████████████████████████████| 10/10 [00:03<00:00, 3.22it/s]# 正确率: 886 / 1000 ≈ 88.60%
4 总结
实现的代码中,依次对应整体框架中的如下模块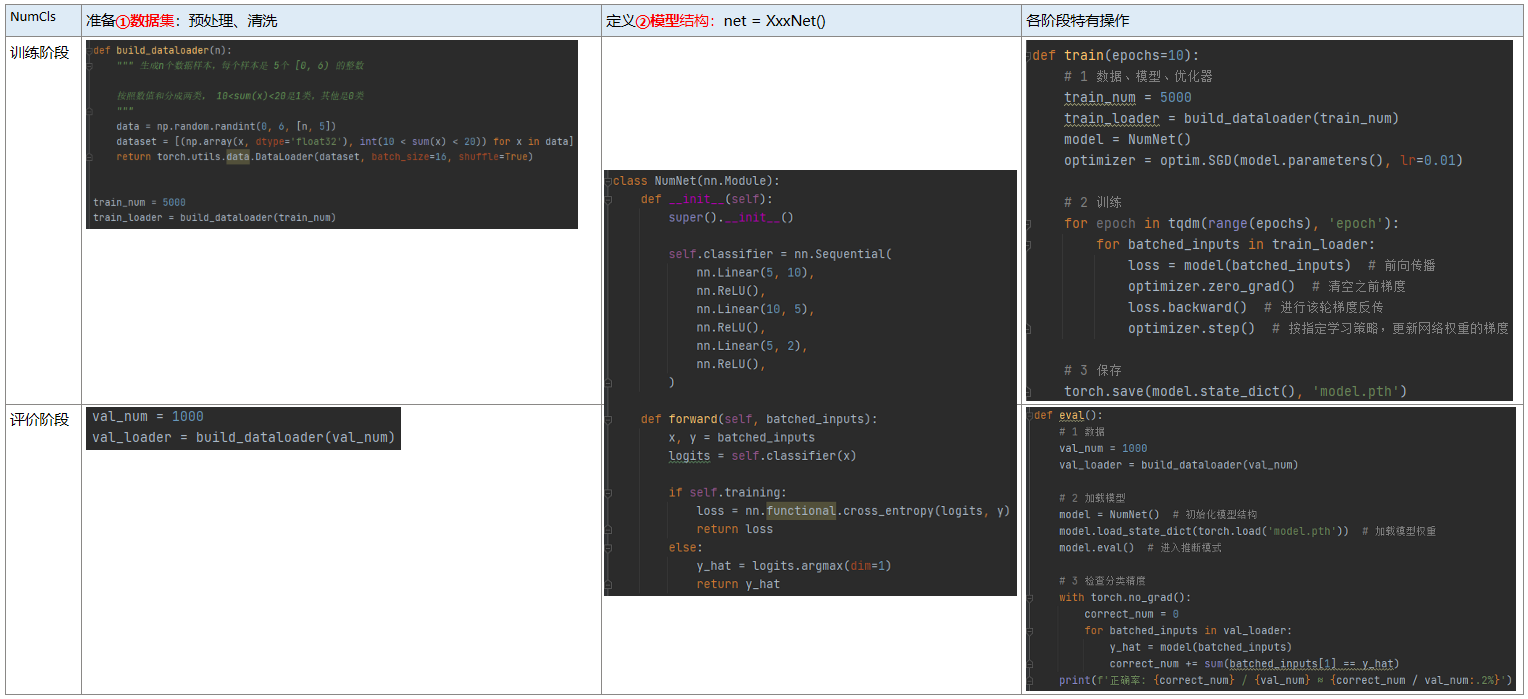

若有收获,就点个赞吧
0 人点赞
