P2 工程化基础_哔哩哔哩_bilibili
00:05 ,工程方法重写,usr/bin脚本头
02:45 ,if name == ‘main‘
06:40 ,各种下划线含义,file
14:30 ,封装函数,select_annotations,函数注释
16:55 ,变量类型申明概述
19:30 ,doctest
23:45 ,字符串,r字符串
30:20 ,f字符串
33:06 ,不要过度注释
33:40 ,splitcocodata
35:55 ,assert断言
37:44 ,抽象出数据拆分功能
43:37 ,下标用浮点数的bug
46:00 ,个人习惯对__main套with TicToc,支持出错情况下的计时
47:35 ,补充:tests,ujson,jupyter运行顺序
54:40 ,random伪随机数原理,种子作用
58:20 ,in-place原地操作,list.sort与sorted(list)区别
64:10 ,args,*kwargs,打包解包
前面我们探索,分析了解决问题的基本思路、算法。
现在我们尝试用更工程化、规范的代码求解该问题。
1 基本框架
#!/usr/bin/env python3# -*- coding: utf-8 -*-# @Author : 陈坤泽# @Email : 877362867@qq.com# @Date : 2021/07/14 10:00
if name == ‘main‘:
Python中的下划线(译文) - SegmentFault 思否
筛选函数的封装
函数的注释
:param注释
Specify types with docstrings | PyCharm
代码的运行顺序;dprint
(jupyter运行顺序)
2 字符串
字符串的几种写法
r字符串(常用于windows路径)与f字符串(扩展学习资料)
字符串的拼接
3 doctest
不同run技巧
扩展:detectron2的tests,不太重要,有兴趣的自己放大图片看~
4 定义函数/传参/打包解包
函数的参数 - 廖雪峰的官方网站
args,*kwargs
解包操作(return多值也是解包操作)

5 随机数
seed种子的含义,基本原理 y=(a*x+b)%c,与作用
shuffle随机打乱
in-place原地操作(sort、sorted区别;pandas操作)
6 完整代码/xlpr2021_splitdata.py
#!/usr/bin/env python3# -*- coding: utf-8 -*-# @Author : 陈坤泽# @Email : 877362867@qq.com# @Date : 2021/03/28""" 本代码是XLPR 2021级研究生编程考核题的参考答案【教学】每个脚本的第一个三引号字符串,可以对脚本进行一个整体的介绍"""import jsonimport randomdef select_annotations(annotations, image_ids):""" 筛选出对应图片的annotations【关于函数注释】1、py的函数标准注释方法,要写在内部开头三引号字符串里2、并建议第一行写功能摘要3、:param这种字眼是pycharm自动生成的标准注释结构有些特别简单的函数,也没必要非把每个参数、return都解释一遍注释本身也有维护成本,有时候代码改了,但注释没改,会给其他使用者带来更大的迷惑性和误导【关于封装】因为这段“很简单”,本函数可以选择不封装,但封装后代码可读性会略强些。但写代码还是要注意不要“过度封装”,何谓过度封装一两句话讲不清,要自己多写代码、多学习别人、开源的优秀代码去感悟。本函数也可以选择直接嵌套在 split_coco_data 里,对外隐藏,py支持在函数里定义函数【doctest】这里是doctest文档测试,不仅是使用示例,也是一个测试点。这个功能只有按规范在三引号字符串里写才有。>>> annotations = [{'image_id': 1, 'box_id': 1}, {'image_id': 1, 'box_id': 2}, {'image_id': 2, 'box_id': 3}]>>> select_annotations(annotations, {1, 3})[{'image_id': 1, 'box_id': 1}, {'image_id': 1, 'box_id': 2}]"""# 简单的for循环和if操作,可以用“列表推导式”写return [an for an in annotations if (an['image_id'] in image_ids)]def split_coco_data(file, parts, *, shuffle=True):""" 数据拆分器,这个数据是coco格式,所以称为coco_data:param file: 数据文件,用json格式存储着coco格式的字典含有images、annotations、categories三个字段本参数也可以设计为传入data字典 (这段看不懂没关系,可以假装不存在)但由于random.shuffle是in-place原地操作,为了避免修改原始数据,或者要多一步繁琐的copy操作,把读文件也封装了。这样这个函数就是完全独立的一个功能组件,不会对外部产生任何难以预知的影响。:param dict parts: 每个部分要拆分、写入的文件名,以及数据比例py≥3.6的版本中,dict的key是有序的,会按顺序处理开发者输入的清单这里比例求和可以不满1,但不能超过1:param bool shuffle: 是否打乱原有images顺序"""# 1 读入data (使用编号注释对代码逻辑分块,能大大提高可读性)with open(file, 'r') as f:data = json.load(f)if shuffle: # 是否打乱应该设计为一个可选参数,可能会存在某些特殊场合需要维持原数据顺序random.shuffle(data['images'])assert sum(parts.values()) <= 1, '比例和不能超过1' # 为了工程鲁棒,常用assert进行简单的规范检查# 2 生成每一个部分的文件total_num, used_rate = len(data['images']), 0 # 注意py可以这样在一行赋值多个变量 (这个本质是“解包”操作)for k, v in parts.items():# 2.1 选择子集图片 (代码块出现嵌套逻辑,可以用2.1、2.2的子编号格式来表达)images = data['images'][int(used_rate * total_num):int((used_rate + v) * total_num)]# 注意这里存成了哈希索引的set集合类型,提高检索效率,算法整体复杂度只有O(n)# 如果set是树结构二分查找,复杂度是O(n*log n)# 有人用双循环检索的话,复杂度是O(n^2),速度就很慢# 怎么方便、定量、严谨分析算法性能,可以参考前面讲的pyxllib库的TicToc、PerfTest工具image_ids = {im['id'] for im in images} # 改成花括号,列表推导式也能直接生成set类型# 2.2 生成新的字典part_data = {'images': images,'annotations': select_annotations(data['annotations'], image_ids),'categories': data['categories']}# 2.3 写入文件# f字符串:f'{k}.json' 等价于 str(k) + '.json'with open(f'{k}.json', 'w', encoding='utf8') as f:json.dump(part_data, f)# 2.4 更新使用率used_rate += vif __name__ == '__main__':# 不要把执行代码放在外面,养成好习惯放在if __name__ == '__main__'里面,并对有一定规模的代码都封装成函数split_coco_data('publaynet.json', {'train': 0.6, 'val': 0.2, 'test': 0.2})
7 留个题目给大家
先尝试在IDE中对这个函数执行doctest:
def add(a, b):""">>> add(3, 4)7>>> add(-3.5, 5)1.5>>> add('hello,', 'world!') # 鸭子类型,输入字符串也可以拼接'hello,world!'>>> add('hello\t', 'world!')'hello\tworld!'"""return a + b
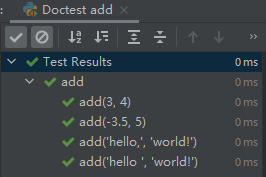
然后分析为什么这样写测试行不通,应该如何修改?
import redef add(a, b):""">>> add(r'hello\t', 'world!')'hello\\tworld!'在add函数不一定非要测add函数的功能,其实是可以检查任意表达式的。例如,正则的测试,也会有类似问题:>>> re.sub(r'\\+', '', r'ab\\c\d\t') # 删除字符串中的所有斜杠'abcdt'"""return a + b

甚至打开Python Console会发现”没问题”啊,为什么doctest过不了?

若有收获,就点个赞吧
0 人点赞
