波士顿房价预测
本文以经典的波士顿房价预测模型为例,展示使用NumPy进行模型训练的过程。
关于波士顿房价数据集的说明:
波士顿房价预测是一个经典的机器学习任务,类似于程序员世界的“Hello World”。和大家对房价的普遍认知相同,波士顿地区的房价是由诸多因素影响的。该数据集统计了13种可能影响房价的因素和该类型房屋的均价,期望构建一个基于13个因素进行房价预测的模型,如下图所示。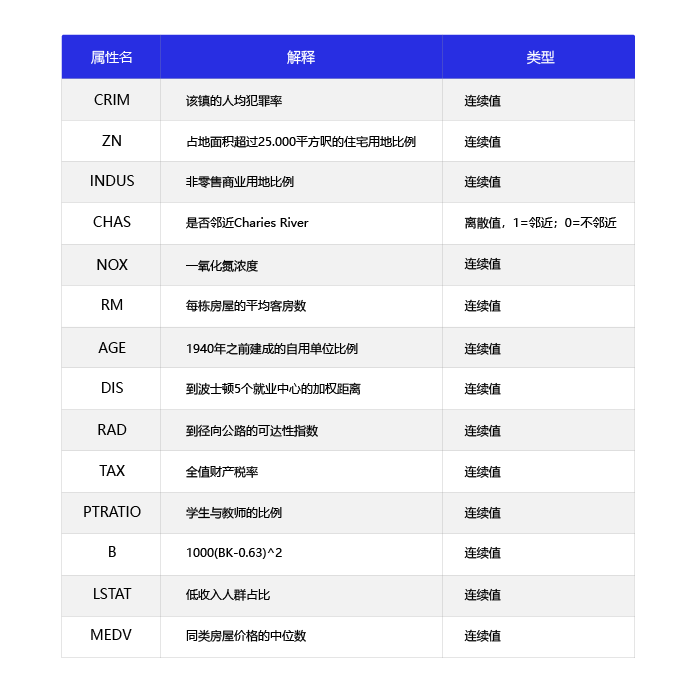
其数据集 housing.data 格式如下: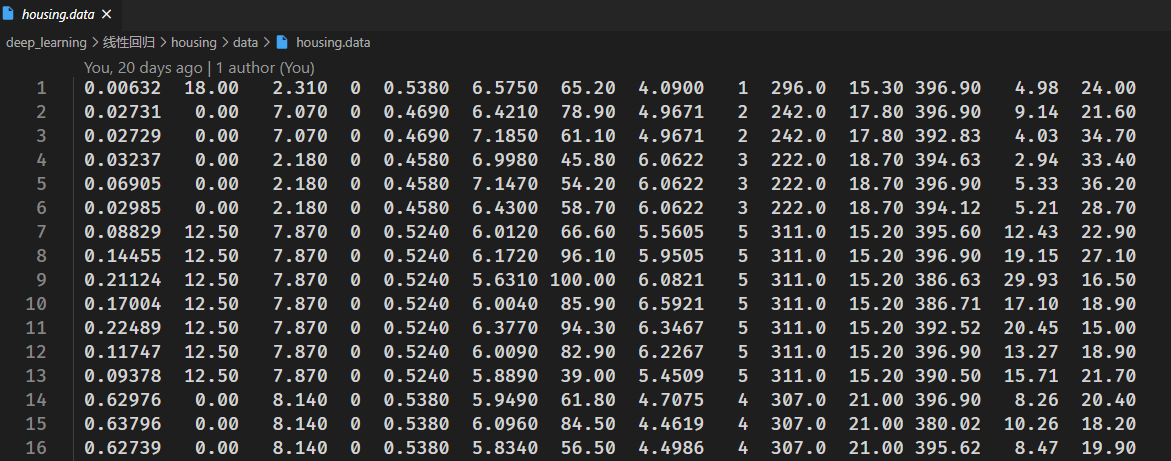
每一行的前13列是影响房价的13个因素(对应上表),最后一列是真实房价。
梯度下降
经典的四步训练流程:前向计算->计算损失->计算梯度->更新参数
# 导入需要用到的packageimport numpy as npimport json# 使用matplotlib将两个变量和对应的Loss作3D图import matplotlib.pyplot as plt%matplotlib inline# 从文件导入数据def load_data(datafile):data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值,平均值maximums = training_data.max(axis=0) # 指定 axis=0 计算每列的最大值minimums = training_data.min(axis=0) # 指定 axis=0 计算每列的最小值avgs = training_data.mean(axis=0) # 指定 axis=0 计算每列的平均值# 对数据进行归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_dataclass Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.# 前向计算def forward(self, x):return np.dot(x, self.w) + self.b# 计算损失值,使用均方误差def loss(self, z, y):return np.sum((z - y) ** 2) / (z - y).shape[0]# 计算梯度def gradient(self, x, y):z = self.forward(x)gradient_w = np.mean((z-y)*x, axis=0)gradient_w = gradient_w[:, np.newaxis] # 由于计算均值后,维度损失掉了,所以需要将损失的维度补足gradient_b = np.mean(z - y)return gradient_w, gradient_b# 更新参数def update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_b# 训练模型(梯度下降)def train(self, train_data, iterations=100, eta=0.01):x = train_data[:, :-1]y = train_data[:, -1:]losses = []for i in range(iterations):z = self.forward(x) #前向计算L = self.loss(z, y) #计算损失gradient_w, gradient_b = self.gradient(x, y) #计算梯度self.update(gradient_w, gradient_b, eta) #更新参数losses.append(L)if (i+1) % 10 == 0:print('iter {}, loss {}'.format(i, L))return losses# 获取数据train_data, test_data = load_data('./work/housing.data')# 创建网络net = Network(13) # 创建带13个参数的网络# 启动训练(梯度下降)losses = net.train(train_data, iterations=1000, eta=0.01)# 画出损失函数的变化趋势plot_x = np.arange(num_iterations)plot_y = np.array(losses)plt.xlabel("num_iterations", fontsize=14)plt.ylabel("loss", fontsize=14)plt.plot(plot_x, plot_y)plt.show()
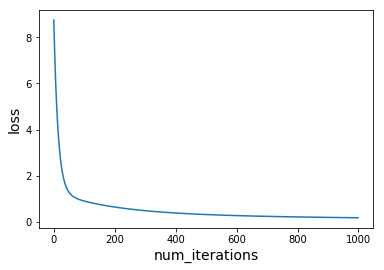
训练输出:
iter 9, loss 5.143394325795511iter 19, loss 3.097924194225988iter 29, loss 2.082241020617026iter 39, loss 1.5673801618157397iter 49, loss 1.2966204735077431iter 59, loss 1.1453399043319765iter 69, loss 1.0530155717435201iter 79, loss 0.9902292156463155iter 89, loss 0.9426576903842504iter 99, loss 0.9033048096880774...iter 889, loss 0.19304908885621125iter 899, loss 0.1912555092527351iter 909, loss 0.1894982936296714iter 919, loss 0.18777618462820625iter 929, loss 0.18608798277314595iter 939, loss 0.18443254350353405iter 949, loss 0.18280877436103968iter 959, loss 0.18121563232764165iter 969, loss 0.17965212130459232iter 979, loss 0.1781172897250724iter 989, loss 0.1766102282933619iter 999, loss 0.17513006784373505
关于更新参数的说明
为了确定损失函数更小的点,更新参数时需要做以下操作:
def update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_b
- 相减:参数需要向梯度的反方向移动,即斜率更小的反向。
- eta:控制每次参数值沿着梯度反方向变动的大小,即每次移动的步长,又称为学习率。
随机梯度下降
# 导入需要用到的packageimport numpy as npimport json# 使用matplotlib将两个变量和对应的Loss作3D图import matplotlib.pyplot as plt%matplotlib inline# 从文件导入数据def load_data(datafile):data = np.fromfile(datafile, sep=' ')# 每条数据包括14项,其中前面13项是影响因素,第14项是相应的房屋价格中位数feature_names = [ 'CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', \'DIS', 'RAD', 'TAX', 'PTRATIO', 'B', 'LSTAT', 'MEDV' ]feature_num = len(feature_names)# 将原始数据进行Reshape,变成[N, 14]这样的形状data = data.reshape([data.shape[0] // feature_num, feature_num])# 将原数据集拆分成训练集和测试集# 这里使用80%的数据做训练,20%的数据做测试# 测试集和训练集必须是没有交集的ratio = 0.8offset = int(data.shape[0] * ratio)training_data = data[:offset]# 计算训练集的最大值,最小值,平均值maximums = training_data.max(axis=0) # 指定 axis=0 计算每列的最大值minimums = training_data.min(axis=0) # 指定 axis=0 计算每列的最小值avgs = training_data.mean(axis=0) # 指定 axis=0 计算每列的平均值# 对数据进行归一化处理for i in range(feature_num):data[:, i] = (data[:, i] - minimums[i]) / (maximums[i] - minimums[i])# 训练集和测试集的划分比例training_data = data[:offset]test_data = data[offset:]return training_data, test_dataclass Network(object):def __init__(self, num_of_weights):# 随机产生w的初始值# 为了保持程序每次运行结果的一致性,此处设置固定的随机数种子np.random.seed(0)self.w = np.random.randn(num_of_weights, 1)self.b = 0.# 前向计算def forward(self, x):return np.dot(x, self.w) + self.b# 计算损失值,使用均方误差def loss(self, z, y):return np.sum((z - y) ** 2) / (z - y).shape[0]# 计算梯度def gradient(self, x, y):z = self.forward(x)gradient_w = np.mean((z-y)*x, axis=0)gradient_w = gradient_w[:, np.newaxis] # 由于计算均值后,维度损失掉了,所以需要将损失的维度补足gradient_b = np.mean(z - y)return gradient_w, gradient_b# 更新参数def update(self, gradient_w, gradient_b, eta = 0.01):self.w = self.w - eta * gradient_wself.b = self.b - eta * gradient_b# 训练模型(随机梯度下降)def train(self, training_data, num_epoches, batch_size=10, eta=0.01):n = len(training_data)losses = []for epoch_id in range(num_epoches):# 在每轮迭代开始之前,将训练数据的顺序随机打乱# 然后再按每次取batch_size条数据的方式取出np.random.shuffle(training_data)# 将训练数据进行拆分,每个mini_batch包含batch_size条的数据mini_batches = [training_data[k:k+batch_size] for k in range(0, n, batch_size)]for iter_id, mini_batch in enumerate(mini_batches):#print(self.w.shape)#print(self.b)x = mini_batch[:, :-1]y = mini_batch[:, -1:]a = self.forward(x) # 前向计算loss = self.loss(a, y) # 计算损失gradient_w, gradient_b = self.gradient(x, y) # 计算梯度self.update(gradient_w, gradient_b, eta) # 更新参数losses.append(loss)print('Epoch {:3d} / iter {:3d}, loss = {:.4f}'.format(epoch_id, iter_id, loss))return losses# 获取数据train_data, test_data = load_data('./work/housing.data')# 创建网络net = Network(13) # 创建带13个参数的网络# 启动训练(随机梯度下降)losses = net.train(train_data, num_epoches=50, batch_size=100, eta=0.1) # 随机梯度下降# 画出损失函数的变化趋势plot_x = np.arange(len(losses))plot_y = np.array(losses)plt.plot(plot_x, plot_y)plt.show()
训练输出:
Epoch 0 / iter 0, loss = 10.1354Epoch 0 / iter 1, loss = 3.8290Epoch 0 / iter 2, loss = 1.9208Epoch 0 / iter 3, loss = 1.7740Epoch 0 / iter 4, loss = 0.3366Epoch 1 / iter 0, loss = 1.6275Epoch 1 / iter 1, loss = 0.9842Epoch 1 / iter 2, loss = 0.9121Epoch 1 / iter 3, loss = 0.9971Epoch 1 / iter 4, loss = 0.6071Epoch 2 / iter 0, loss = 0.7689Epoch 2 / iter 1, loss = 0.8547Epoch 2 / iter 2, loss = 0.9428Epoch 2 / iter 3, loss = 0.9791Epoch 2 / iter 4, loss = 0.4608...Epoch 47 / iter 0, loss = 0.0896Epoch 47 / iter 1, loss = 0.0863Epoch 47 / iter 2, loss = 0.0933Epoch 47 / iter 3, loss = 0.0753Epoch 47 / iter 4, loss = 0.0106Epoch 48 / iter 0, loss = 0.0644Epoch 48 / iter 1, loss = 0.1005Epoch 48 / iter 2, loss = 0.0685Epoch 48 / iter 3, loss = 0.0836Epoch 48 / iter 4, loss = 0.1913Epoch 49 / iter 0, loss = 0.0898Epoch 49 / iter 1, loss = 0.0617Epoch 49 / iter 2, loss = 0.0771Epoch 49 / iter 3, loss = 0.0891Epoch 49 / iter 4, loss = 0.0369
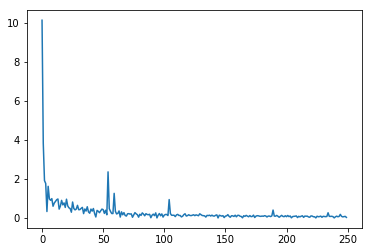
可以看出,跟普通梯度下降相比,随机梯度下降加快了训练过程,但由于每次仅基于少量样本更新参数和计算损失,所以损失下降曲线会出现震荡。

若有收获,就点个赞吧
0 人点赞
