P5.1 pycharm远程运行详解_哔哩哔哩_bilibili
00:16,前文回顾
04:26,按模型思路实现,代码回顾
08:52,pycharm远程配置
22:30,远程配置拓展
26:50,pycharm配置快捷键
28:00,讲解结束
P5.2 pytorch各组件变种写法_哔哩哔哩_bilibili
00:30,Dataset的几种写法
02:20,符号链接
07:20,transforms
15:50,torchvision内置数据集
20:35,标准自定义数据集方法
25:20,DataLoader
30:55,模型,结构定义,初始化权重等概述
33:33,损失、优化器、评价指标
34:45,代码实操
35:00,Dataset、DataLoader
36:50,Model
38:30,device的设置问题
47:20,eval阶段的改进,训练集的精度、crosstab
60:15,总结
第4节里,先从整体上了解整个框架流程,虽然每个组件实际都有很多变种写法,但都是万变不离其宗。
为了让大家能更好理解这些组件,看懂各种开源项目代码,应对各种特殊的任务需求,这里讲下它们常见的变种。
1 数据
1.1 Dataset
使用List-Like数组
见前文示例代码,就是类数组数据结构的内容
torchvision 标准数据格式
特殊格式的数据,例如图像分类任务,已经按下述规范,一类图片放一个目录,共0123四类: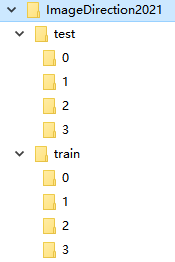
那么可以直接使用torchvision.datasets.ImageFolder来生成Dataset:
from torchvision import datasets, transformsfrom torch.utils.data import DataLoader# 图片预处理常见写法img_preprocess1 = transforms.Compose([ # 和nn.Sequential很像,这是对图片的组合操作transforms.Grayscale(), # 转灰度图transforms.Resize((512, 512)), # 调整尺寸,一般都是传固定尺寸的图片输入模型transforms.ToTensor(), # 注意这个操作不仅会做类型转换,还会把数值重映射到[0~1]])def img_preprocess2(img):""" img_preprocess1、img_preprocess2 效果相同在复杂场景,可以使用img_preprocess2的形式,自定义更灵活的预处理操作:param im: PIl格式的图片:return: tensor数据"""img = img.convert('L')img = img.resize((512, 512))img = transforms.functional.to_tensor(img) # 转tensorreturn imgtrain_dataset = datasets.ImageFolder('C:/Users/chen/AppData/Local/Temp/ImageDirection2021/train',transform=img_preprocess1)train_loader = DataLoader(train_dataset, batch_size=4)# Run with Python Console to debugg = iter(train_loader)x, y = next(g) # 注意能同时获得数据x,和类别标签y
torchvision 内置数据集
MNIST、COCO等数据集,内置了专门的datasets类,可以直接使用,还能使用download参数自动下载。
import torchfrom torchvision import datasets, transformsbatch_size = 200dst_dir = r'/home/chenkunze/data'train_loader = torch.utils.data.DataLoader(datasets.MNIST(dst_dir, train=True, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)test_loader = torch.utils.data.DataLoader(datasets.MNIST(dst_dir, train=False, download=True,transform=transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.1307,), (0.3081,))])),batch_size=batch_size, shuffle=True)
可以打断点调试,以及可视化查看数据(把数据写到文件):
from cv2 import imwritefor x, y in train_loader:x.shape # [batch, channel, height, width]y.shape # [batch]imwrite('aaa.jpg', x[0, 0].numpy()*255) # ToTensor的时候变成[0, 1],要放大回255break

(最常见)从 torch.utils.data.Dataset 继承/自定义数据集
Datasets & Dataloaders — PyTorch Tutorials 1.9.0+cu102 documentation
from torch.utils.data import Datasetclass NumDataset(Dataset):def __init__(self, n):self.data = np.random.randint(0, 6, [n, 5])def __len__(self):return len(self.data)def __getitem__(self, index):x = self.data[index]y = int(10 < sum(x) < 20)# + transforms,数据预处理,转np.ndarray或torch.tensor结构# + data augment,数据增强return torch.FloatTensor(x), ytrain_loader = DataLoader(NumDataset(5000), batch_size=16)val_loader = DataLoader(NumDataset(1000), batch_size=16)
1.2 DataLoader
讲一些 我知道的参数 大家可能用得到的参数
shuffle
默认False。
在训练集一般都设为True,要把数据打乱,否则训练可能会出问题,因为每个类别的数据都太集中,很容易陷入了局部最优解或得到各种奇怪的模型效果。
num_workers
获取每个数据,或者说读图很慢的时候,可以尝试多线程读取数据。
但因为GIL锁的原因,不一定数量越多越快,甚至有可能开多线程比单线程还慢,
可以多测试下,有用再调合适的线程数。
(图片较大,属于IO阻塞的时候才有用,如果是增广处理多,CPU运算密集,这里开多线程没什么作用)
sampler
可以自定义数据的迭代获取过程。
使用sampler的时候,shuffle功能自动失效。
例如下例只有40个样本,但使用sampler变成了长度为100的抽样过程。
num = 40data = np.random.randint(0, 6, [num, 5])dataset = [(np.array(x, dtype='float32'), int(10 < sum(x) < 20)) for x in data]loader = torch.utils.data.DataLoader(dataset, batch_size=16,sampler=map(lambda x: x % num, range(100)))for batched_inputs in loader:x, y = batched_inputsprint(len(x))# 16# 16# 16# 16# 16# 16# 4
这有什么用呢?
比如有些框架不是按epoch设置训练次数的,而是按batch的iter迭代次数。
这样的好处是可以统一根据ITER变量,决定何时做快照checkpoint存储模型,何时衰减学习率。
此时需要写一个无限循环,在读完一次epoch后仍然能从头继续获取数据,
而由外部MAX_ITER决定训练何时停止。
from itertools import cycleimport numpy as npimport torchfrom torch.utils.data import Datasetnum = 40data = np.random.randint(0, 6, [num, 5])dataset = [(np.array(x, dtype='float32'), int(10 < sum(x) < 20)) for x in data]loader = torch.utils.data.DataLoader(dataset, batch_size=16,sampler=cycle(range(num)))MAX_ITER = 10for iter_num, batched_inputs in enumerate(loader):if iter_num >= MAX_ITER:breakx, y = batched_inputsprint(len(x))
这里只是一个简单的示例,实际还要考虑随机选取、对齐等问题,一般会写成一个TrainingSampler类,下节有使用示例。
2 模型
2.1 init定义模型结构
一层层撸
import torchimport torch.nn as nnimport torch.nn.functional as Fclass Net(nn.Module):def __init__(self):super(Net, self).__init__()# 1 input image channel, 6 output channels, 5x5 square convolution# kernelself.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)# an affine operation: y = Wx + bself.fc1 = nn.Linear(16 * 5 * 5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):# Max pooling over a (2, 2) windowx = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))# If the size is a square you can only specify a single numberx = F.max_pool2d(F.relu(self.conv2(x)), 2)x = x.view(-1, self.num_flat_features(x))x = F.relu(self.fc1(x))x = F.relu(self.fc2(x))x = self.fc3(x)return xdef num_flat_features(self, x):size = x.size()[1:] # all dimensions except the batch dimensionnum_features = 1for s in size:num_features *= sreturn num_featuresnet = Net()print(net)
个人不推荐这种写法,在层数多的时候,维护很麻烦。
只是在初学阶段可以了解下,更清楚nn.Sequential内部的运行过程,也方便调试检查一层层网络运行效果。
nn.Sequential
除了前面展示的把所有层都写到Sequential里,在模型比较庞大复杂的时候,可以分多个Sequential组件来组装整体模型结构:
class ClsNet(nn.Module):def __init__(self, n_classes=4):super().__init__()self.feature_extractor = nn.Sequential(nn.Conv2d(in_channels=1, out_channels=6, kernel_size=3, stride=1),nn.LeakyReLU(inplace=True),nn.AvgPool2d(kernel_size=4),nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1),nn.LeakyReLU(inplace=True),nn.AvgPool2d(kernel_size=4),nn.Conv2d(in_channels=16, out_channels=120, kernel_size=3, stride=1),nn.LeakyReLU(inplace=True),nn.AvgPool2d(kernel_size=4),)self.classifier = nn.Sequential(nn.Linear(in_features=5880, out_features=84),nn.LeakyReLU(inplace=True),nn.Linear(in_features=84, out_features=n_classes),)def forward(self, batched_inputs):x = batched_inputs[0]x = self.feature_extractor(x)x = torch.flatten(x, 1)logits = self.classifier(x)...
2.2 初始化权重
pytorch的Linear、Conv2d的权重(weights)都有默认的初始化方法。
但也可以自己设置初始化方法。
python - How to initialize weights in PyTorch? - Stack Overflow
2.3 设置device
pytorch默认是在cpu上运行,实际项目中数据和模型都很大,可以使用.to(‘cuda’)等方式放到gpu上执行,速度更快的多(CPU、GPU性能对比)。
模型是有权重矩阵的,数据也是矩阵,矩阵和矩阵运算,必须在同一个硬件设备上,如果跨设备运算会报错: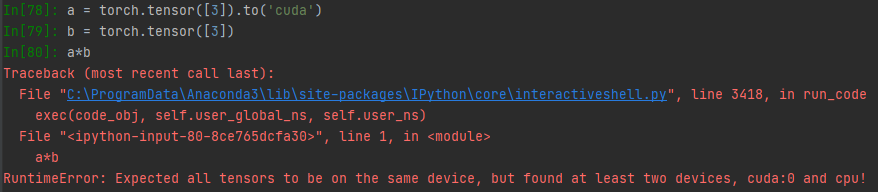
为了确保model和data(x、y)在同一个设备上,常见的写法是在外部确定device,数据也是在forward外部就放置到指定设备:Quickstart — PyTorch Tutorials 1.9.0+cu102 documentation
我个人则是习惯这样写
class NumNet(nn.Module):def forward(self, batched_inputs):""" batched_inputs 总是输入 [x, y] 的结构eval阶段可能没有y,eval阶段也用不到y,可以输入[x, None]"""device = next(self.parameters()).devicex = batched_inputs[0].to(device)logits = self.classifier(x)...def train(epoch=10):model = NumNet()# 在哪个环境运行:默认是'cpu',其他还有 'cuda' 'cuda:0','cuda:1','cuda:2',...model.to('cuda')...
注意第6行,实时获取模型权重矩阵所在的device,将输入的batched_inputs数据放到对应的device。
这在多卡运行等某些情况下有妙用,能省掉很多复杂的代码设计过程。
缺点则是每次要获取下self.parameters()会多一点点时间开销。
2.4 forward写法
常见的forward是不传入y,且只返回logits的,loss和y_hat(pred)在外部实现:


我在detectron2框架中学习到,nn.Module有个成员变量training可以记录当前是train还是eval阶段,从而把不同阶段需要的特定操作,封装到forward中统一实现,好处是
① 能大大简化下游任务代码开发量
② 把损失和推断的写法统一集中到了Net定义中,统一管理,这样整体代码组织框架会清晰简洁很多
(如何切换模式)
2.5 总结
模型结构设计上,我在forward做了较大调整,为了简化上下游工作量,一定程度违背了“高内聚低耦合”的理念。
实际开发中,大家要根据自己的需求灵活变通调整,不要执着于特定的一种设计模式。
3 损失
除了在forward直接使用损失函数,也可以在init初始化一个criterion判别器来在forward使用。
class NumNet(nn.Module):def __init__(self):...self.criterion = nn.CrossEntropyLoss()def forward(self, batched_inputs):...if self.training:loss = self.criterion(logits, y)...
回归任务,均方差损失:nn.MSELoss,nn.functional.mse_loss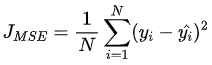
实际项目中,往往会组合,对多种基本损失求和成一个综合的损失值。
如何设计好的损失,也是大家在科研中可以尝试创新和突破的地方。
4 优化器
常见优化器:SGD、Adam
最常见的就是optim.SGD了,不过实际项目中,我一般优先无脑选optim.Adam,关于Adam的具体原理,推荐大家看吴恩达deeplearning.ai - 课程,《改善深层神经网络:超参数调试、正则化以及优化》中的详细介绍。
简单的说,就是使用指数加权平均,来减小无关维度特征的影响,加快学习速度,在大部分情况下,都比SGD更加有效的多。
Adam算法有几个超参数,除了学习率可以改改试试,其他全部采用默认值就行了。
注意优化器只是决定权重的学习率,梯度的更新程度的,
无论前面使用了多少种损失,最后只要一个优化器就够了。
from torch.optim import lr_scheduler
有时候使用优化器是不够的,我们可能需要每训练一段时间后,按比例缩小学习率。
此时需要再加一个学习策略的组件,具体用法可以参考后文推荐的海礼的分类框架代码中,有使用到学习策略。
5 评价指标
多分类还有更精细的F1指标:详解sklearn的多分类模型评价指标 - 知乎
一般具体的细分研究领域,都有专门的评价指标,官方也有提供脚本工具,比如:
文本检测有icdar2013、deteval等指标
目标检测常用coco指标:pycocotools:评测指标 · 语雀
6 增强版代码:numcls2_enhance.py
""" pytorch做分类任务的基本框架(加强版) """from tqdm import tqdm # pip install tqdm,进度条工具import numpy as npimport pandas as pdimport torchfrom torch import nn, optimfrom torch.utils.data import Dataset, DataLoaderfrom pyxllib.xl import TicToc # pip install TicToc,就一个地方用到了,不想安装的删掉TicToc就行class NumDataset(Dataset):def __init__(self, n):self.data = np.random.randint(0, 6, [n, 5])def __len__(self):return len(self.data)def __getitem__(self, index):x = self.data[index]s = sum(x)if s < 12:y = 0elif s < 15:y = 1else:y = 2# + transforms,数据预处理,转np.ndarray或torch.tensor结构# + data augment,数据增强return torch.FloatTensor(x), ytrain_loader = DataLoader(NumDataset(5000), batch_size=16)val_loader = DataLoader(NumDataset(1000), batch_size=16)class NumNet(nn.Module):def __init__(self):super().__init__()# 1 模型结构self.classifier = nn.Sequential(nn.Linear(in_features=5, out_features=10),nn.LeakyReLU(),nn.Linear(in_features=10, out_features=5),nn.LeakyReLU(),nn.Linear(in_features=5, out_features=3),nn.Sigmoid(),)# 2 初始化权重def init_weights(m):if type(m) == nn.Linear:torch.nn.init.xavier_uniform_(m.weight)m.bias.data.fill_(0)self.apply(init_weights)def forward(self, batched_inputs):""" batched_inputs 总是输入 [x, y] 的结构eval阶段可能没有y,eval阶段也用不到y,可以输入[x, None]"""device = next(self.parameters()).devicex = batched_inputs[0].to(device)logits = self.classifier(x)if self.training:y = batched_inputs[1].to(device)loss = nn.functional.cross_entropy(logits, y)return losselse:y_hat = logits.argmax(dim=1)return y_hatdef train(epochs=10):# 1 加载模型model = NumNet()model.to('cuda') # 在哪个设备运行:默认是'cpu',其他还有 'cuda' 'cuda:0','cuda:1','cuda:2',...optimizer = optim.Adam(model.parameters())# 2 训练for epoch in tqdm(range(epochs), 'epoch'):for batched_inputs in train_loader:loss = model(batched_inputs) # 前向传播optimizer.zero_grad() # 清空之前梯度loss.backward() # 进行该轮梯度反传optimizer.step() # 按指定学习策略,更新网络权重的梯度# 3 保存torch.save(model.state_dict(), 'model.pth')def eval():# 1 加载模型model = NumNet() # 定义模型结构model.load_state_dict(torch.load('model.pth')) # 加载模型权重model.eval() # 进入推断模式# 2 训练集的正确率with torch.no_grad():correct_num = 0for batched_inputs in train_loader:y_hat = model(batched_inputs)correct_num += sum(batched_inputs[1] == y_hat)print(f'训练集正确率 {correct_num} / {len(train_loader.dataset)} ≈ {correct_num / len(train_loader.dataset):.2%}')# 3 验证集的精度with torch.no_grad():gt, pred = [], []for batched_inputs in val_loader:y_hat = model(batched_inputs)gt += batched_inputs[1].tolist()pred += y_hat.tolist()df = pd.DataFrame.from_dict({'gt': gt, 'pred': pred})print('验证集各类别出现次数(行ground truth,列pred):')print(pd.crosstab(df['gt'], df['pred']))correct_num = sum(df['gt'] == df['pred'])total = len(df)print(f'正确率: {correct_num} / {total} ≈ {correct_num / total:.2%}')if __name__ == '__main__':with TicToc(__name__):train()eval()# 2021-07-16 07:10:30 time.process_time(): 1.5 seconds.# epoch: 100%|████████████████████████████████████| 10/10 [00:11<00:00, 1.17s/it]# 训练集正确率 4745 / 5000 ≈ 94.90%# 验证集各类别出现次数(行ground truth,列pred):# pred 0 1 2# gt# 0 382 13 0# 1 5 263 25# 2 0 11 301# 正确率: 946 / 1000 ≈ 94.60%# 2021-07-16 07:10:50 __main__ finished in 19.88 seconds.
7 海礼的XLPR_Classification
进阶、更完整的,接近实战级别的图像分类任务开发框架,大家可以看海礼写的这篇:
ImageClassification(basis) · 语雀
8 补充资料
tensor相关操作的笔记资料:
ch04 PyTorch基础教程 1.79h · 语雀
ch05 PyTorch进阶教程 1.65h · 语雀
有兴趣的同学可以看下,整理了平时被人问到的一些问题的回答
PyTorch · 语雀
这是我在占秋基础上整理的文字组部分数据集清单:
OCR数据集 · 语雀(仅团队内成员可查看)

若有收获,就点个赞吧
0 人点赞
