DataFrame是一个表格型的数据结构,类似于Excel或sql表,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔值等)。
DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共用同一个索引)
DataFrame的创建
用多维数组字典、列表字典生成 DataFrame:
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],'year': [2000, 2001, 2002, 2001, 2002],'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}frame = pd.DataFrame(data)print(frame)
输出:
state year pop0 Ohio 2000 1.51 Ohio 2001 1.72 Ohio 2002 3.63 Nevada 2001 2.44 Nevada 2002 2.9
指定行的名称
通过index指定每一行的名称:
frame = pd.DataFrame(data, index=['one', 'two', 'three', 'four', 'five'])print(frame)
输出:
state year popone Ohio 2000 1.5two Ohio 2001 1.7three Ohio 2002 3.6four Nevada 2001 2.4five Nevada 2002 2.9
:::warning 注意:行的数量应与创建的frame对应,否则会报错。 :::
指定列的排序
如果指定了列顺序,则DataFrame的列就会按照指定顺序进行排列
data = {'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada'],'year': [2000, 2001, 2002, 2001, 2002],'pop': [1.5, 1.7, 3.6, 2.4, 2.9]}frame = pd.DataFrame(data, columns=['year', 'state', 'pop'])print(frame)
输出:
year state pop0 2000 Ohio 1.51 2001 Ohio 1.72 2002 Ohio 3.63 2001 Nevada 2.44 2002 Nevada 2.9
跟原Series一样,如果传入的列在数据中找不到,就会产生NAN值
frame = pd.DataFrame(data, columns=['year', 'state', 'pop', 'debt'], index=['one', 'two', 'three', 'four', 'five'])print(frame)
输出:
year state pop debtone 2000 Ohio 1.5 NaNtwo 2001 Ohio 1.7 NaNthree 2002 Ohio 3.6 NaNfour 2001 Nevada 2.4 NaNfive 2002 Nevada 2.9 NaN
用 Series 生成 DataFrame
可以通过Series生成DataFrame,同样地,如果数据对应不上,则产生NaN值
d = {'one': pd.Series([1., 2., 3.], index=['a', 'b', 'c']),'two': pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}print(pd.DataFrame(d))
输出:
one twoa 1.0 1.0b 2.0 2.0c 3.0 3.0d NaN 4.0
DataFrame的获取
通过类似字典标记的方式或属性的方式,可以将DataFrame的列获取为一个Series,返回的Series拥有原DataFrame相同的索引
frame = pd.DataFrame(data, columns=['year', 'state', 'pop'], index=['one', 'two', 'three', 'four', 'five'])print(frame['state'])
输出:
one Ohiotwo Ohiothree Ohiofour Nevadafive NevadaName: state, dtype: object
通过数组赋值
通过np.arange()可以为每个元素赋值
frame['debt'] = np.arange(5.)print(frame)
输出
year state pop debt newone 2000 Ohio 1.5 0.0 24.75two 2001 Ohio 1.7 1.0 28.05three 2002 Ohio 3.6 2.0 59.40four 2001 Nevada 2.4 3.0 39.60five 2002 Nevada 2.9 4.0 47.85
或者直接通过数组为每个元素赋值:
frame['debt'] = [1,2,3,4,5]print(frame)
输出:
year state pop debtone 2000 Ohio 1.5 1two 2001 Ohio 1.7 2three 2002 Ohio 3.6 3four 2001 Nevada 2.4 4five 2002 Nevada 2.9 5
DataFrame的修改
列可以通过赋值的方式进行修改,例如,给那个空的“delt”列赋上一个标量值或一组值
frame['debt'] = 16.5print(frame)
输出:
year state pop debtone 2000 Ohio 1.5 16.5two 2001 Ohio 1.7 16.5three 2002 Ohio 3.6 16.5four 2001 Nevada 2.4 16.5five 2002 Nevada 2.9 16.5
同样地,也可以创建一个新的列:
frame['new'] = frame2['debt' ]* frame2['pop']print(frame)
输出:
year state pop debt newone 2000 Ohio 1.5 16.5 24.75two 2001 Ohio 1.7 16.5 28.05three 2002 Ohio 3.6 16.5 59.40four 2001 Nevada 2.4 16.5 39.60five 2002 Nevada 2.9 16.5 47.85
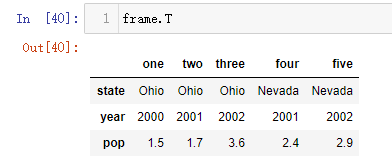
DataFrame的转置
使用T可以获取到DataFrame的转置
frame.T
转化为numpy
通过to_numpy将DataFrame转化为numpy,举例:
frame.to_numpy()
array([[2000, 'Ohio', 1.5, 1],[2001, 'Ohio', 1.7, 2],[2002, 'Ohio', 3.6, 3],[2001, 'Nevada', 2.4, 4],[2002, 'Nevada', 2.9, 5]], dtype=object)
:::info DataFrame.to_numpy() 的输出不包含行索引和列标签。 :::

若有收获,就点个赞吧
0 人点赞
