示例:经典的MNIST手写数字分类任务
关于MNIST数据集
手写字体MNIST数据集下载: THE MNIST DATABASE of handwritten digits
可以看到包括以下数据:
train-images-idx3-ubyte.gz: training set images (9912422 bytes)
train-labels-idx1-ubyte.gz: training set labels (28881 bytes)
t10k-images-idx3-ubyte.gz: test set images (1648877 bytes)
t10k-labels-idx1-ubyte.gz: test set labels (4542 bytes)
其中,训练数据包括60,000条,测试数据包括10,000条。每个数据包括一个28*28=784的图像数组和标签,获取MNIST数据集的代码如下:
import numpy as npimport matplotlib.pyplot as pltreader = paddle.dataset.mnist.train()for image in reader():image = np.array(image)print(image[0].shape) # 数据内容 的形状为 28*28=784 的图像数组print(image[1]) # 标签# 获取第一张图片并显示first_image = image[0].reshape(28, 28)plt.imshow(first_image)break

关于获取MNIST数据集的方法 paddle.dataset.mnist 参见:https://www.paddlepaddle.org.cn/documentation/docs/zh/api_cn/data_cn/dataset_cn/mnist_cn.html
常规方式
以下示例,通过手动创建变量,定义网络的每个层,达到训练模型的目的:
import paddlefrom paddle import fluidfrom functools import reduceimport matplotlib.pyplot as pltimport numpy as np# 定义输入的形状images = fluid.layers.data(name="pixel", shape=[1, 28, 28], dtype='float32')label = fluid.layers.data(name="label", shape=[1], dtype='int64')# 定义层conv_pool_1 = fluid.nets.simple_img_conv_pool(input=images, filter_size=5, num_filters=20, pool_size=2, pool_stride=2, act="relu")conv_pool_2 = fluid.nets.simple_img_conv_pool(input=conv_pool_1, filter_size=5, num_filters=50, pool_size=2, pool_stride=2, act="relu")SIZE = 10input_shape = conv_pool_2.shapeparam_shape = [reduce(lambda a, b: a * b, input_shape[1:], 1)] + [SIZE]scale = (2.0 / (param_shape[0] ** 2 * SIZE)) ** 0.5predict = fluid.layers.fc(input=conv_pool_2, size=SIZE, act="softmax", param_attr=fluid.param_attr.ParamAttr(initializer=fluid.initializer.NormalInitializer(loc=0.0, scale=scale)))# 损失函数及优化函数cost = fluid.layers.cross_entropy(input=predict, label=label)avg_cost = fluid.layers.mean(x=cost)opt = fluid.optimizer.AdamOptimizer(learning_rate=0.001, beta1=0.9, beta2=0.999)opt.minimize(avg_cost)# 加载数据reader = paddle.dataset.mnist.train()batched_reader = paddle.batch(reader, batch_size=200)# 执行器place = fluid.CPUPlace()exe = fluid.Executor(place)feeder = fluid.DataFeeder(feed_list=[images, label], place=place)exe.run(fluid.default_startup_program())# 开始训练losses = []for data in batched_reader():loss = exe.run(feed=feeder.feed(data), fetch_list=[avg_cost])losses.append(loss)print(loss)# 绘制损失值图像losses = np.array(losses)plt.plot(losses.flatten())
由于数据量巨大,而我是使用CPU进行的训练,足足训练了6min,输出结果:
运行时长: 6分32秒289毫秒
[array([2.3050933], dtype=float32)][array([2.1798933], dtype=float32)][array([2.041367], dtype=float32)][array([1.8695843], dtype=float32)][array([1.7091033], dtype=float32)][array([1.5944638], dtype=float32)][array([1.3899304], dtype=float32)][array([1.2142174], dtype=float32)][array([0.93150413], dtype=float32)][array([0.92134124], dtype=float32)]......[array([0.02884364], dtype=float32)][array([0.04368482], dtype=float32)][array([0.02136619], dtype=float32)][array([0.03527835], dtype=float32)][array([0.01867639], dtype=float32)][array([0.05465743], dtype=float32)][array([0.00479105], dtype=float32)][array([0.1301369], dtype=float32)][array([0.04957756], dtype=float32)][array([0.25675547], dtype=float32)][array([0.13143504], dtype=float32)]
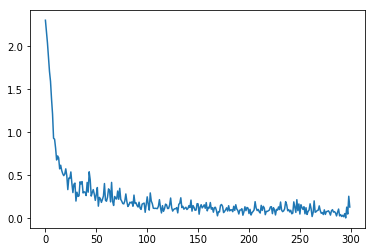
网络模型
我们将其封装为网络模型,并将模型保存,方便调用:
import paddlefrom paddle import fluidfrom paddle.fluid.dygraph.nn import Conv2D, Pool2D, Linearimport matplotlib.pyplot as pltimport numpy as npimport jsonimport gzipimport random# 定义数据集读取器def load_data(mode='train'):# 读取本地数据文件datafile = './work/mnist.json.gz'print('loading mnist dataset from {} ......'.format(datafile))data = json.load(gzip.open(datafile))# 读取数据集中的训练集,验证集和测试集train_set, val_set, eval_set = data# 数据集相关参数,图片高度IMG_ROWS, 图片宽度IMG_COLSIMG_ROWS = 28IMG_COLS = 28# 根据输入mode参数决定使用训练集,验证集还是测试if mode == 'train':imgs = train_set[0]labels = train_set[1]elif mode == 'valid':imgs = val_set[0]labels = val_set[1]elif mode == 'eval':imgs = eval_set[0]labels = eval_set[1]# 验证图像数量和标签数量是否一致assert len(imgs) == len(labels), "length of train_imgs({}) should be the same as train_labels({})".format(len(imgs), len(labels))index_list = list(range(len(imgs)))# 读入数据时用到的batchsizeBATCHSIZE = 100# 定义数据生成器def data_generator():# 训练模式下,打乱训练数据if mode == 'train':random.shuffle(index_list)# 每个batch中包含的数据imgs_list = []labels_list = []# 按照索引读取数据for i in index_list:# 读取图像和标签,转换其尺寸和类型img = np.reshape(imgs[i], [1, IMG_ROWS, IMG_COLS]).astype('float32')label = np.reshape(labels[i], [1]).astype('int64')imgs_list.append(img)labels_list.append(label)# 如果当前数据缓存达到了batch size,就返回一个批次数据if len(imgs_list) == BATCHSIZE:yield np.array(imgs_list), np.array(labels_list)# 清空数据缓存列表imgs_list = []labels_list = []# 如果剩余数据的数目小于BATCHSIZE,# 则剩余数据一起构成一个大小为len(imgs_list)的mini-batchif len(imgs_list) > 0:yield np.array(imgs_list), np.array(labels_list)return data_generator# 定义模型结构class MNIST(fluid.dygraph.Layer):def __init__(self):super(MNIST, self).__init__()# 定义一个卷积层,输出通道20,卷积核大小为5,步长为1,padding为2,使用relu激活函数self.conv1 = Conv2D(num_channels=1, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')# 定义一个池化层,池化核为2,步长为2,使用最大池化方式self.pool1 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')# 定义一个卷积层,输出通道20,卷积核大小为5,步长为1,padding为2,使用relu激活函数self.conv2 = Conv2D(num_channels=20, num_filters=20, filter_size=5, stride=1, padding=2, act='relu')# 定义一个池化层,池化核为2,步长为2,使用最大池化方式self.pool2 = Pool2D(pool_size=2, pool_stride=2, pool_type='max')# 定义一个全连接层,输出节点数为10self.fc = Linear(input_dim=980, output_dim=10, act='softmax')# 定义网络的前向计算过程def forward(self, inputs):x = self.conv1(inputs)x = self.pool1(x)x = self.conv2(x)x = self.pool2(x)x = fluid.layers.reshape(x, [x.shape[0], -1])x = self.fc(x)return x# 配置在CPU还是GPU上训练use_gpu = Falseplace = fluid.CUDAPlace(0) if use_gpu else fluid.CPUPlace()# 训练配置with fluid.dygraph.guard(place):model = MNIST()model.train()# 加载数据train_loader = load_data('train')# 异步读取数据# 定义DataLoader对象用于加载Python生成器产生的数据data_loader = fluid.io.DataLoader.from_generator(capacity=5, return_list=True)# 设置数据生成器data_loader.set_batch_generator(train_loader, places=place)#设置学习率optimizer = fluid.optimizer.AdamOptimizer(learning_rate=0.01, parameter_list=model.parameters())# 定义一个损失值数组,用于在图像中直观展示losses = np.array([])# 设置训练次数EPOCH_NUM = 5# 开始训练for epoch_id in range(EPOCH_NUM):for batch_id, data in enumerate(train_loader()):#准备数据,变得更加简洁image_data, label_data = dataimage = fluid.dygraph.to_variable(image_data)label = fluid.dygraph.to_variable(label_data)#前向计算的过程predict = model(image)#计算损失,取一个批次样本损失的平均值loss = fluid.layers.cross_entropy(predict, label)avg_loss = fluid.layers.mean(loss)#每训练了100批次的数据,打印下当前Loss的情况if batch_id % 200 == 0:print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))losses = np.append(losses, avg_loss.numpy())#后向传播,更新参数的过程avg_loss.backward()optimizer.minimize(avg_loss)model.clear_gradients()#保存模型参数fluid.save_dygraph(model.state_dict(), 'mnist')# 绘制损失plt.plot(losses)
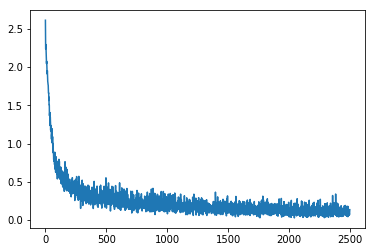
关于训练过程的说明:
- 内层循环: 负责整个数据集的一次遍历,采用分批次方式(batch)。假设数据集样本数量为1000,一个批次有10个样本,则遍历一次数据集的批次数量是1000/10=100,即内层循环需要执行100次。
- 外层循环: 定义遍历数据集的次数,通过参数EPOCH_NUM设置。

若有收获,就点个赞吧
0 人点赞
